Fedora is awesome, because it not only breaks gdb and strace in the default install, it even advertises it as a feature. I wonder if this is enough as a proof that Fedora security people have no clue about security?
Why Fedora is awesome
April 7th, 2012 — General
GTK 3.6?
April 2nd, 2012 — General
This CSS:
@import url("/usr/share/themes/Adwaita/gtk-3.0/gtk-main.css")
* {
transition-property: color, background-color, background-image;
transition-duration: 0.5s;
}
gives me this:

Now I just need to merge the code and Lapo will be busy for the next cycle.
Google is killing Free Software
February 1st, 2012 — General
Now that I got your attention with the catchy title, lemme rephrase that in a somewhat longer sentence:
Google is the greatest danger to the Free Software movement at the current time.
I’m not sure I should presume intent because of Hanlon’s razor, but a lot of smart people concerned about Free Software work at Google, so they should at least be aware of it.
The first problem I have with Google is that they are actively working on making the world of Free Software a worse place. The best example for this is Native Client. It’s essentially a tool that allows building web pages without submitting anything even resembling source code to the client. And thereby it’s killing the “View Source” option. (You could easily build such a tool as Free Software if instead of transmitting the binary, you’d transmit the source code. Compare HTML with Flash here.)
The second problem I have with Google is that what they do actively confuses people about Free Software. Google likes to portray itself as an Open Source company and managed to accumulate a lot of geek cred that way (compared to Apple, Amazon or Microsoft). But unfortunately, a lot of people get introduced to Open Source and Free Software via Google. And withholding source code for a while, shipping source code to something similar are close enough to confuse unsuspecting bystanders. And I fear that behavior is doing more harm than good to Free Software.
All that said, I don’t think Google is stupid, illegal or even illogical in what they do. Everything they do makes sense. All I’m saying is that they’re scumbags and you should be aware of that.
Don’t feed the trolls
October 28th, 2011 — General
As Mr. Keuner, the thinking man, was speaking out against Power in front of a large audience in a hall, he noticed the people in front of him shrinking back and leaving. He looked round and saw standing behind him – Power.
»What are you saying?« Power asked him.
»I was speaking out in favor of Power,« replied Mr. Keuner.
After Mr. Keuner had left the hall, his students inquired about his backbone. Mr. Keuner replied: »I don’t have a backbone to be broken. I’m the one who has to live longer than Power.«
And Mr. Keuner told the following story:
One day, during the period of illegality, an agent entered the apartment of Mr. Eggers, a man who had learned to say no. The agent showed a document, which was made out in the name of those who ruled the city, and which stated that any apartment in which he set foot belonged to him; likewise, any food that he demanded belonged to him; likewise, any man whom he saw, had to serve him.
The agent sat down in a chair, demanded food, washed, lay down in bed, and, before he fell asleep, asked, with his face to the wall: »Will you be my servant?«
Mr. Eggers covered the agent with a blanket, drove away the flies, watched over his sleep, and, as he had done on this day, obeyed him for seven years. But whatever he did for him, one thing Mr. Eggers was very careful not to do: that was, to say a single word. Now, when the seven years had passed and the agent had grown fat from all the eating, sleeping, and giving orders, he died. Then Mr. Eggers wrapped him in the ruined blanket, dragged him out of the house, washed the bed, whitewashed the walls, drew a deep breath and replied: »No.«
A sunny day in Istanbul
October 18th, 2011 — General
I remember this event quite vividly. I have no idea why I do remember it so well, but I think it involves me having been a fan of Owen for a long time and this being the first time I had a long discussion with him. Or it was the heat. Or maybe the high walls around the president’s palace in Istanbul.
it was in July of 2008 when a bunch of us were walking back to the tram from a long day at GUADEC. It was a few months after we had had the GTK hackfest in Berlin where people had discussed improving the toolkit situation of the aging GTK – at version 2.12 at that time. Owen, me and a few others were arguing 2 very different solutions to the problem. No consensus existed on which solution was best. Owen’s idea was to let GTK die. Keep it in maintenance mode and don’t do any updates. Instead, spend time on a new toolkit and do things the right way there. Of course, you would take the things from GTK that worked, but you’d be careful there to not repeat the bad mistakes. Others claimed it was a better idea to try and overhaul GTK, add the new capabilities people needed and try to get the behemoth moving again.
