July 27, 2012
General, running
5 Comments
For those of you who have been keeping an eye out for me in A Coruna this week I’m sorry to be letting you down. Instead of Galicia, I will be in the Alps this weekend, finally running the race I have spent the last 4 months preparing for: the 6000D.
I have written a post about my final preparations, and a fundraising update (I’m running the race in aid of Muscular Dystrophy Ireland, a group near and dear to my heart) over at “Run for MDI”. It’s not too late to make a donation, if you’d like to. Thanks to the support of friends, family and colleagues, we have raised over €1600 so far!
I am sorry to be missing you all – but if anyone wants to follow along tomorrow and check on my progress, you can track me live during the race.
July 6, 2012
General, home, running
1 Comment
Fancy yourself as a smartypants who knows everything there is to know about everything? Could you name all the cities who have had two or more soccer teams win a European club tournament? Or name the artist and song that kept “Penny Lane” and “Strawberry Fields Forever” off the number one spot in the UK in 1967? Can you name the flower found on the Hong Kong flag? Will you be in Lyon on July 11th?
I’m organising a table quiz next week, Wednesday 11 July, to raise funds for Muscular dystrophy Ireland in advance of running the 6000D in three weeks time (eek!). So far, mostly because of my injury, work and training commitments, fundraising has been slow – but with the race approaching we’re heading full steam ahead, and I’m once again asking for your support and donations.
For those of you who are not in Lyon next week, you are cordially invited to Johnny’s Kitchen, 48 rue Saint Georges, in Vieux Lyon, for a quiz in aid of this cause. There will be a raffle on the night, and the owner is donating €1 for any drinks sold to quiz attendees. Doors open at 8pm, and we’ll kick off the quiz around 8.30. Entry is €3 per person, and all proceed go directly to MDI.
For those of you who can’t be there next week, you can also donate online! We’ve collected almost €700 to date, and I’m hoping to reach €1500 by the time of the race.
Thanks everyone for your support!
March 21, 2012
General, running
3 Comments
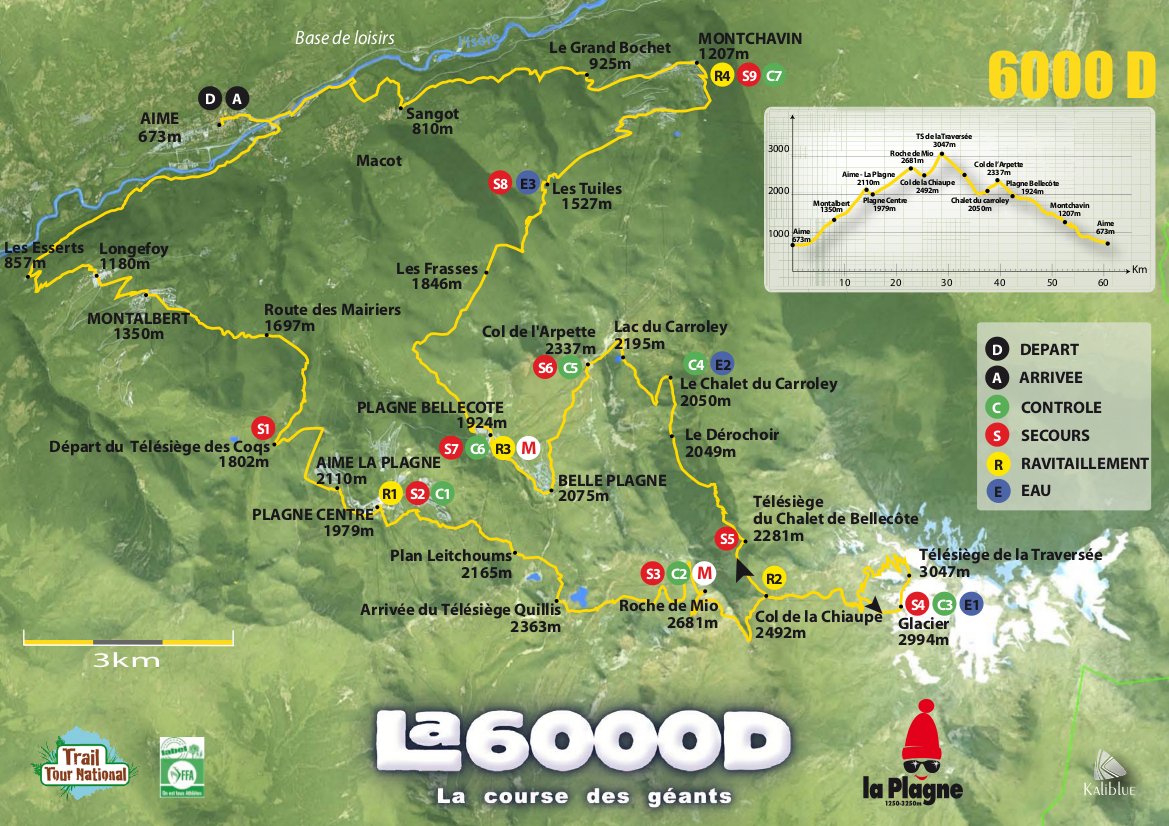
Map of the 6000D
This Summer, on July 28th, I’ll be running a 60km mountain trail race in La Plagne in the Alps, the 6000D. And to provide myself with an added incentive, and to give back something to an organisation that has helped my family in the past, I will be raising money for Muscular Dystrophy Ireland in the process.
I’ve got a blog (in both English and French) specifically for the event to cover my training and fundraising activities, and to give people more information about muscular dystrophy and MDI. I’ve posted a first blog post detailing how I got involved in this as well as some information on muscular dystrophy, MDI and the 600D race up there. I have set an ambitious funding goal of €3000 – and you can follow along and donate on mycharity.ie right now!
