Nautilus 2.24 will have tab support:
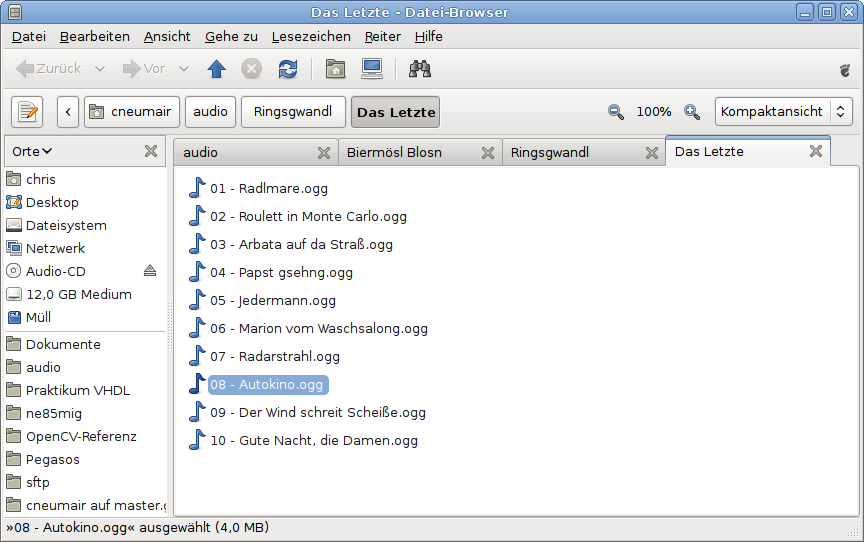
Thanks to Jared Moore for making the tab user interface consistent with Epiphany and GNOME Terminal.
Nautilus 2.24 will have tab support:
Thanks to Jared Moore for making the tab user interface consistent with Epiphany and GNOME Terminal.
After my recent blog entry about Nautilus tab support, Jared Moore raised his hand, started a private bzr branch and hacked away. This is great news, because it shows that we have so much contribution potential. For instance, Paweł Paprota is about to receive an SVN account.
A main focus of us (the “established” developers and maintainers) is to ensure that all you programming contributors out there receive optimal assistance and mentoring. Of course, this also applies to users, translators, artwork contributors, and journalists!
Because my last blog entry was a success, let’s try it again:
We are looking for someone who wants to improve the GTK+ tree view selection interaction: At the moment there is no way to pop up a context menu or drag a selection rectangle in a crowded list of files in the Nautilus list view.
The six years old bug report is available here, an email explaining the current issue is available on the mailing list archives of gtk-devel-list.
This is a message to all the people who want to get involved with GNOME/Nautilus development, and do something useful! 🙂
As of writing, I am the only active Nautilus maintainer, and I am totally running out of time due to my studies. I’ll have a high frequency engineering exam on Wednesday, and it’s getting worse due to various time-consuming activities in my spare time.
Therefore, I am looking for an interested hacker who wants to finish my work on Nautilus user interface tab support (“multiview” branch). You should make sure that all the keybindings and mouse interaction patterns are consistent with Epiphany, and that the overall user experience is flawless.
You should have good communication skills since you would work with the usability team on a GNOME-wide policy for tabbed applications (i.e. keyboard and mouse interaction), and make sure that Epiphany, Nautilus, gedit and gnome-terminal behave accordingly.
Do some hacking for hugs and fame! 🙂
Update: Jareed Moore volunteered, and already published an analysis of the keybindings and mouse interaction shortcomings. Feel free to add any issues you find.
Yes, this is noise for most of you FLOSS addicts. No, I will not turn my blog into a never-ending off-topic machinery like some of the P.G.O. bloggers.
However, I need your help:
I am looking for a VHS tape of the TV show “da schau her” from Gerhard Polt (early 80s)
Continue reading Desperately looking for an ancient Bavarian TV show: “da schau her”
Manny: you should totally blog this, I’ve been waiting for this kind of view for a long time
OK, official announcement: Yesterday I merged the “Compact View” into Nautilus trunk (which will become Nautilus 2.24). You may have read my blog entry about the view back in February.
It mostly works like the column-wise view of Windows Explorer, but it has more bugs. For instance, under some mysterious conditions the window sometimes constantly re-calculates its size. This bug could be observed very seldom with the “Icon View”, which uses the same infrastructure.
Oh, and it has a preference for toggling whether the column width is determined separately for each column. Otherwise, we use the same width for all columns displayed in a view. We probably still need some fine-tuning for satisfying at least 95% of the users, but it is a good start.
Obligatory screenshot, with variable column width:
Oh, and we are working like mad to fix the regressions due to the GVFS migration. However, hail to GVFS and Alex Larsson. GVFS is just cute. You should all fanboy GVFS! And of course use it in your applications… .