There was a lot of arguments on both sides. Starting over would attract new contributors, a large, mature and intertwined codebase would likely be less successful in doing that. Keeping the existing code would ensure a full-featured toolkit while a new toolkit would need to write lots of code to acquire the same features. New code can experiment with fundamentally different designs a lot easier than a large codebase. People would have a lot of assumptions about what something called “GTK” would do – both good and bad – while a new toolkit would be free from expectations. An open question was if developers would prefer a one-time pain when porting to a new toolkit over a need to work on incremental updates again and again.
Why am I writing about this now? It came back to my mind while thinking about the toolkit situation in GNOME 3. We have MX and we have GTK 3, so in a true open source way people tried both approaches. And it seems people were spot on with their arguments, all the advantages of one way over another that people had foreseen turned out right. So I think everybody I listened to that sunny day can rightfully claim to know a lot about toolkit development.
What people didn’t foresee back then and what I think had or will have some influence on how this all turns out are the changes outside of our realm of expertise. New tools – in particular the introduction of git – changed our workflow and what we consider hard or easy to do. A lot of new use cases came up, in particular from mobile devices. And of course the way people develop with toolkits changed, too.
So what solution will be the best one in the end? I suspect I can’t know. I’m biased.
on plane travel
October 8th, 2011 — General
I should finally write this down, as I suspect a lot of people can benefit from it, both for their individual travels and for organizing meetups (hackfests, conferences, whatever).
This is my experience on getting cheap flights to where I want to go when I want to go. So given a rough date, a departure and an arrival airport, find the cheapest and most comfortable way to get there. It also assumes that I’m not a frequent flyer, so those programs – like miles and more – don’t get me enough mileage to make it worthwhile to stick with one airline. I would suspect it’s beneficial once you reach at least 50.000 miles per year. For that you need to travel to different continents and back at least twice a year though.
PREPARATION
Knowing this helps a lot in deciding on which available options to pursue further and which ones are pretty much no-gos from the start.
- Know your airlines
This is pretty much an experience thing and very much dependent on personal preferences, but it’s useful to know which airlines you’d never fly with, not even for free, and for which airlines you’d pay extra to fly with. If you have no idea about a particular airline, I’ve found the Skytrax ranking to be a good first guess. Also, assuming an airline behaves like people of the country it’s based in is a good guess more often than not.I for one care about enough legroom (I’m tall), punctuality, ground staff competent and able to solve problems and free catering on longer flights. I don’t particularly care about on-board entertainment or an attentive crew. So I’m very happy with Lufthansa and Swiss (what I think of as typical German/Swiss punctuality, problem-solving skills and attentiveness) and I dislike all the no-frills airlines. (No, I’m not gonna pay 10€ for a can of Coke. I paid those for my luggage already.)
- Know your airports
While your departure and arrival airport are probably fixed – though in some cases, like London, New York or La Coruna, there’s multiple airports to chose from – Your stopover airports are not. Again, experience is probably the best guide, but there’s also a bunch of easy first guesses. For a start, the security, customs and entry procedures depend on the country the airport is located in and the rules of those countries can be googled. In general, it’s best to stop over in your departure or arrival country – usually you can count the Schengen area as one country – as that avoids VISA messiness into more countries and you can use the same currency to pay for stuff on the airport. I do like to avoid Copenhagen or London for that reason. I also avoid the US and Australia, as they make you pick up your luggage on arrival and even though you can immediately check it back in again after going through Customs, the luggage tends to not make it to your connecting flight way too often.
A second thing that is important is the airport itself. There are airports you can get lost in, because they are done so complicated or their guidance is so poor, there are airports where it takes very long to get from one gate to the next, there are airports that routinely lose your luggage and there are airports that are huge construction sites. And then there are airports with a nice atmosphere, free wireless and relaxing cafes. Googling is the best thing to figure out how long a stopover should take for making the connection (both for the person and the luggage) and if the airport is nice if you have to spend 5+ hours there waiting for your connection flight.
For my personal list of big airports I visited, I do like Lisbon, Dallas, Singapore and Frankfurt and dislike Heathrow, New York Newark, Madrid and Atlanta, particularly Atlanta.