In the coming months, I hope that all my friends and family will help me raise money and donate to this great cause. I’ll periodically post updates here, but primarily I’ll be keeping people up to date on the Run for MDI blog and the 6000dForMdi twitter feed. Yu can also subscribe to a newsletter if you don’t want to visit the site regularly – I’ll send out occasional email updates with what’s been going on.
Please help spread the word, and consider donating to help this great cause!
February 16, 2012
community, General
No Comments
Mentoring, lawyer/developer relations, organising events… a few pieces I’ve written/delivered were released recently.
As an OuterCurve mentor I wrote a short article targeted at project managers considering submitting their projects to the Google Summer of Code this year.
My piece on getting people together was included in the recently released Open Advice book, edited and put together by Lydia Pintscher and others. It’s in great company – there are some excellent articles in there. My personal favourites are “Everyone else might be wrong, but probably not”, from Evan Prodromou, “Documentation and my former self” by Anne Gentle, “Software that has the quality with no name” by Federico Mena Quintero and “Who are You, What are You Selling, and Why Should I Care?” by Sally Khudairi, but there are more where those came from.
My write-up of the talk I gave in the Legal Issues DevRoom at FOSDEM, “Gray areas in software licensing” was published on LWN (it’s behing a pay wall for a few days, email me and I’ll share a direct link). Bradley Kuhn informs me that it will be available in audio form in the very near future in the FaiF oggcast.
And my presentation “Crafting Communities to Craft Software” at Redmonk Brew (aka Monkigras), which I reprised in a modified form as “Sustainable mentorship” for FOSDEM in the cross-desktop DevRoom, based largely on an article I wrote a while back was very well received – thank you for the praise! Videos from London and Brussels should be going online soon. In a related note, Kohsuke Kawaguchi’s presentation on creating a developer community was also awesome.
And finally, Stormy Peters published her write-up of the hiring process which led to Karen Sandler becoming the GNOME Foundation Executive Director. I had the pleasure of being part of the process, and I think I contributed something useful to it.
December 9, 2011
freesoftware, General, work
3 Comments
Earlier this week, I wrote:
I hate docs that tell you what to do, but not why. As soon as a package name or path changes, you’re dust. This is maybe the 4th time I’ve been configuring Apache to delegate stuff to Tomcat using mod_jk, and every time is just like the first.
For those who don’t know, mod_jk is a module inplementing the wire protocol AJP/13, which allows a normal HTTP web server to forward on certain requests to a second server. In this case, we want to forward requests for JSP pages and servlets to Tomcat 6. This allows you to do neat things like serve static content with Apache and only forward on the dynamic Java stuff to Tomcat. The user sees a convenient URL (no port :8080 on the hostname) and the administrator gets to serve multiple web scripting languages on the same server, or load balance requests for Java server resources across several hosts.