In simliar news, we really need more manpower at Nautilus and GVFS. Cosimo Cechi, A. Walton and Paolo Borelli (Nautilus), and Christian Kellner and Benjamin Otte (GVFS) all do a great development job, but as all big projects there are so many tiny glitches and issues, you just have to help us.
As a start, compile a list of 3-5 (Nautilus or GNOME) issues that are totally cumbersome and fix them, or help us to fix them! 🙂
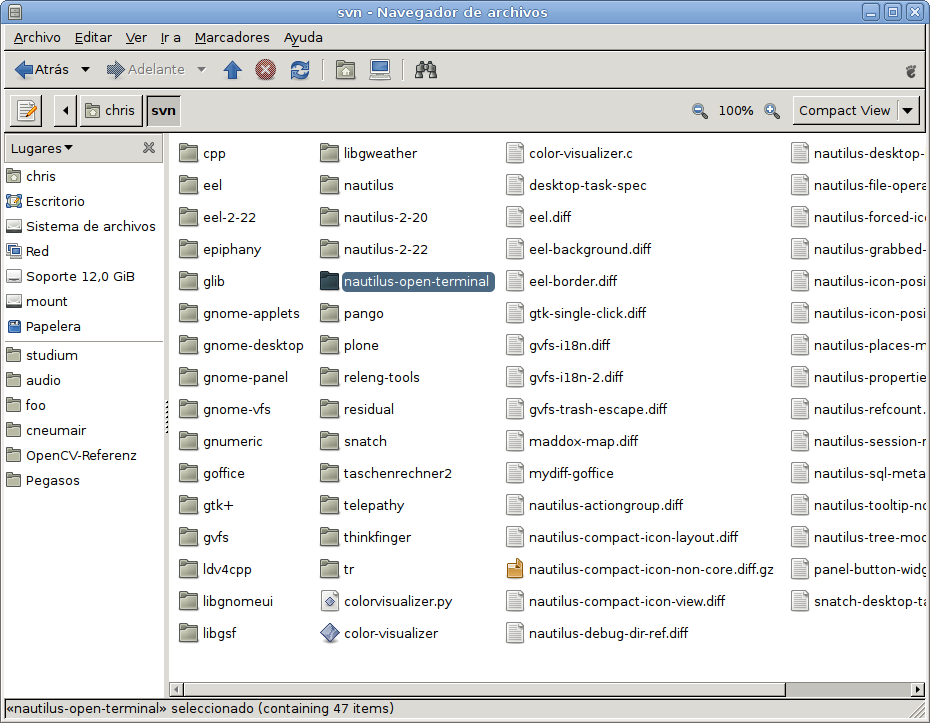
nautilus-open-terminal 0.9 has been released. Get it! It has GIO support, and auto-detects the remote shell for SFTP terminals. Thanks to Alex Larsson and Wouter Bolsterlee!
This release is dedicated to Telltale Games, creator of the “Sam and Max” episode games series, a sequel to the infamous “Sam and Max – Hit the Road” point & click adventure
I’d also like to thank all the nautilus-open-terminal translators, but I seem to be to stupid to insert a well-formated monospace excerpt from the NEWS file here, that is not destroyed by the (otherwise impressive) WordPress layout engine.
Yesterday, I put together a new column-wise view for Nautilus. Here is a screenshot:
![]()
The patchset has been submitted to nautilus-list. I’d appreciate any testing and feedback.
Update: I was asked if it’s possible to reduce the column width. Yes it is: You just have to select the tight layout option, although it’s shared with the traditional icon view ATM. Here is another screenshot:
![]()
Maybe it is a good idea to let the user pick the desired maximum column width, maybe by introducing a drag handle at the left edge of the 2nd column. We could also make this a per-folder option.
Comments appreciated.
In other news, I wonder whether we have any nice backup & user data replay solutions. Of course there is rsync and plain ol’ cp, but assuming one wants to migrate between systems where a different user name is used, it is very desirable to have user data that does not contain absolute paths, and does not contain any $USERNAME, but just raw data and preferences.
To all my blog readers: In case you wonder why I’ve been so silent for months, as a student of electrical engineering I’m holding a tutorial course at university (electromagnetism), and I’m absolving a C++/Qt/OpenCV hands-on training at university that deals with OpenCV-powered pattern recognition and image processing.
The aim is to write an autonomous robot control for a LIDAR+mono-optical+thermo-cam robot that has to absolve various tasks, that require you to think of smart solutions. A very good oppurtunity to improve your practical engineering skills and accomodate to the industry requirements. Not all solutions that are smart are applicable, and vice versa.
Now, my open letter
Dear Google,
it’s great that one can use Google to search through online API documentation. I can enter “gtk_widget_new” and hits on library.gnome.org will show up in the results. This makes Google an effective and omnipresent devhelp-alternative.