- Know your alternatives
This is not as important on intercontinental flights, but it’s especially useful when going to smaller airports. I’ve found times when there was a direct flight to my destination with a holiday airline from an airport very close or to an airport very close to where I wanted to go. These connections will not be listed anywhere unless you specifically ask about them. So it doesn’t hurt to know which airlines depart from your home and destination airports and where they go to from there. (Hint for hackfests/GUADEC 2012: Vueling often flies to La Coruna from Amsterdam and London.) Heck, even knowing that there’s a direct flight from Hamburg to New York has saved me quite a bit of searching. And that’s a flight that every scheduling system knows about.
FINDING
This is the act of finding all the possible trips, but not necessarily deciding on the exact trip to pick. Usually for me, there are multiple options still available, often a few 100€ apart, when I’m done with this step. But when I’m done with this step, I do have a short list of which airlines to look at closer.
- Figuring out the date
Flights can easily be 2x, sometimes even 5x cheaper if you fly one or a few days later or earlier – even with the same airline and using the exact same route. For intercontinental travel, weekend flights are most expensive, flights on Tuesday to Thursday are cheapest. There can also be big events or holidays in some weeks that make the whole week excessively expensive. While most airline booking mechanisms offer a +/- 3 day view, the only good way I’ve found to figure out all of these things is the Lufthansa Trip Finder, but that of course only works for routes that Lufthansa services. Still, for hackfest planning inside Europe, it might be worthwhile to look at trips from a random German airport to $HACKFEST_LOCATION, if you want to save money. - Figuring out the airline(s)
Once you’re reasonably sure about your trip, you want to go to Amadeus and enter dates and location. Amadeus will then crawl all the offers on the web and give you a list of the cheapest ones. On the results list, you want to work with the options on the left. You can use these to ignore unwanted airlines or too many stopovers. You can even ignore trips that are way too long. This way you will figure out the reasonably cheap airlines. - Scratch “multiple airlines”
One thing you absolutely do want to avoid is “multiple airlines”. You can only book those on cheap flight websites, but not from the airlines themselves. These things usually mean a bunch of separately booked flights. On such trips, if your first flight is late, nobody feels (or is) responsible when you miss your connecting flight. Also, you usually have to pick up your luggage on change of airline. For added fun: Ryanair is happy to screw you over, every flight is a separate trip for them. If you miss a Ryanair flight because your Ryanair flight was late, it’s your fault, not theirs.
Important: Do not confuse this with airline alliances. Those cooperating airlines work together and take care of luggage, missed flights etc.
PICKING
This is the act of deciding between multiple similar options and figuring out which trip will get you to your destination best. Of course, the easiest solution is taking the cheapest flight, but sometimes the difference is just 3€ or there’s some really bad thing about that cheap flight…
- Avoid stopovers
Usually trips with less stops are cheaper, but not always. If I can avoid it, I do not add extra stops. Extra stops cost time, lead to security and Customs hassles, lose luggage and make you miss connection flights. All in all, there’s almost only bad things about it.
- Try to find the shortest trip
Emirates could be a great airline for having only one stopover in Dubai if you go from Europe to southern Asia or Australia, but they usually involve a 8-10 hour stop in Dubai. And long stops in airports make me annoyed, because I can’t do anything but wait. And I’m tired and bored already from the first part of the trip. And food and drinks are suddenly as expensive as on “cheap” flights. Ugh, I hate those times. Even when I have wifi.
- Check the operating airline
Almost all airlines have code-sharing flights with partner airlines, and while your flight may be listed as LH123, it might in fact be operated by Spanair and leave you with no legroom, no free drinks, but a friendly crew. Or the other way. You’ll often also not be able to do online check-in on those and then you can’t pick your seat in advance. So unless you want to end up in the middle seat, always look at the operating airline. That’s the only one that counts.
- Pick for airline and stopover airport
If you didn’t discard bad airlines and airports earlier, you can do so now. Avoid the bad airports and airlines to save yourself some hassle. Oftentimes, in particular in the US, airlines have multiple “hub” airports that they make you stop over, so this isn’t even a rare occurrence (I hear you want to avoid Chicago and Atlanta here). Lufthansa also often lets you chose between Frankfurt and Munich (I don’t much care), and in Spain there’s Madrid vs Barcelona (pick Barcelona).
- Check for a nice departure and arrival time
If you still have multiple options left, check the final departure and arrival times. On conferences I want to arrive during the day so I can meet up with people but depart early to not have a boring day when everyone’s gone. I also like to arrive home so that I can still go shopping for some groceries. And I’d like to avoid flights during the night. There’s usually no public transport to get you to or from the airport and taxis are expensive.
