Well I was playing with the SPU code again tonight – trying to get it to spread the load across multiple SPUs. And how to get timing info out of it.
I dunno, about the best I could come up with was:
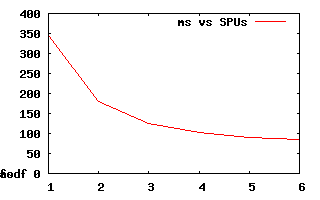
i.e. not a particularly linear scaling. Although I have a feeling the kernel is doing some funky scheduling of the SPUs so I may not be getting real numbers after 3 active SPUs. This is for a 1920×1080 resolution version BTW.
I did a bunch of other things too – double buffered output, and implemented a ‘job queue’ mechanism. Each SPU calculates a pre-determined number of rows of the output, DMA’ing it back to the ‘frame buffer’ after each line is calculated – whilst calculating the next line. After it’s done all the lines in a ‘job’, it checks, using an atomic read/modify/write sequence, what the next line available is. If there are still lines to go, it then processes more. The ‘job queue’ is just this ‘next row to calculate’ number.
There is very little contention with ‘job queue’ – infact if I just check it after every line it’s only a bit slower than doing it after a larger number of lines, so that doesn’t appear to be a bottleneck. I dunno, I’ll have to keep playing I guess – it’s probably just kernel scheduling. Might have to try last night’s version again – that used static allocation.