I have spent enough time on it at this point, I think, that I understand all of the steps in the process, and have stripped it down to the bare minimum that one would need to do in terms of configuration to get things working. And so I’m putting my money where my mouth is, and this is my attempt to write a nice explanation of how mod_jk does its thing, and how to avoid some of the common mistakes I had.
First, a remark: Apache is one of those pieces of software that has gotten harder, rather than easier, to configure as time has gone on. Distributions each package it differently, with different “helpful” mechanisms that make common tasks like enabling a module easier, and to enable convenient packaging of modules like PHP, independent of the core package. But the overall effect is that a lot of magic done by distributions makes it much harder to follow the upstream documentation. Config files are called different names, or stored in different places. Different distributions handle the inclusion of config file snippets differently. And so on.
This is not to say that Apache, Tomcat and mod_jk don’t have some nice docs – they do, but often the docs don’t correspond to the distros, or haven’t been updated in a while, and often they don’t explain why you have to do something, putting emphasis instead on what you need to do. After all my reading, I finally found the Holy Grail I was looking for – the simple document of how to configure mod_jk – but even this has its shortcomings. The article doesn’t mention Tomcat, for example, which left me digging around for information on the configuration I needed to do to Tomcat, which led me to this, which led me to over-write the sample workers.properties file in the simple set-up document.
But if you understand the First Principles, you can figure out what’s going on with any organisation of configuration. That’s what I’m hoping to get across here.
How does mod_jk do its thing?
The first issue I had trouble getting my head around was how, exactly, all this was supposed to work. In particular, I didn’t quite understand how the configuration worked on the Tomcat size of things.
As I understand it, here’s what happens:
- A GET request comes in to httpd for http://localhost/examples/jsp/num/numguess.jsp
- Apache processes the request, and find a matching pattern for the URL among JkMount directives
- Apache then reads the file specified by the JkWorkersFile option to figure out what to do with the request. Let’s say that config file says to forward to localhost:8009 using the protocol ajp13
- Tomcat has a Connector listening on port 8009, with the protocol AJP/13, which handles the request and replies on the wire. Apache httpd sends the reply back to the client
Apache httpd configuration
There are two steps to configuring Apache:
- Enabling the module
- Configuring mod_jk
Apache provides a handy utility called “a2enmod” which will enable a module for you, once it’s installed. What happens behind the scenes for modules depends on the distribution. On Ubuntu, module load instructions are put in a file called /etc/apache2/mods-available/<module>.load optionally alongside a sample configuration file /etc/apache2/mods-available/<module>.conf. To enable the module, you create a symlink to the .load file in /etc/apache2/mods-enabled.
On my Ubuntu laptop, my jk.load contains:
LoadModule jk_module /usr/lib/apache2/modules/mod_jk.so
On OpenSuse, on the other hand, a line similar to this is explicitly added to the file /etc/apache2/sysconfig.d/loadmodule by sysconfig, based on the contents of a field in the configuration file /etc/sysconfig/apache2 – remember how I said that distro packaging makes things harder? If you added the line directly to the loadmodule file, the change would be lost the next time Apache restarts.
In both cases, these files (on Ubuntu, the mods-available/*.load files, and on OpenSuse the sysconfig.d/* files) are loaded by the main Apache config file (httpd.conf) at start-up.
Configuring mod_jk
The minimum configuration that mod_jk needs is a pointer to a Workers definition config file (JkWorkersFile). Other useful configuration options are a path to a log file (JkLogFile – which should be writable by the user ID which owns the httpd process) and a desired log level – I set JkLogLevel to “debug” while getting things set up. On OpenSuse, I also needed to set JkShmFile, since for the default file location (/srv/www/logs/jk-runtime-status) the directory didn’t exist and wasn’t writable by wwwrun, the user that owns the httpd process.