- Book with the airline
I prefer to not book my ticket with a travel agency – online or not – but rather book directly on the airline’s website. They usually match the cheapest price. And it usually gets me some niceties, such as reminder emails – not just “your flight is tomorrow”, but also about required extra information, such as visa details, which often makes things a lot easier. Last but not least, picking the right airline to book with – even if all the airlines are in the same alliance and roughly match the price – can make the difference between an easy solution and a complicated one, once you hit a problem that requires a staff member to solve and you booked with the airline with competent staff.
- Make sure you picked the right flight
Airline websites’ web forms often list a bunch of flights for vastly different prices on the same site when picking. Make sure you picked the right ones. Usually, the cheapest ones are marked, but if you found one that was better and cost only a bit more, be careful if you reload that page to not accidentally hit a wrong one that is vastly more expensive. And no, that definitely never happened to me.
BONUS
These are a bunch of things that are nice to know for when things get a little more complicated than just booking a return trip.
- Different airports for outbound and inbound trip are no problem
I’ve done it 3 times with different airlines so far, and it’s never been a problem, in fact I’m convinced the trips even got slightly cheaper that way. If you want to have a different inbound route from outbound route, do it like this:
Pretend you want to book two return trips and do everything as you’d normally do. But instead of finalizing those booking, leave the pages open, start a new complex booking, and enter the complex route there. Then, when presented with the trip options, pick the cheap ones you figured out in your first two booking attempts. This should give you a price that is almost the average of the two trips. - Different itineraries for you and a friend is no problem
Another thing I often do is arrive in advance/leave later than my girlfriend because we couple our vacations with Free Software conferences. What I do is book two separate trips for each of us, and then talk to the airline in advance so that they can make sure we will be seated together on the part of the trip we share. So far, that has always worked out. (I’m also paranoid of finalizing both bookings at the same time in two different tabs because I know how the booking machinery of airlines works and don’t want the prices to change because of the first of our bookings. More on that in the next point.)
- If you know way in advance about your flight you can save
If you know in advance that you want to go somewhere, it’s usually a good idea to check the flights regularly. Airlines adjust the price according to a prediction algorithm run by their computers. If people book flights, prices go up, if people don’t book flights but the prediction predicted they would, prices can go down. Most airlines adjust prices downwards 3 months/90 days before the flight and some 1 month/30 days, so these are the magic dates to watch.
- There’s no magic time when flights are cheapest
Or at least I haven’t found such a time. I’m often looking at flights for LCA or Plumbers so I can get a cheap one, but from my experience the lowest prices for flights stay roughly the same from the day the flight opens for booking to a few days before departure. The only thing that screws you is when too many people book, and you can of course avoid that by booking earlier.
TL;DR: Plan hackfests from mid-week to mid-week if people are ok with it, you can save real money that way.
California
September 26th, 2011 — General
I’ll be on vacation in California starting next week. So if you are in the Bay Area or Los Angeles and think you should meet me or you feel the urge to talk to a GTK+ developer, drop me a mail. I’d like to meet the people I know from IRC but were never on the same continent with.
In particular, if you’re able to get memy girlfriend onto the Google Campus (she qualifies as an architecture/interior design freak and apparently read too much about the Googleplex), I owe you at least a beer. My secret weapon for that won’t work and I haven’t found a replacement yet.
On Application Startup Time: Why do we have it anyway?
September 13th, 2011 — General
This post started as a reply to Mikkel‘s post about startup times and how people were jumping to conclusions before actually testing anything. But because I’m way too smart to do pointless arguments in blog posts (*cough*), I actually measured things.
