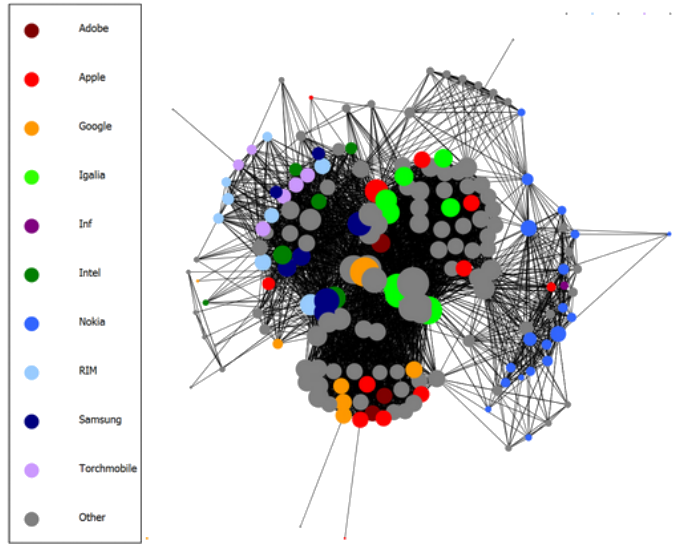
Nearly five years ago, when I was in grad school, I stumbled across the paper Collaboration in the open-source arena: The WebKit case when trying to figure out what I would do for a course project in network theory (i.e. graph theory, not computer networking; I’ll use the words “graph” and “network” interchangeably). The paper evaluates collaboration networks, which are graphs where collaborators are represented by nodes and relationships between collaborators are represented by edges. Our professor had used collaboration networks as examples during lecture, so it seemed at least mildly relevant to our class, and I wound up writing a critique on this paper for the class project. In this paper, the authors construct collaboration networks for WebKit by examining the project’s changelog files to define relationships between developers. They perform “community detection” to visually group developers who work closely together into separate clusters in the graphs. Then, the authors use those graphs to arrive at various conclusions about WebKit (e.g. “[e]ven if Samsung and Apple are involved in expensive patent wars in the courts and stopped collaborating on hardware components, their contributions remained strong and central within the WebKit open source project,” regarding the period from 2008 to 2013).
At the time, I contacted the authors to let them know about some serious problems I found with their work. Then I left the paper sitting in a short-term to-do pile on my desk, where it has been sitting since Obama was president, waiting for me to finally write this blog post. Unfortunately, nearly five years later, the authors’ email addresses no longer work, which is not very surprising after so long — since I’m no longer a student, the email I originally used to contact them doesn’t work anymore either — so I was unable to contact them again to let them know that I was finally going to publish this blog post. Anyway, suffice to say that the conclusions of the paper were all correct; however, the networks used to arrive at those conclusions suffered from three different mistakes, each of which was, on its own, serious enough to invalidate the entire work.
So if the analysis of the networks was bogus, how did the authors arrive at correct conclusions anyway? The answer is confirmation bias. The study was performed by visually looking at networks and then coming to non-rigorous conclusions about the networks, and by researching the WebKit community to learn what is going on with the major companies involved in the project. The authors arrived at correct conclusions because they did a good job at the latter, then saw what they wanted to see in the graphs.
I don’t want to be too harsh on the authors of this paper, though, because they decided to publish their raw data and methodology on the internet. They even published the python scripts they used to convert WebKit changelogs into collaboration graphs. Had they not done so, there is no way I would have noticed the third (and most important) mistake that I’ll discuss below, and I wouldn’t have been able to confirm my suspicions about the second mistake. You would not be reading this right now, and likely nobody would ever have realized the problems with the paper. The authors of most scientific papers are not nearly so transparent: many researchers today consider their source code and raw data to be either proprietary secrets to be guarded, or simply not important enough to merit publication. The authors of this paper deserve to be commended, not penalized, for their openness. Mistakes are normal in research papers, and open data is by far the best way for us to be able to detect mistakes when they happen.
The rest of this blog post is a simplified version of my original school paper from 2016. I’ve removed maybe half the original content, including some flowery academic language and unnecessary references to class material (e.g. “community detection was performed using fast modularity maximization to generate an alternate visualization of the network,” good for high scores on class papers, not so good for blog posts). But rewriting everything to be informal takes a long time, and I want to finish this today so it’s not still on my desk five more years from now, so the rest of this blog post is still going to be much more formal than normal. Oh well. Tone shift now!
