Last week, Xamarin announced their Xamarin 2.0 product, which contains Xamarin Studio, a brand new version of MonoDevelop. Miguel describes the impressive amount of work that went into Xamarin Studio in his blog post The Making of Xamarin Studio. Xamarin Studio is written in C# and for a large part relies on GTK+ 2.x to make the product cross platform, shipping versions for Mac OS X and Windows, but Xamarin Studio should also run just fine on Linux. As an addition to Miguel’s blog post, I will describe some of the interesting work that we have done under the hood in our ongoing collaboration with Xamarin.
At Lanedo, we have been working with Xamarin for the last 1,5 years to improve the GTK+ stack on the Mac OS X and Windows platforms. This work was based on the GTK+ 2.x stack, because MonoDevelop is a GTK+ 2.x application. We have made an effort to upstream all fixes and improvements that were suitable to be committed in the upstream projects. Where possible, fixes have also been merged into the GTK+ 3.x branch. Furthermore, we have helped with the implementation of the gorgeous GTK+ theme (available in the xamarin-gtk-theme module on GitHub) that is used in the product and makes Xamarin Studio look like a native application, and not look completely out of place on Mac OS X or Windows like GTK+ applications typically do. In my opinion, the approach that Xamarin has taken for theming will be useful for many other GTK+ applications running on Mac OS X as well.
Most of the work we have done was under the hood, but that does not make it less interesting. Some of the things we have worked on are:
- Many, many annoying interaction problems and crasher bugs with GTK+ on Mac OS X have been fixed. Such as non-working tree view expanders, broken key navigation, issues with window resizing, and gaps in clipboard support.
- Keyboard fixes for Mac OS X: everything with respect to keyboard modifiers and key mapping has been reviewed, several problems with typing dead accents, keyboard accelerators, etc., have been resolved.
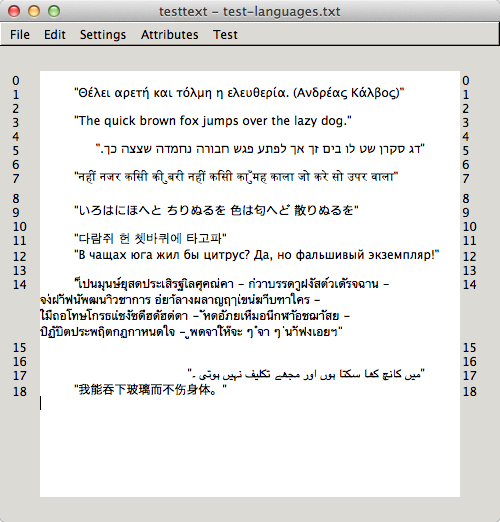
- Xamarin sponsored the work to properly implement font fallbacks in Pango’s CoreText backend. As a result, text involving glyphs from different scripts will now render beautifully on Mac OS X.
- We have worked very hard to make scrolling behave as native as possible on Mac OS X. Support for representing "precise deltas" from NSEvents in GdkEvents has been written, which already gives you much smoother scrolling on Apple hardware and support for momentum events (built-in kinetic scrolling).
The next step was to have overlaid scrollbars and rubber banding, like native applications on Mac OS X Lion and higher. To achieve this, we actually place a CALayer on top of the NSView in which the GTK+ application is drawn, and draw the scroll bars in this layer. We have tweaked the event handling so that information about the gesture phase is considered, in order to be able to implement rubber banding. Unfortunately, this code is not in a state such that it can be upstreamed.
Performance problems were uncovered in how GDK handled scrolling on OS X, apparently, much more of the widgets was being redrawn than necessary. These problems have been fixed and upstreamed, and scrolling is now pretty smooth.
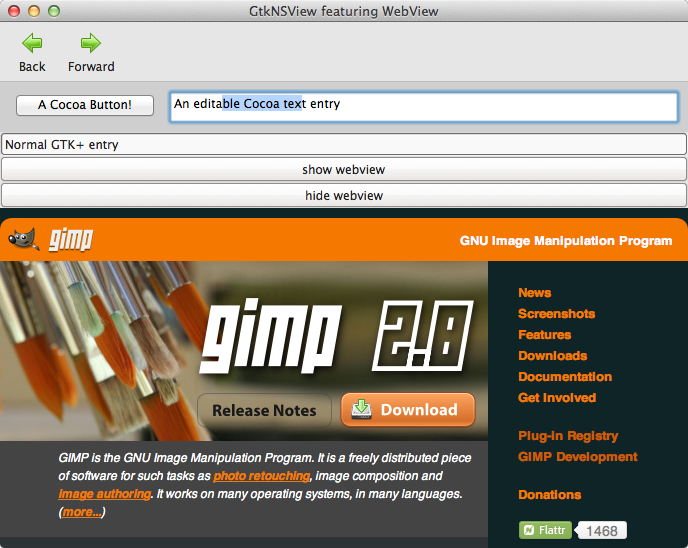
- Work has been done on a GtkNSView widget, which allows native Cocoa widgets to be embedded in a GTK+ application. For example, it is possible to embed a native WebKit control in a GTK+ application. Work on this widget is still ongoing in Bug 619155.
- Some improvements were made so that GTK+ applications render at higher resolution on Retina displays. This includes work to render stock icons at a higher resolution.
- A few Windows problems have been resolved, including a crash with Windows IME, font substitution and other minor problems.
We have very much enjoyed working with Xamarin over the last 1,5 years and are grateful for the large contributions they have made to the involved upstream projects. In my opinion, the GTK+ 2.24 branch is these days in a very good shape for cross platform application development for the Linux, Windows and Mac OS X platforms. The work that has been done has immediately been beneficial for other applications, for example the native GIMP application for Mac OS X has been much improved. These days it is available as a proper application bundle in a DMG installer (due to the work by Clayton Walker) from the main GIMP download page and it works very well!
We look forward to the continued collaboration with Xamarin to further improve the GTK+ stack for use by Xamarin Studio!