So, Gnome Shell is moving to a document centric model, and is starting to leverage new components, like Zeitgeist or Tracker to make finding documents easier. And an interesting issue stems from the fact that the concept of “Document” is much broader than the good old concept of “UNIX file”. Both Zeitgeist and Tracker deal not only with files, but also with resources such as conversations, emails, people, bookmarks… And both allow the user to find those items.
Finding the items… and what?
So, you found what you were searching for. Now, what do you do with it? Is it a pdf document? Easy, fire up the PDF viewer! An image? Fire the image viewer! A contact? An email? How do we identify those? What do we do with them?
The identification problem is already solved if you assign a URI to each resource, so for example if your contacts are in Tracker you just pass the URI of the contact, and done. Same for an email. However, what application can deal with a contact? Files have MIME types, resources don’t…
If you use Tracker, then you can use the RDF class(es) as an extension to MIME types, which is what libcontentaction does (libcontentaction was developed for the Harmattan operating system, where all the user resources are stored or exported in Tracker). Since Tracker, Zeitgeist, and KDE’s semantic system all revolve around RDF, RDF classes seems like a good candidate to extend traditional MIME types in a cross desktop way.
I believe this problem will become increasingly relevant for Gnome Shell, and I hope the work done for libcontentaction (which is a Qt lib) will be used as a base as much as possible, and hopefully end up as a XDG standard, since our KDE folks also have a pretty advanced semantic desktop system. The upcoming Desktop Summit (where I’ll likely not be this year 🙁 ) would actually be a great place to discuss this.
An example – the email case
Tracker has been indexing your emails if you’re using Evolution for some time now, and my work on Thunderbird has recently been merged, Needle, the Tracker search tool has supported email searching for some time now too. However, we’re still unable to actually do anything useful with an email result, since there is no standard mechanism to associate an action with those resources.
If you are trying the Thunderbird plugin, there is actually something you can do (but I don’t know if it works with the evolution miner too):
Create a thunderbird.desktop file (or alter the existing one) and make sure those two lines are inside:
Exec=thunderbird -mail %u MimeType=x-scheme-handler/imap-message
This works because the emails are stored in Tracker with the URL scheme imap-message:// that Thunderbird understand directly. I have no idea how standard this is, but eh, it’s quite convenient 🙂
More thoughts…
Another very interesting problem is “how to expose the relations between resources”, that is, how to go behind the old treeview/table models and present related information in a more efficient way… But that’s another broad subject.
Firefox can have some Tracker love too
12/04/2011
While Epiphany is the default browser of GNOME, and it’s a great browser (I use it from time to time), Firefox is still my brower of choice, especially since it’s so extensible.
One of the very interesting features that came with Gecko 2 (the “engine” powering Firefox 4, Thunderbird 3.3, Seamonkey 2.1) is ctypes, a feature which «makes it possible to call C-compatible foreign library functions from JavaScript code without having to write your own binary XPCOM component». Many «desktop» runtimes (gjs, python) already allow that, but not having to mess with XPCOM, IDL and friends to get the same in Firefox is a huge plus!
Wanting to experiment with this feature, I wrote a very small module to export your bookmarks to Tracker. There no UI or bells or whistles, it just sits in the background and does its job. Because it’s pure Javascript, there’s no compilation involved, just install the plugin and you’re good to go. Now, why would you like to export your bookmarks to Tracker? Well, I’ve also pushed a branch called “needle-bookmarks” which, guess what, allows the Tracker search tool (aka needle) to query bookmarks too! And it’s just a matter of time before you get that into the search of the Shell overview…
Obligatory screenshot
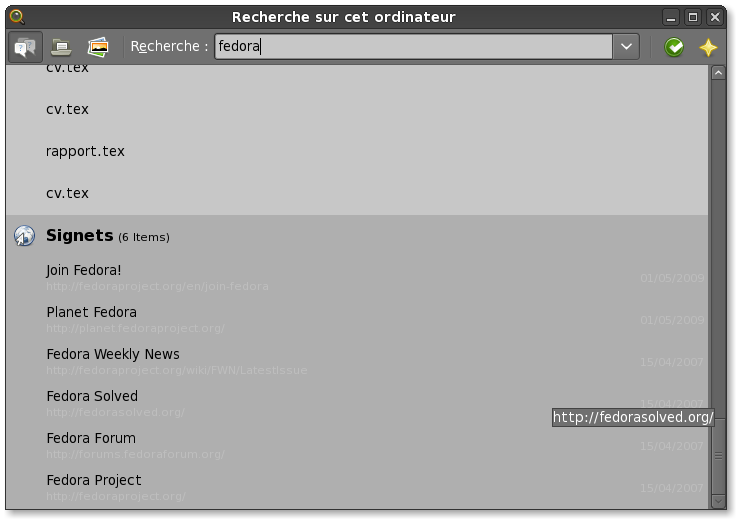
How to get the code
1. Clone git://git.mymadcat.com/tracker-firefox
2. Generate the XPI with git archive --format=zip HEAD > tracker-firefox.xpi and install it in Firefox
3. Get the needle-bookmarks branch of tracker (hopefully merged into master soon) from its git repository
4. Search your bookmarks 🙂
Future ideas
I think it would be interesting to extend the plugin to add a history observer that would log events to Zeitgeist… Zeitgeist already has a Firefox plugin, but unless it has been fixed since last time I checked, it’s not working with Gecko 2. We’re in any case working more and more together with the Zeitgeist guys to make sure the Gnome 3.1 search experience will be greatly enhanced!