This configuration, and the configuration of paths below, is usually in a separate config file – in both Ubuntu and OpenSuse, it’s jk.conf in /etc/apache2/conf.d (files ending in .conf in this directory are automatically parsed at start-up). To avoid errors in the case where mod_jk is not present or loaded, you can surround all Jk directives with an “<IfModule mod_jk.c>…</IfModule>” check if you’d like.
The JkMount directive configures what will get handled by which worker (more on workers later). It takes two arguments: a path, and the name of the worker to handle requests matching the path. Unix wildcards (globs) are accepted, so
JkMount /examples/*.jsp ajp13_worker
will match all files under /examples ending in .jsp and will pass them off to the ajp13_worker worker.
If you want Apache to serve any static content under your webapps, you’ll also need either a Directory or Alias entry to handle them. Putting together with the previous section, the following (from Ubuntu) was the jk.conf file I used to pass the handling of JSPs and servlets off to Tomcat, and serves static stuff through Apache:
<IfModule mod_jk.c>
JkWorkersFile /etc/libapache2-mod-jk/workers.properties
JkLogFile /var/log/apache2/mod_jk.log
JkLogLevel debug
Alias /examples /usr/share/tomcat6-examples/examples
JkMount /examples/*.jsp ajp13_worker
JkMount /examples/servlets/* ajp13_worker
</IfModule>
I should use Directory to prevent Apache from serving anything it shouldn’t, like Tomcat config files under WEB-INF – I could also just use “JkMount /examples/* ajp13_worker” to have everything handled by Tomcat.
Now that Apache’s config is done, we need to configure mod_jk itself, via the workers.properties file we set in the JkWorkersFile parameter.
workers.properties
Sample workers.properties files contain a lot of stuff you probably don’t need. The basic, unavoidable parameters you will need are the name of a worker (which you’ve already used as the 2nd argument for JkMount above), and a hostname and port to send requests to, and a protocol type (there are several options for worker type besides AJP/1.3 – “lb” for “load balancer” is the most important to read up on). For the above jk.conf, the simplest possible workers.properties file is:
worker.list=ajp13_worker
worker.ajp13_worker.port=8009
worker.ajp13_worker.host=localhost
worker.ajp13_worker.type=ajp13
And that’s it! The last step is to set up Tomcat to handle AJP 1.3 requests on port 8009.
Configuring Tomcat
In principle, Tomcat doesn’t need to know anything about mod_jk.It just needs to know that requests are coming in on a given port, with a given protocol.
Typically, an AJP 1.3 connector is already defined in te default server.xml (in /usr/tomcat6 on both Ubuntu and OpenSuse) when you install Tomcat. The format of the connector configuration is:
<Connector port=”8009″ protocol=”AJP/1.3″ redirectPort=”8443″ />
I am pretty sure that this will work without the redirectPort option, but I haven’t tried it. It basically allows requests received with security constraints specifying encryption to be handled over SSL, rather than unencrypted.
In addition to this, Tomcat does provide a facility to auto-create the appropriate mod_jk configuration on the fly. To do so, you need to specify an ApacheConfig in the Tomcat connector, and point it at the workers.properties file. This facility looks pretty straightforward, but I know I found it confusing in the past when I lost edits to the jk.conf file – I prefer manual configuration myself.
Gotchas
I have had quite a few gotchas while figuring all this out – I may as well share for the benefit of future people having the same problems.
- All the documentation for mod_jk installedd with the packages refers to Tomcat5 paths – for example, on OpenSuse, in the readme, I was asked to copy workers.config into /etc/tomcat5/base – a directory which doesn’t exist (even when you change the 5 to a 6)
- If your apache web server uses virtual hosts (and, on Ubuntu, it does by default) then JkMounts are not picked up from the global configuration file! You need to either add “JkMountCopy true” to the VirtualHost section, or have JkMounts per VirtualHost. If you used Alias as I did above, and you try to run a servlet, the error message is just a 404. If you try to load a JSP, you will see the source.
- If you make a mistake in your workers.property file (I had a typo “workers.list=ajp13_worker” for several hours) and your worker name is not found in a “worker.list” entry, you will see no error message at all with warnings set to error or info. With the warning level set to debug, you will see the error message “jk_translate::mod_jk.c (3542): no match for /examples/ found” The chances are you have a typo in either your jk.conf file (check that the name of the worker corresponds to the name you use in workers.properties), or you have a typo somewhere in your workers.properties file (is it really work.list? Does the worker name match? Is it the same as the worker name in the .host, .port and .type configuration?