Here’s the first benchmark (disclaimer: It’s run on my development system, so a crazy mix of Fedora 15 and hand-compiled stuff including debugging symbols): I launched “time $APPLICATION” from a terminal and immediately held down Ctrl+W or Ctrl+Q to make it quit again. I did a few runs and averaged the numbers in my head. That gave me a pretty good idea of how long these applications roughly take to do a warm start. Here’s the totally unscientific numbers:
| application | real | user | sys |
|---|---|---|---|
| Epiphany | 1.0 | 0.8 | 0.05 |
| Evince | 0.8 | 0.4 | 0.03 |
| GEdit | 0.8 | 0.6 | 0.05 |
| kwrite | 0.7 | 0.3 | 0.05 |
| Totem | 1.0 | 0.7 | 0.05 |
| gnome-terminal | 0.3 | 0.2 | 0.03 |
| konsole | 0.3 | 0.1 | 0.04 |
| Gimp | 3.4 | 2.7 | 0.20 |
| Evolution | 3.3 | 2.5 | 0.30 |
| Gnumeric | 0.7 | 0.4 | 0.02 |
| oocalc | 1.0 | 0.6 | 0.15 |
| Firefox | 1.8 | 1.4 | 0.20 |
Now I also wanted to do a cold start, so I ran all of the applications again, but ran “sudo sysctl vm.drop_caches=3” before every run, so I was sure the start really was cold. For KDE applications, I did 2 runs, one with kdelauncher already running, one without. And I only did it once, because it takes so long. Here’s the numbers again:
| application | real | user | sys |
|---|---|---|---|
| Epiphany | 9.4 | 0.8 | 0.15 |
| Evince | 6.4 | 0.4 | 0.10 |
| GEdit | 8.3 | 0.7 | 0.10 |
| kwrite | 13.1 | 0.3 | 0.20 |
| 9.4 | 0.3 | 0.15 | |
| Totem | 7.6 | 0.5 | 0.10 |
| gnome-terminal | 6.5 | 0.2 | 0.10 |
| konsole | 12.3 | 0.2 | 0.15 |
| 8.5 | 0.2 | 0.15 | |
| Gimp | 13.0 | 2.8 | 0.35 |
| Evolution | 19.6 | 2.6 | 0.45 |
| Gnumeric | 7.1 | 0.4 | 0.20 |
| oocalc | 15.2 | 0.7 | 0.30 |
| Firefox | 13.0 | 1.5 | 0.25 |
Yuck.
While that looks really bad, it probably is not as bad as it looks in the real world, because a bunch of applications are already running and a bunch of stuff is already being cached. So here’s another benchmark. This time I ran “sudo sysctl vm.drop_caches=3 && gnome-control-center” before every run, so that the GNOME libs were already loaded, and only application-specific things had to be loaded. More numbers:
| application | real | user | sys |
|---|---|---|---|
| Epiphany | 4.6 | 0.8 | 0.10 |
| Evince | 1.8 | 0.4 | 0.05 |
| GEdit | 4.4 | 0.6 | 0.10 |
| kwrite | 6.3 | 0.3 | 0.10 |
| Totem | 2.7 | 0.5 | 0.05 |
| gnome-terminal | 1.3 | 0.2 | 0.05 |
| konsole | 5.1 | 0.1 | 0.10 |
| Gimp | 9.2 | 2.8 | 0.30 |
| Evolution | 13.4 | 2.6 | 0.40 |
| Gnumeric | 3.5 | 0.4 | 0.05 |
| oocalc | 11.6 | 0.6 | 0.25 |
| Firefox | 9.1 | 1.4 | 0.25 |
Hrm. So what now? It seems there’s a few things one can learn from this.
- It looks like every application is able to start in 1 second or less, unless it does a lot of things that it probably shouldn’t do. Or said differently: If your application takes more than 1s to start up, it is slower than Libreoffice.
- Evolution and Gimp are really slow. They spend almost 3s calculating stuff. I suppose somebody should take a good look at what they do during startup.
- GNOME applications are really fast at starting up in a GNOME environment. (Epiphany seems to spend too much time initializing the disk cache, not sure what GEdit is doing, but probably loading plugins (and Python?))
- GNOME running gives a huge boost to startup times for all applications (seems to be pretty consistent at 4s-5s).
- Cold start of C++ applications seems to be really slow.
- It is never the kernel spending too much CPU.
- I cannot guess which of Ctrl+W and Ctrl+Q actually closes an app.
- gnome-control-center is the only application I found that responds to neither Ctrl+W nor Ctrl+Q (which is why I used it for repopulating the cache and didn’t benchmark it).
Now how can we make startup even faster? I know it has to involve I/O, but I don’t know what I/O is really hurting here. It could be anything from loading lots of libraries to loading icons to dconf to extensive D-BUS activations that is to blame here. I suppose that requires smarter benchmarking processes. But it’s certainly not stabbing in the dark. Or blaming building the widget tree, parsing files, complex data models or in fact any code that is run at startup. And I’m pretty sure the solution doesn’t involve copying ugly solutions from handhelds, because we’re really not that far away from a fast startup.
reftests
May 5th, 2011 — General
Yay, GTK has reftests. Finally it’s as easy to write tests as it should be. (Actually, it should be even easier, but I think it’s bearable now.) What are reftests? Robert O’Callahan has an explanation. Why are there reftests? My post to the GTK mailing list has the motivation. How do they work in GTK? The commit message explains it in detail. The only question that remains: How are people actually supposed to write reftests?