Mandatory video (might not appear if you’re reading from a planet):
Following the work of Siegfried to integrate Zeitgeist and the Shell, I decided to see if I could make the Shell search use Tracker. Having the example of the Zeitgeist search providers was a huge help, and I managed (with a lot of trial and error) to hack support for Tracker search in the Shell.
The results returned from Tracker are organized into categories, for now “Documents”, “Music” and “Videos”. This can be very easily extended, as each category is mapped to a SPARQL query while the core logic is abstracted in a base class.
I have experienced a few crashes that I haven’t solved yet, looking at the backtrace it seems that gjs is trying to call some javascript that is not here anymore from the libtracker-sparql callback… It is also not super fast on my computer, though the part that is a bit slow is the adding of items to the results grid (the queries themselves are next to instantaneous).
If you want to try this at home:
- You need to patch tracker (any 0.10 series should do) with this patch to add some needed GObject introspection annotations. libtracker-sparql is in Vala, so one could hope you’d get the .gir for free, but because it uses nested namespaces, va_list for some functions etc. it gets complicated. Fixing it properly was outside of the scope of a weekend hack. For the lazy, you can also get the (incomplete but good enough for that hack) gir file directly here.
- You need to apply Seif’s “add async search providers” patch that you can find here, as well as a patch to fix thumbnailing when you’re not using GtkRecentInfo (which is not the case since the results come from Tracker), and finally the patch to add the Tracker search providers.
If you use the gir from step 1 directly (don’t forget to compile it to a typelib and install it!), no recompilation at all should be needed since everything in step 2 is javascript. You just need to install the patched shell, and enjoy the better search (plus the few crashes I mentioned above 😉 )!
Even more awesome would be to have *both* Zeitgeist and Tracker work together, so that results would be ordered by popularity. I actually have an experimental patch for tracker-needle, the search UI from Tracker, that does just that, but I’m not happy enough with the UI integration to blog about it yet.
Update: If your browser does not support webm, you can see the video hosted on Vimeo
I read Miguel’s post a bit like «My brother is dead, but now at least I get all the chocolate for myself»…
I don’t think having C# running on many closed smartphones brings any credit to Mono (and don’t get me wrong, Mono is technically an awesome technology). Having Mono run on MeeGo (which is already possible) would have been much nicer, since it’d have meant both the developer’s and user’s freedom would have been preserved, at no technical expense1. Celebrating the “victory” of Windows Phone over MeeGo on Planet GNOME does not seem the wisest thing to me2 in the current context, but freedom of expression is one of the rights I respect the most, so how could I complain?
Disclaimer: As a Nokia employee working on MeeGo, my opinion is of course biased 🙂
1 Actually, it would surely have been easier to install mono addons on MeeGo than it’ll be on Windows Phone.
2 “wise” in the sense that as many people have strong feelings about what happened, flamewars are more likely to happen…
In the last post, we learnt a way to avoid OPTIONAL blocks in queries. We however raised a problem that happens when you want to fetch an optional resource, and the predicate chain that links that resource to the subject includes some multi-valued predicate.