However, I have some griefs:
* Often, PageRank thinks the most relevant hits are mailing list posts. This is true only for badly-documented API. One can of course specify site:library.gnome.org, but this is tedious
* Even as you narrow down your results to the official API docs, PageRank fails to get the most relevant/recent documentation, and instead often brings up very outdated documentation (before we had library.gnome.org, often 1.0 platform API docs were preferred!)
What about an”api:…” keyword (like “define:…”) that is associated with an indexer, that is aware of library.gnome.org, docs.trolltech.com, go-mono, meaemo, X11 and MSDN documentation (and also all the POSIX and linux low-level stuff), and knows the various version numbers and flavors of libraries?
You’d do us software developers a major favor, and get even more fanboys! :).
Best regards,
Christian Neumair
You may remember my posting regarding thumbnail caching.
The problem is that all applications using GnomeThumbnail will read the entries ~/.thumbnails/normal or ~/.thumbnails/large [and ~/.thumbnails/failed] synchronously, as the first thumbnail request is made, which means a notable time [more than a few seconds] for a few hundred MB of thumbnails. There is a long-standing bug report about that issue.
Why the cache, in the first place?
The idea was to keep around an in-memory list (a cache) of all available thumbnails, and additionally to store the previously-requested thumbnails in memory, as it is likely that previously-requested thumbnails are used again.
The problematic aspect of the cache is that ~/.thumbnails may contain hundrets of megabytes, and thus be very big. This implies that the cache refresh is very expensive.
First idea: Get rid of cache
My initial idea was to solve this by removing the in-memory cache altogether. While users reported that this solved their problems and didn’t cause any performance impact, this may not be generalized: Currently, the user-visible thumbnail loading time is dominated by the time to synchronously read the thumbs, not by the cache-lookup time. This will not be true anymore as we have asynchronous thumbnail loading in Nautilus [which is not written yet, but should heavily improve performance].
Second idea: Multi-threaded cache voodoo
So the next idea was to use a multi-threaded solution, which would refresh the cache in a worker thread, and circumvent it entirely during refresh when requesting/generating a thumbnail. While it sounds good, it gets really nasty as you realize that POSIX doesn’t specify what happens as a directory changes during readdir(). Assuming you refresh the cache from disk [worker thread], and at the same generate a new thumbnail without using the cache [main thread], you’ll end up with a modified file system and you cannot be sure about the validity of any entries you read – you’d have to reopen the directory and reread it entirely. This means no cache hits during thumbnail generation, i.e. if you open two directories simultanously with Nautilus and the thumbs for one are generated, and the thumbs for the others aren’t, you’ll get no cache hits at all. Maybe we could use file change notification, but it is platform-dependant and we don’t want to explicitly write code against Linux or some other UNIX and have gazillions of #ifdefs in the code for dnotify, inotify etc.
Third idea: (to-be-written?) on-demand in-memory file systems
I think the smartest solution [that happens to mean no work for us, i.e. just drop our cache, cf. first idea] involves finding an on-demand in-memory file system, which forms an ideal cache for many applications. Dear lazyweb, do you know of any FS that does the following:
You’d just mount it to ~/.thumbnails and let the voodoo happen. Yes, this is also platform-dependant, but it can be implemented for all platforms and doesn’t make us depend on the platforms file system capabilities, falling back to a performance-reduced but not memory-intense behavior.
Thanks to the guys at the freenode ##c channel for the fruitful discussion, especially wobster for the POSIX and RAMFS hints.
Comments?
Federico wrote:
Simon Holm Thøgersen looked a bit more into yesterday’s timeline, and he found that Nautilus causes all of ~/.thumbnails to be scanned when creating the desktop window. The thumbnails will need to be read eventually when displaying the files in ~/Desktop, but definitely not when the desktop is being initialized.
This is a very good catch.
I investigated the libgnomeui thumbnailing code. When the first thumbnail is looked up, it seems to read the entire thumbnail directory, and add all existing thumbnail files to the global thumbnail cache, which will cause readdir(), and malloc() calls. It will then save the thumbnail directory’s mtime and a thumbnail is requested, it will stat the entire directory again if a thumbnail is changed (and thus changed the directory’s mtime).
Denoting whether a thumbnail file is present or not is the file system’s job, there is no point in duplicating the FS info in a hash table.
It would IMO be way better to just purge the cache containing all thumbnails, and instead only cache the previously requested ones. We’d directly stat() each thumbnail file, and store and cache the mtime per thumbnail file in a hash table containing only the previouly-seen thumbs, and check whether the requested one matches the cached one.
I’ll do some more investigations and report about my findings, but this looks like it may well be the reason that users report desktop startup speed differences of orders of magnitude, depending on the number of stored thumbnails.
Update
I submitted a libgnomeui patch against the related bug report (#430123). Even with a warm filesystem cache, the subjective Nautilus startup could be significantly reduced with a ~160 MB thumbnail cache.