While I was looking for an easy-to-demonstrate example for this case, I came across this on IRC:
<kklimonda> hmm, why can’t I center horizontally a GtkLabel that wraps its text? There is no problem alligning it vertically
This looked like a perfect way to write a reftest and to actually fix the problem.
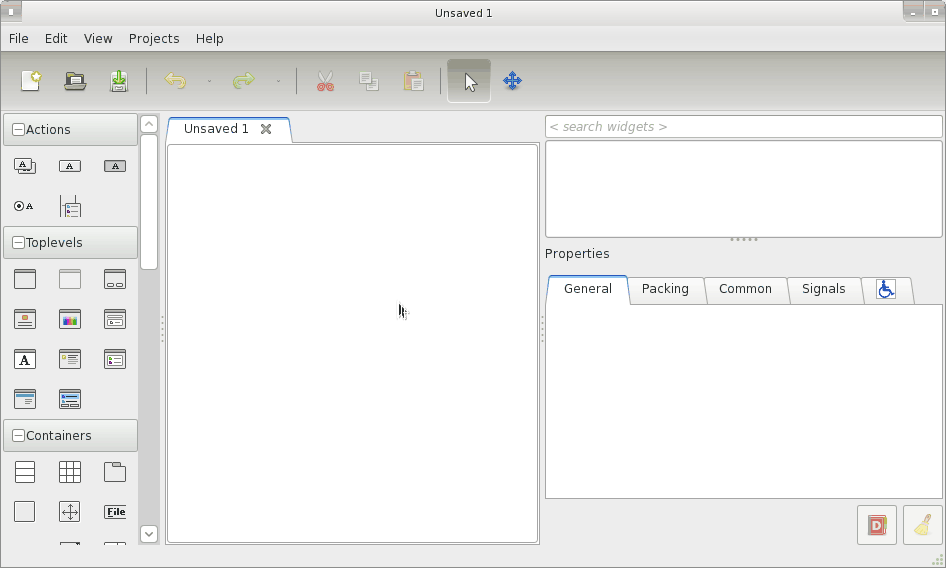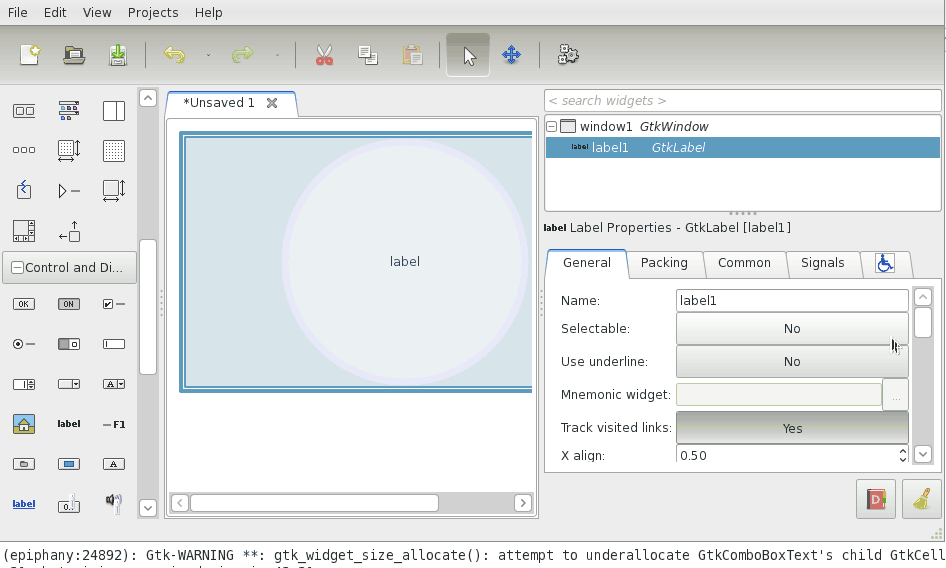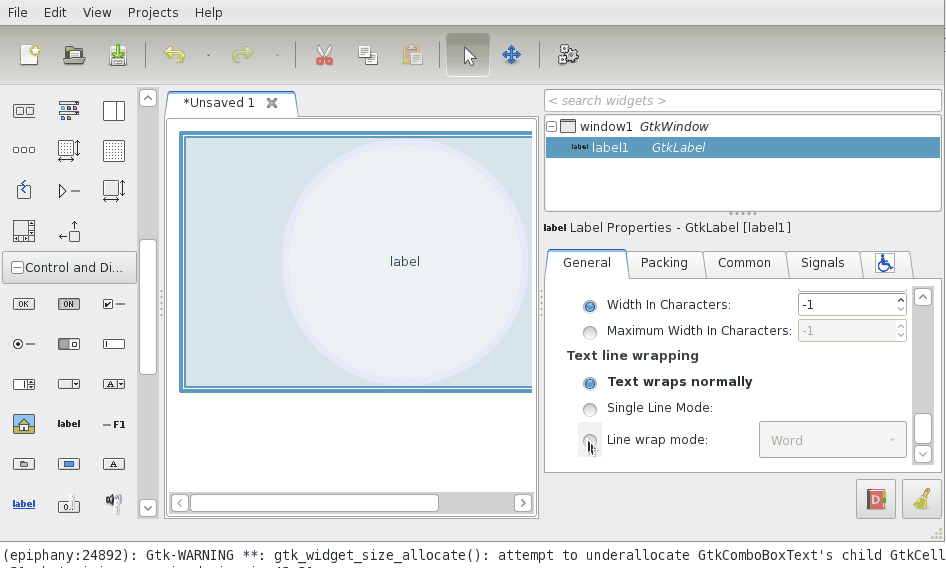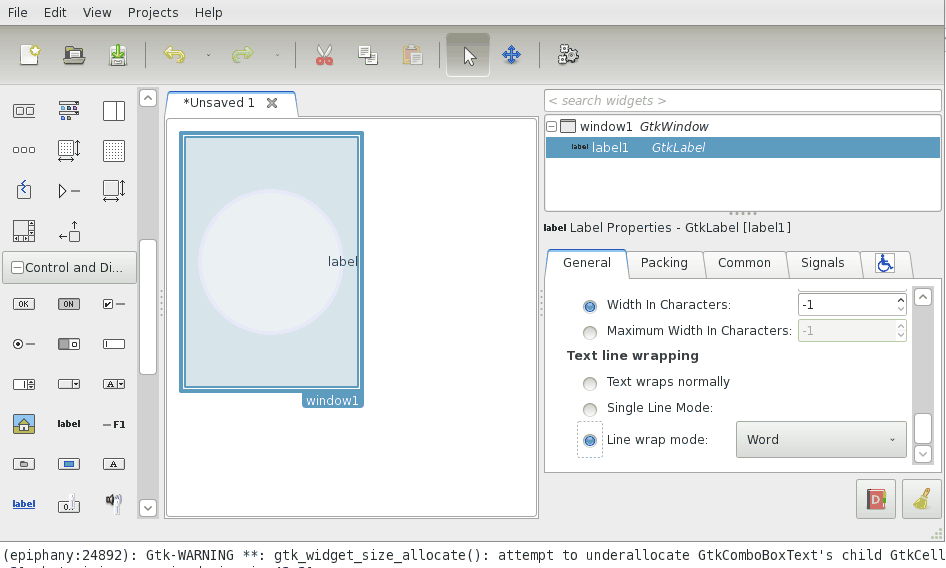
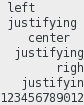
Verify the bug
First I had to make sure there actually is a bug. So what I did was open Glade and do a little test. I created a window, added a label, set it to wrap and center and resized the window. Lo and behold, the text was not centered at all:
Create the test case
Ok, so this is broken. Probably right justified is broken, too, so let’s create a test case. I want to actually use multiline text, because I want to see that GtkLabel makes Pango correctly justify the text. This will make the test a bit more complex. Here we go:
A bunch of things I had to think about while writing the test (which you will notice looks broken, as it should):
- I made the window a popup window. That way the test runner can run faster, as the window manager doesn’t need to be kept in the loop. Always use popup windows, unless you must use a normal window to reproduce a bug.
- I used GtkGrid as the container. GtkGrid is the container for future Gtk. Box and table are on their way out.