To illustrate this example, let’s imagine we want to retrieve all music resources, along with their tags, if they have some. The straightforward way to write this query would be:
SELECT ?m ?tagLabel WHERE { ?m a nmm:MusicPiece OPTIONAL { ?m nao:hasTag ?tag ; nao:prefLabel ?tagLabel } } [1]
If you read the previous article, and forgot about multi-valued predicates, you might try something like:
SELECT ?m nao:tagLabel(nao:hasTag(?m)) WHERE { ?m a nmm:MusicPiece } [2]
… but that query is not valid. Why? Because nao:hasTag is not single valued, a resource can have several tags. If you get several results using a predicate function, Tracker will concatenate them using a separator character, by default “,”. So the query
SELECT ?m nao:hasTag(?m) WHERE { ?m a nmm:MusicPiece } [3]
could return a line like:
urnOfMusicPiece urnOfTag1,urnOfTag2,urnOfTag3.
So what you get in the second column is actually not the identifier of a resource, but a string with URNs encoded inside. And no way the nao:prefLabel “function” can work on that.
There exists an alternative solution though, and it is to use the so called scalar selects. A scalar select is a SELECT block returning one line, and one column, which is assimilable to a scalar. And that type of select can be added to our query’s projections:
SELECT ?m (SELECT GROUP_CONCAT(nao:prefLabel(?tag), ":") WHERE { ?m nao:hasTag ?tag }) WHERE { ?m a nmm:MusicPiece } [4]
Yes, this does look a bit like black magic. But we’ll break it down into pieces. First, if you remove the scalar select, you get back to our most basic query, selecting all music resources. Now let’s analyse the scalar select itself, first without the GROUP_CONCAT:
SELECT nao:prefLabel(?tag) WHERE { ?m nao:hasTag ?tag } [5]
The query 5 has nothing really special to it, the only detail being that ?m is not defined in the scalar select, but its definition comes from the “main” one. Scalar selects in projections are evaluated after the WHERE pattern, which means you can use values from the “main” select in a scalar select in the projections, but not the other way around.
Now on to GROUP_CONCAT: if our resource ?m happens to have several tags, our scalar select will return more than one line, and additional results will be discarded (Tracker implicitely adds “LIMIT 1” to scalar selects). Not good. The GROUP_CONCAT takes all results, and concatenates them together using a defined separator. In our case, we get a list of tag labels separated by :. So, a result line from the query 4 might look like:
urnOfMusicPiece tagLabel1:tagLabel2:tagLabel3
And if there were no tags, the second column will simply be empty. Of course, this approach requires a bit of string splitting on the application side, but this is usually much cheaper than the OPTIONAL block. And if you’re really going to use this kind of query, the choice of a separator better than “:” might be a good idea, ASCII has some special characters like 0x1E (field separator) that are less likely to be used in tag labels. You can use the syntax \u001E in SPARQL.
PS. To answer the question “How do I know if a predicate is single or multi valued, you can read the ontology reference documentation, and look for the “cardinality” property of the predicates you’re using.
Update: the ASCII control character I wanted to mention was not 0x2E but 0x1E
My current job implies working with Tracker, for the first time not as a developer but as a user. This is quite a cool change, as I can now be on the side of those bitching when things don’t work as they should 🙂
As you probably know now, Tracker is a RDF database (and a set of programs to exploit it). However, it is a bit special for various reasons:
1. Tracker’s ontologies are fixed (changes are supported in a limited way), which means you should stick to the installed data schemas (ontologies), as opposed to being allowed to store any triple in the database.
2. Tracker uses SQLite. On the good side it means Tracker is rather lite on the system resources (it usually idles at around 4MB RSS, and can go maybe up to 25-30MB when running a big query). On the bad side, it means that not every operation is fast, since SQLite is an on-disk database. As my job implies using Tracker on devices with not so much memory or CPU power, it is very important to know what is fast/expensive and what is not. And it is precisely what this post is about.
OPTIONAL blocks and predicate functions
OPTIONAL blocks are one of the very costly operations in Tracker. Let’s say you want to query all music resources, and their title. You could run this query:
SELECT ?urn ?title WHERE { ?urn a nmm:MusicPiece; nie:title ?title } [1]
However, this query will only return resources that do have a title. Resources without title will not match the query. To also get resources without a title, we can write:
SELECT ?urn ?title WHERE { ?urn a nmm:MusicPiece OPTIONAL { ?urn nie:title ?title } } [2]
Now, we have an OPTIONAL block, which makes our query slower. On this very precise example, the speed difference might be negligible, but I’ve already seen 10x speedups on some queries optimized to use as few OPTIONAL blocks as possible.