- Make sure you get Tomcat working correctly first and working perfectly on port 8080 – or you won’t know whether errors you’re seeing are Tomcat errors, Apache errors or mod_jk errors.
I’m sure I’ve made mistakes and forgotten important stuff – I’m happy to get feedback in the comments.
November 18, 2011
community, freesoftware, General
9 Comments
A couple of days ago, I tweeted this: “Insight of the day: All “community norms” documents come down to one word: Empathy. Think how others will feel before you act.” I think that’s worth developing on.

As I was growing up, empathy meant "Deanna Troi" to me
Here are a few examples:
- GNOME Code of Conduct: “If someone asks for help it is because they need it. Do politely suggest specific documentation or more appropriate venues where appropriate, but avoid aggressive or vague responses such as “RTFM”.” – think how it feels to need help, and to take the step of asking for it. I want to know that someone *understands* what I’m going through, feels my frustration, and is looking for a way to help relieve it. Recently, when confronted with a technical issue that prevented me from using my scanner, the advice I received on an IRC channel was to upgrade or change my Linux distribution! How un-empathic can you get!
- Koha patch rules (along with every other development project in the world): “The patch must apply to the current HEAD of the master branch of the code”: Put yourself in the place of a project maintainer who receives a patch proposal. He tries to apply it to his source tree, but the merge fails. Why? Because the patch was created against a year-old release of the project, and he’s since reworked internals to solve a different, unrelated issue. The maintainer is faced with a number of unsavory choices now: Spend time reading the patch, understanding what it does, and “forward-porting” it to master; check out the old branch, apply the patch, review, and test it there, and not commit to master; or drop the patch. What would you do in that situation? Someone is giving you a gift, which is going to make work for you. Is it worth an hour or two of your time to work on it to get it to just apply to your work? You still need to review the patch after that – which you would have to do anyway. In that situation, most people will ask the original patch proposer to do the initial grunt work and get the patch working on the tip of master.
- Now flip things around. You found a bug in software you use – the bug was really annoying. You took the time to get the source code, identify, qualify and fix the buig, open a bug report, which was confirmed, and attach a patch which you have checked fixes the problem. And what answer do you get? “Not good enough – work on it more”. How would that make you feel? That depends on how it is communicated. If it’s a stock answer, like a sheet of paper handed over a tax office counter, with a list of prerequisites, then I bet that would make me angry, resentful and frustrated. I poured time and effort into that patch, and this is how you treat it? If the criticism is of the core of the patch – it doesn’t fix the problem, or should do so differently, then the criticism might be easier to take. But if it’s issues which potentially add many hours of effort on top of time already spent, with no benefit to the proposer (check out the latest code, upgrade half a dozen dependencies without breaking my old version, compile it, and then forward-port the patch), chances are he won’t do it. An empathic response might be to make someone aware of the guidelines and their reason for being, but help him with the forward-porting on IRC by asking him to explain the patch, what it does and why.
All of those guidelines on indentation and whitespace, commenting code, including test cases, updating documentation, and ensuring code compiles at the tip of the master branch are designed to help patch proposers make patches which are easy for maintainers to apply. And in this context, an empathic patch proposer can understand them much better. Miguel de Icaza did a great job of framing this right.
When I was in college, I went to the Netherlands one Summer for a working holiday. At one point, I had a job offer for short-term work, but needed to be registered for tax to start, and I needed a bank account to get paid. So I went to the tax office, and the lady behind the counter very resignedly handed me a piece of paper with prerequisites, and told me to come back when I had fulfilled them. Then she looked over my shoulder and said “Next!” One of the prerequisites was a permanent address – I explained that I was living in a camp-site for the summer, and would that address do? Of course not! No proposed solution, no consideration of the situation I was in, no empathy.
Then I went to the bank, where I was told that I needed a permanent address to open an account. Same sense that the person I was dealing with didn’t care about me. So with my friend Barry, we looked into short term accommodation options. Landlords required (among other things) an employment agreement and a bank account before they would rent us accommodation – even if only by the week! In the end, we had to pass up that job, and work “on the black” for less than minimum wage to survive the Summer – but what choice did we have?