- It’s not necessary for the label to actually wrap to show this bug. It just needs to be set to wrapping. And it makes writing the reference test a lot easier.
- I used Monospace text. This is to make writing the reference easier.
- I added a fourth label to increase the width of the window. This is necessary, because the test runner will use a window’s default size. The size you use for the window in Glade has nothing to do with the final size.
I can now throw the test runner at the problem by running (in the toplevel GTK directory) tests/reftests/gtk-reftest reftest.ui. This will fail because there is no reference image to compare it to, but it will already create a rendering in /tmp/reftest.out.png:
Create the reference file
Ok, now to create the reference file from the bug-showing Glade file. The rendering of the reference should look pixel-perfect exactly as we’d expect the correctly justified label to look, but without actually running into the bug. This is where the monospaced font comes in to help – I can use it to align the text with spaces, but keep it left-justified.
Now I have a reference file. If I now run tests/reftests/gtk-reftest reftest.ui again, I’ll get 3 files in the temp directory, the rendering from the test as reftest.out.png, the rendering from the reference as reftest.ref.png and, if those two files differ, the differences between the two as reftest.diff.png. In this case they look like this:


As you can see, the difference file is highlighting where the two renderings differ to make it easy for us to find what needs to be fixed.
Done
That’s a full testcase. Now it just needs to be moved to the test directories, be properly named, get added to Makefile.am and committed. Of course, a lot more complex test cases are possible, and it’s possible to use custom CSS to achieve certain visual effects.
Keep in mind that a test should not just look identical to the reference on your current setup and your computer, but also on computers with different fonts, different settings and a different theme. That makes the test independent of a lot of GTK internals and allows us to change around other parts of the code without breaking this test. And that is awesome.
Oh, and of course after all this work, one thing still remains: the bugfix. Verifying that the fix actually works is incredibly easy now compared to olden times. Where one had to restart the application reproducing the bug, possibly properly LD_PRELOAD’ing libgtk and navigate to where the bug was visible, now it’s just a simple tests/reftests/gtk-reftest reftest.ui. Couldn’t be easier. And after every run, one can check the images to see what is still wrong. Until it finally says “OK”.
And if you’re not a GTK developer
If you’re not a GTK developer and don’t have the testsuite handy, you can still help a lot in getting your bugs fixed. Because as you saw above, most bugs are visible in Glade. And Glade is available on your computer. So you can just use it to produce a file that reproduces the bug. And if you’re really nice to us, you’ll even create a reference file. And then we can just add it to the GTK testsuite and fix it. And then you will know that this bug will never come back, because the testsuite will make sure it doesn’t.
Of course, this test runner only works for rendering bugs, so there is still no easy way to check event emissions, API functionality, reactions to keyboard and mouse input and so forth. But that was not the goal of this test runner. And I’m sure that if this test runner is successful, we will write a lot more test runners for a lot more use cases.
the book was better
March 30th, 2011 — General
Here is a cute video of a benchmark I’ve been looking at in recent times. It’s nice because it not only shows the performance improvements, but also the themeing fixes that were applied. The benchmark shows glade starting up and loading a huge glade file with 4 different GTK versions. It starts with executing glade on the command line and ends with the app quitting when it’s done loading. The 4 comparisons are:
| GTK 2 | GTK 3.0.0 |
| GTK 3.0.7 | GTK git master |
Some details about this for anyone who likes nitty-gritty details:
With 27s vs 37s GTK 2 is still faster than GTK 3’s master branch. Measurements indicate that this is mostly related to widgets not being optimized for height-for-width yet but being straight up ports of the GTK 2 versions. And we do at least twice as many size requests with the new GTK. We first query the width and then the height for the returned width. So we run the size computation code twice…
With 37s vs 53s the GTK 3 master branch is faster than 3.0.7 because I spent some time fine-tuning label size querying and Tristan spent time caching size requests so we don’t have to repeatedly do them.
With 53s vs 1:11 3.0.7 is a lot faster than 3.0.0 because we initially were very careful at invalidating style information when widgets changed. Unfortunately that caused the code to update the CSS styling information 6+ times when creating a widget. And that was very noticable. So I dived into the code and tuned it and we now only query the style information once. As it should be.
And the TL;DR version: GTK 3 is getting faster every day. But if there’s something where GTK 3 is way slower than GTK2, it might be something that we missed, so don’t hesitate to provide us with a way to test it.
We can make nice videos out of it!