The faster solution is to use “predicate functions”, a non-standard SPARQL feature that allows us to use predicate as functions on the query variables. The query [2] rewritten to use predicate functions would be:
SELECT ?urn nie:title(?urn) WHERE { ?urn a nmm:MusicPiece } [3]
In that case, the second columns in our results would be an empty string when there is no title. If this is faster, you might wonder why Tracker does not convert internally OPTIONAL blocks to predicate functions. The answer is, OPTIONAL blocks allow you to do more things, that are not always possible with predicate functions. When using an optional block, you define a sparql variable (?title in our example), which you can reuse in other patterns. This is not the case when using predicate functions.
You can chain predicate functions. If you also want to get the album title of each music resource, you can write:
SELECT ?urn nie:title(?urn) nie:title(nie:musicAlbum(?urn)) WHERE { ?urn a nmm:MusicPiece } [4]
If you use a predicate function on a predicate that can have more than on value, values will be joined with a user defined separator (by default, “,”):
SELECT ?urn nie:keyword(?urn) WHERE { ?urn a nmm:MusicPiece } [5]
However, predicate functions don’t work on lists. That means if you have a chain of predicate functions p1(p2(…pn(?variable))), the query will only be valid if p2, p3…pn are single valued.
If one of the predicates is not single valued, you will either have to use an OPTIONAL block… Or wait until the next blog post, where I’ll present an alternative solution 🙂
There has been recently an increasing number of people dropping on IRC (#tracker on GimpNet), with nice ideas for projects using Tracker. Some of them are looking for using Tracker on a server, or accessing it using languages other than C or Vala, which are usecases we don’t really support right now (although our DBus interface is of course language agnostic, it is not really the preferred IPC), and some others are just curious about the idea of having a global metadata database.
The common factor in all those users, is that at some point they start playing with SPARQL (Tracker being an RDF database, SPARQL is the query language to access the data). And, inevitably, they ask us where they can find documentation… The problem is, there is of course documentation on the W3C website about SPARQL, but many users find it hard to follow. Personally, the only section I use in the W3C doc is the SPARQL grammar reference. However, we also have various SPARQL examples in the Tracker documentation on Gnome Live, and a page explaining the non-standard SPARQL features supported by Tracker. Those two pages are usually enough to get people started, and allow them to write their first queries.
I initially intended this article to be about how to write fast SPARQL queries, but I will split that part in another post, to keep the size reasonable.
And remember, Tracker will be part of Gnome 3.0, so it’s now the best moment to learn about it! The project is evolving at a tremendous pace, every weekly release being loaded with fixes and performance improvements. If you still have memories about Tracker 0.6, be sure to erase them carefully, and take a fresh look at Tracker 0.9!
Spamassassin fun
03/11/2010
My mail server uses a pretty standard setup to filter spam, that is Spamassassin. I get really good results, and use a SIEVE rule to move all the spams to a “Junk” folder.
The funny part is that some mails started to end up in the “Junk” folder over the last two weeks, although Spamassassin hadn’t marked them as spam… It turned out that the X-Spam-Status header included the word “BAYES_00”, and my SIEVE rule was “if X-Spam-Status contains yes, move to Junk”.
The moral of the story is, be careful with your SIEVE rules 🙂
More GUADEC 2010 pictures!
16/08/2010
Hello there!
I finally sorted my GUADEC 2010 photos, and uploaded them, for your great viewing pleasure… If you want to see Desrt’s killer look, Marc’s intense happiness or Bastien’s tongue, go see my GUADEC 2010 pictures!
My travel and accommodation were sponsored by the GNOME foundation, thank you to them!
![]()
Progress on Hormiga: loading from properties
12/08/2010
Today I finally added support in Hormiga (your favourite Tracker ORM ((It is the only one. So it’s necessarily your favourite.))) for loading proxies providing a value for one of their properties. In short, this means that you can now do
var my_proxies = MyProxyClass.load_from_my_property ("my_value"); |
Following the previous example, you could now use the following code to load all the photos with tag “foobar”:
var tag_foobar = Tag.load_from_label ("foobar"); var photos = Photo.load_from_tag (tag_foobar); |
The documentation was updated too.
Next step will be to allow direct SPARQL queries to load proxies, as I don’t intend to hide every SPARQL feature under the API (yes, I do think developers can learn SPARQL, come one, it’s easy).