We (“we” means “I”) examine various methodological issues discovered by analyzing the paper. The first section discusses the effects on the collaboration network of choosing a poor definition of collaboration. The second section discusses a major source of error in detecting the company affiliation of many contributors. The third section describes a serious mistake in the data collection process. Each of these issues is quite severe, and any one alone calls into question the validity of the entire study. It must be noted that such issues are not necessarily unique to this paper, and must be kept in mind for all future studies that utilize collaboration networks.
Mistake #1: Poorly-defined Collaboration
The precise definition used to model collaboration has tremendous impact on the usefulness of the resultant collaboration network. Many collaboration networks are built using definitions of collaboration that are self-evidently useful, where there is little doubt that edges in the network represent real-world collaboration. The paper adopts an approach to building collaboration networks where developers are represented by nodes, and an edge exists between two nodes if the corresponding developers modified the same source code file during the time period under consideration for the construction of the network. However, it is not clear that this definition of collaboration is actually useful. Consider that it is a regular occurrence for developers who do not know each other and may have never communicated to modify the same files. Consider also that modifying a common file does not necessarily reflect any shared interest in a particular portion of the software project. For instance, a file might be modified when making an interface change in another file, or when fixing a build error occurring on a particular platform. Such occurrences are, in fact, extremely common in the WebKit project. Additionally, consider that there exist particular source code files that are unusually central to the project, and must be modified more frequently than other files. It is highly likely that almost all developers will at one point or another make some change in such a file, and therefore be connected via a collaboration edge to all other developers who have ever modified that file. (My original critique shows a screenshot of the revision history of WebPageProxy.cpp, to demonstrate that the developers modifying this file were working on unrelated projects.)
It is true, as assumed by the paper, that particular developers work on different portions of the WebKit source code, and collaborate more with particular other developers. For instance, developers who work for the same company typically, though not always, collaborate most with other developers from that same company. However, the paper’s naive definition of collaboration should ensure that most developers will be considered to have collaborated equally with most other developers, regardless of the actual degree of collaboration. For instance, consider developers A and B who regularly collaborate on a particular source file. Now, developer C, who works on a platform that does not use this file and would not ordinarily need to modify it, makes a change to some cross-platform interface in another file that requires updating this file. Developer C is now considered to have collaborated with developers A and B on this file! Clearly, this is not a desirable result, as developers A and B have collaborated far more on the development of the file. Moreover, consider that an edge exists between two developers in the collaboration network if they have ever both modified any file anywhere in WebKit during the time period under review; then we can expect to form a network that is almost complete (a “full” graph where edges exists between most nodes). It is evident that some method of weighting collaboration between different contributors would be desirable, as the unweighted collaboration network does not seem useful.
One might argue that the networks presented in the paper clearly show developers exist in subcommunities on the peripheries of the network, that the network is clearly not complete, and that therefore this definition of collaboration sufficed, at least to some extent. However, this is only due to another methodological error in the study. Mistake #3, discussed later, explains how the study managed to produce collaboration networks with noticeable subcommunities despite these issues.
We note that the authors chose this same definition of collaboration in their more recent work on OpenStack, so there exist multiple studies using this same flawed definition of collaboration. We speculate that this definition of collaboration is unlikely to be more suitable for OpenStack or for other software projects than it is for WebKit. The software engineering research community must explore alternative models of collaboration when undertaking future studies of software development collaboration networks in order to more accurately reflect collaboration.
Mistake #2: Misdetected Contributor Affiliation
One difficulty when building collaboration networks is the need to correctly match each contributor with the correct company affiliation. Although many free software projects are dominated by unaffiliated contributors, others, like WebKit, are primarily developed by paid contributors. Looking at the number of times a particular email domain appears in WebKit changelog entries made during 2015, most contributors commit using corporate emails, but many developers commit to WebKit using personal email accounts, such as Gmail accounts; additionally, many developers use generic webkit.org email aliases, which were previously available to active WebKit contributors. These developers may or may not be affiliated with companies that contribute to the project. Use of personal email addresses is a source of inaccuracy when constructing collaboration networks, as it results in an undercount of corporate contributions. We can expect this issue has led to serious inaccuracies in the reported collaboration networks.
This substantial source of error is neither mentioned nor accounted for; all contributors using such email accounts were therefore miscategorized as unaffiliated. However, the authors clearly recognized this issue, as it has been accounted for in their more recent work covering OpenStack by cross-referencing email addresses from git revision history with a database containing corporate affiliations maintained by the OpenStack Foundation. Unfortunately, no such effort was made for the WebKit data set.