How frustrating! Just imagine how we felt. That’s empathy.
Again and again in community guidelines, whether it’s guidelines for people who are approaching a community to report a bug or propose a patch or feature, or guidelines for community members dealing with each other and people outside the community, this idea “think how this would make you feel if the roles were reversed” is pervasive, but unwritten. I think that it should be.
It reminds me of a social experiment I heard about recently:
Rats are placed in a box with a lever. When you pull the lever, a food pellet is distributed. The rats quickly learn to pull the lever. After a while, you change the configuration of the cage. Now, when the lever is pulled, the food pellet is distributed, but a cold shower drenches all the rats in the box. After a while, the rats learn not to pull the level, and start to punish rats who do as a group.
The second generation starts when a new rat is introduced into the box. as he approaches the leverl, the older rats all jump on top of him, to prevent him from touching it. In effect, they are teaching him the rule “don’t touch the lever”, without explaining why the rule exists. As time goes on, new rats are added, and old rats removed from the box.
The third generation happens when there are none of the oiriginal rats left in the box. None of the rats have experienced the cold shower after the lever was pressed. At that point, you can turn off the cold shower function – you will be sure that no rat will ever touch the level, because the community rules forbid it. Ask any of the rats why, though, and they will not be able to give you a better answer than “because that’s the way it is”. If rats could talk, of course.
Community guidelines which are purely written documents, but which neglect the empathic side of the equation, and don’t explain how not following the guidelines affect other people, can be similar. It’s important to include the reasons for guidelines,so that we don’t forget how breaking the rules makes others feel. It’s also important to have sufficient flexibility and adaptability in dealing with new community members – like the rat experiment, circumstances change all the time. Back when everyone was using CVS, performing merges was a complicated and time-consuming process. Nowadays, rebasing and merging with Git, Bazaar or Mercurial is so easy that some of the coding guidelines we used to have may no longer have the same impact. Likewise, email technology has moved on, and with cheap and copious bandwidth, email norms have evolved – netiquette community norms move on with them.
In general, as Bill & Ted famously said, “Be excellent to each other”. Think about how your actions & statements will be received. Be empathic.
October 6, 2011
community, General, gnome, maemo, work
5 Comments
With the announcement of Tizen (pronounced, I learned, tie-zen, not tea-zen or tizz-en) recently, I headed over to the website to find out who the project was aimed at. I read this on the “Community” page:
The Tizen community is made up of all of the people who collectively work on or with Tizen:
- Product contributors: kernel/distribution developers, release managers, quality assurance, localization, etc.
- Application developers: people who write applications to run on top of Tizen
- Users: people who run Tizen on their device and provide feedback
- Vendors: companies who create products based on Tizen
- Other contributors: promotion, documentation, and much more
Anyone can contribute by:
- Submitting patches
- Filing bugs
- Developing applications
- Helping with wiki documentation
- Participating in other community efforts and programs
Wow! That’s a diverse target audience, and a very wide ranging list of ways you can help out. But is it really helpful to scope the project so wide, and try to cater to such a wide range of use-cases from the start? And is the project at a stage where it even makes sense to advertise itself to some of these different types of users?
I have talked about the different meanings of “maintainer” before, depending on whether you’re maintaining a code project or are a package maintainer for a distribution. I have also talked about the different types of community that build up around a project, and how each of them needs their own identity – particularly in the context of the MeeGo trademark. I particularly like Simon Phipps’s analysis of the four community types as a way to clarify what you’re talking about.
For Tizen, I see between three and five different types of community, each with different needs, and each of which can form at different stages in the life-cycle of the project. Trying to “sell” the project to one type of community before the project is ready for them will result in disappointment and frustration all round – managing the expectations of people approaching Tizen will be vital to its long-term success, even if it opens you up to short-term criticism. Unless each of these communities is targeted individually and separately, and at the right time, I am sceptical about the results.
“Upstream” software developers
The first and most identifiably “Open Source” family of communities will be the software developers working on components and applications which will end up in the core of Tizen. For the most part, these communities exist already, and Samsung and Intel engineers are working with them. These are the projects we commonly call “upstreams” – projects you don’t control, but from whom code flows into your product.