The WebKit project was previously dominated by contributors with chromium.org email domains. This domain is equivalent to webkit.org in that it can be used by contributors to the Chromium project regardless of corporate affiliation; however, most contributors with Chromium emails are actually Google employees. The high use of Chromium emails by Google employees appears to have led to a dramatic — by roughly an entire order of magnitude — undercount of Google’s contributors to the WebKit project, as only contributors with google.com emails were considered to be Google employees. The vast majority of Google employees used chromium.org emails, and so were counted as unaffiliated developers. This explains the extraordinarily high number of unaffiliated developers in the networks presented by the paper, despite the fact that WebKit development is, in reality, dominated by corporate contributors.
Mistake #3: Missing Most Changelog Data
The paper incorrectly claims to have gathered its data from both WebKit’s Subversion revision history and from its changelog files. We must draw a distinction between changelog entries and Subversion revision history. Changelog entries are inserted into changelog files that are committed into the Subversion repository; they are completely separate from the Subversion history. Each subproject within the WebKit project has its own set of changelog files used to record changes under the corresponding directory.
In fact, the paper processed only the changelog files. This was actually a good choice, as WebKit’s changelog files are much more accurate than the Subversion history, for two reasons. Firstly, it is easy for a contributor to change the email address entered into a changelog file, e.g. after a change in company affiliation. However, it is difficult to change the email address used to commit to Subversion, as this requires requesting a new Subversion account from the Subversion administrator; accordingly, contributors are more likely to use older email addresses, lacking accurate company affiliation, in Subversion revisions than in changelog files. Secondly, many Subversion revisions are not directly committed by contributors, but rather are actually committed by the commit queue bot, which runs various tests before committing the revision. Subversion revisions are also, more rarely, committed by a completely different contributor than the patch author. In both cases, the proper contributor’s name will appear in only the changelog file, and not the Subversion data. Some developers are dramatically more likely to use the commit queue than others. Various other reviews of WebKit contribution history that examine data from Subversion history rather than from changelog files are flawed for this reason. Fortunately, by relying on changelog files rather than Subversion metadata, the authors avoid this problem.
Unfortunately, a serious error was made in processing the changelog data. WebKit has many different sets of changelog files, stored in various project subdirectories (JavaScriptCore, WebCore, WebKit, etc.), as well as toplevel changelogs stored in the root directory of the project. Regrettably, the authors were unaware of the changelogs in subdirectories, and based their analysis only on the toplevel changelogs, which contain only changes that occurred in subdirectories that lack their own changelog files. In practice, this inadvertently restricted the scope of the analysis to a very small minority of changes, primarily to build system files, manual tests, and the WebKit website. That is, the reported collaboration networks do not reflect collaboration on any actual source code files. All source code files are contained in subdirectories with their own changelog files, and therefore no source code files were actually considered in the analysis of collaboration on source code changes.
We speculate that the analysis’s focus on build system files likely exaggerates the effects of clustering in the network, as different companies used different build systems and thus were less likely to edit the build systems used by other companies, and that an analysis based on the correct data would display less of a clustering effect. Certainly, there would be dramatically more edges in the already-dense networks, because an edge exists between two developers if there exists any one file in WebKit that both developers have modified. Omitting all of the source code files from the analysis therefore dramatically reduces the likelihood of edges existing between nodes in the network.
Conclusion
We found that the original study was impacted by an unsuitable definition of collaboration used to build the collaboration networks, severe errors in counting contributor affiliation (including the classification of most Google employees as unaffiliated developers), and the omission of almost all the required data from the analysis, including all data on modifications to source code files. The authors constructed and studied essentially meaningless networks. Nevertheless, the authors were able to derive many accurate conclusions about the WebKit project from their inaccurate collaboration networks. Such conclusions illustrate the dangers of seeking to find particular meanings or explanations through visual inspection of collaboration networks. Researchers must work forwards from the collaboration networks to arrive at their conclusions, rather than backwards by attempting to match the networks to conclusions gained from prior knowledge.
Original Report
Wow, OK, you actually read this far? Since this blog post criticizes an academic paper, and since this blog post does not include various tables and examples that support my arguments, I’ve attached my original analysis in full. It is a boring, student-quality grad school project written with the objective of scoring the highest-possible grade in a class rather than for clarity, and you probably don’t want to look at it unless you are investigating the paper in detail. (If you download that, note that I no longer work for Igalia, and the paper was not authorized by Igalia either; I used my company email to disclose my affiliation and maybe impress my professor a little.) Phew, now I can finally remove this from my desk!