In other cases, code will originate from Intel and/or Samsung. In the same way that Buteo, oFono and the various applications which were developed for the MeeGo Netbook UX were very closely associated with MeeGo, there will be similar projects (sometimes the same projects) which will have a close association with Tizen. Each of these projects will have their own personality, their own maintainers, roadmaps, specs – and each of them should have their own identity, and space to collaborate and communicate.
Communities form around programming projects not because of the code, but because of a shared vision and values. Each project will attract different people – the people who are interested in metadata and search are not the same as the people who will be passionate about system-wide contact integration. Each project needs its own web space, maintainers, bug tracker, mailing list, and wiki space. Of course, many projects can share the same infrastructure, and a lot of the same community processes (for things like code governance), and for projects closely related to Tizen, we can provide common space to help create a Tizen developer community in the same way there’s a GNOME developer community. But each community around each component will have its own personality and will need its own space.
At the level of Tizen, we could start with an architecture diagram, perhaps – and for each component on the architecture diagram, link to the project’s home page – many of the links will point to places like kernel.org, gnome.org, freedesktop.org and so on. For Tizen-specific projects, there could be a link to the project home page, with a list of stuff that needs to be done before the component is “ready”.
Core platform packagers, testers, integrators
Once we have a set of components which are working well together, we get to the heart of what I think will be Tizen’s early activity – bringing those components together into a cohesive whole. Tizen will be, basically, a set of distributions aimed at different form factors. And the deliverable in a distribution is not code or a Git tag, it’s a complete, integrated stack.
The engineering skills, resources and processes required to integrate a distribution are different to those of a code project. Making a great integrated Linux platform is obviously difficult – otherwise Red Hat would not be making money, and Ubuntu would not have had the opportunity to capture so much mind-share. Both Red Hat and Canonical do something right which others failed at before them.
Distributions attract a different type of contributor than code projects, and need a different set of tools and infrastructure to allow people to collaborate.At the distribution level, it is more likely you will be debating whether or not to integrate a particular package or its competitor than it is to debate whether to implement a feature in a specific package. Of course, it is possible to influence upstream projects to get specific features implemented, not least by providing developer resources, and there will be a need for some ambassadors to bridge the gap to upstream projects. And it is possible for a distribution to carry patches to upstream packages if that community disagrees. But in general, not much code gets written in distributions.
What the distro community needs and expects is infrastructure for continuous integration, bug tracking software, a way to submit and build software packages, good release engineering, an easy way to find out what packages need a maintainer (see Debian’s WNPP list or Ubuntu’s “need-packaging” list for examples) and a way to influence what packages or features are included in future releases (see Fedora or Ubuntu for examples). They also want tools to allow packaging, testing and deploying the integrated distribution – for an embedded distro, that might mean an emulator and an image creator, perhaps.
Vendors and carriers
Communities of companies are worth a special mention. Companies have very different ways of working together and agreeing on things than communities of individuals. I was tempted to just roll vendors into the “Platform integrators” community type, but they are sufficiently different to be considered another type of community. Vendors have different constraints and motivations than individual contributors to the platform, and we should be aware of those.
Vendors like to have a business relationship – some written agreement that shows where everyone stands. They have a direct relationship with people who buy their hardware, and have an interest (potentially in conflict with other communities) in owning the user relationship – through branded application stores, UI and support forums, for example. And since vendors are typically working on hardware development in parallel with software development, they care a lot about a reliable release schedule and quality level from the stack. Something that companies care about which individuals usually don’t are legal concerns around working with the process – do they have patent rights to the code they ship? Are they giving up any of their own potential patent claims?
3rd party application developers
Application developers don’t care, in general, whether the platform is open source or closed, or developed collaboratively or by one party (witness the popularity of Android and iOS with application developers). What they do care about are developer tools, documentation, and the ability to share their work with device users and other application developers. Some application developers will want to develop their applications as free software, and it is possible to enable that, but I think the most important thing for application developers is that it’s easy to do things with your platform, that there are good tools for developing, testing and deploying your application, that your platforms APIs are enabling the developer to do what he wants, and that you are providing a channel for those developers to get their apps to users of your platform.
An application developer doesn’t want to have to ship his software to 5 different app stores on every release – in contrast to vendors, he would like a single channel to his market. Other things he cares about are being able to form a relationship with his users – so app stores need to be social, allow user ratings and comments, and allow the author to interact with his users. Clear terms of engagement are vital here too – especially for commercial application developers. And application developers are also another type of community – they will want to share tips and tricks, code, and their thoughts on the project leaders in some kind of app developer knowledge base.
Device users
There is another potential community which I should mention, and that is users of your platform – typically, these will be users of devices running your platform. It should be possible for engaged users to share information, opinions, tips & tricks, and interesting hacks among each other. It should also be possible to rate and recommend applications easily – this is in the interests of both your user community and your application developer ecosystem.
OK, so what?
Each of these community types is different, and they don’t mix well. They mature at different rates. There is no point in trying to build a user platform until there are devices running your platform on the market, for example
So each type of community needs a separate space to work. There is no point in catering to a 3rd party application developer until you have developer tools and a platform for him to develop against. Vendors will commit to products when they see a viable integrated platform. And so on.
What is vital is to be very clear, for each type of community, what the rules of engagement are. As an example, one company can control the integration of a platform and the development of many of its components (as is the case for Android) and everyone is relatively happy, because they know where they stand and what they’re getting into. But if you advertise as an open and transparent project, and a small group of people announce the decisions of what components are included or excluded from the stack (as was the case in MeeGo), then in spite of being vastly more open, people who have engaged with the project will end up unhappy, because of a mismatch between the message and the practice in the project.
So what about Tizen? I think it is a mistake to announce the projects as a place to “submit patches, report bugs and develop applications” when there is no identifiable code base, no platform to try, and no published SDK to develop against. By announcing that Tizen is an Open Source platform, Intel and Samsung have set an expectation for people – and these are people who have gone through the move to MeeGo under two years ago, and who have seen Nokia drop the project earlier this year. If they are disappointed by the project’s beginnings because the expectations around the project have been set wrong from the offset, it could take a long time to recover.
Personally, I would start low-key by announcing an architecture diagram and concentrating on code and features that need writing, then ramp up the integrator community with some alpha images and tools to allow people to roll their own; finally, when the platform stabilises roll out the developer SDK and app store and start building up an application developer community. But by aiming too big with the messaging, Tizen runs the risk of scaring some people away early. Time will tell.
September 1, 2011
General
2 Comments
The Blue Advocado (formerly Board Café) is one of my favourite newsletters – there’s always at least one article I want to read, and the area of non-profit management is such a broad and deep one that there’s always something to learn.
This month’s issue has some great tips on how to get more out of conferences:
- Choose the sessions you know the least about
- Instead of listening for good ideas (only), listen for things you can quote in your next grant proposal or monthly report
- Skip at least one session. Go outside.
- Fail-proof way to meet someone: get to a session early; other introverts will be sitting there playing solitaire on their cell phones. Sit near one of them, then lean over and say, “Would you mind if I introduced myself? I’m supposed to meet at least five new people at this conference and I haven’t met any so far!”
- If you’re bored or irritated by a session, walk out.
- Put up a sign on the bulletin board to meet people. If no-one turns up, no-one will ever know.
Certainly, tips 1, 2 and 6 are things I have not done before, and would be interested in trying.
June 10, 2011
General
No Comments
I’m happy to be co-ordinating the “Humanitarian Free/Open Source Software” track at this year’s Open World Forum. The call for participation is now open.
I’ve already been in contact with some great organisations including Ushahidi, CrisisCommons and Akvo, and I plan to contact Sahana and Benetech about the conference too. I’d love to get more stories from around the world of how free software & open data are making the world a better place and saving lives.
June 8, 2011
community, General
4 Comments
Interesting article from Gartner which has some relevance to my recent proposal for a gnome-design mailing list: Gartner Identifies Five Collaboration Myths.
Exerpt:
Myth 1. The right tools will make us collaborative
Technology can make it easier to collaborate when applications mirror a more intuitive, fluid work style, but selecting a tool without addressing roles, processes, metrics and the organization’s workplace climate is putting the cart before the horse.
« Previous Entries Next Entries »