
Thanks to Sebastian Dröge there is a new thing in GStreamer called streamid. It basically gives all streams inside a given file a unique id, making files with multiple streams a lot easier to deal with. This streamid is also supported by the GStreamer discoverer object. So once you identified the contents of a file with discoverer you can be sure to grab the exact stream you want coming out of (uri)decodebin by checking the pad for the streamid. The most common usecase for this is of course files with multiple audio streams in different languages.
From the output of Discoverer the stream id is really easy to get:
On the stream object you get out of Discoverer you just run a:
stream.get_stream_id()
On the pad you get from decodebin or uridecodebin the patch is a bit more convoluted, but not
to hard once you know how (there might be some kind of convenience API added for this at some point).
Before you connect the pad you get from the bin you attach a pad to it like this:
src_pad.add_probe(Gst.PadProbeType.EVENT_DOWNSTREAM, self.padprobe, None)
Then you in the function you define you can extract the stream_id with the parse_stream_start call as seen below:
def padprobe(self, pad, probeinfo, userdata):
event = probeinfo.get_event()
eventtype=event.type
if eventtype==Gst.EventType.STREAM_START:
streamid = event.parse_stream_start()
return Gst.PadProbeReturn.OK
I been using this code in my local copy of Transmageddon to start implementing support for files with multiple audio streams (also supporting multiple video streams would be easy, but I am not sure how useful it would be). Got a screenshot of my current development snapshot below, but I am still trying to figure out what would be a nice way to present it. The current setup will look quite crap if the incoming file got more than a few audio streams. Suggestions welcome :)
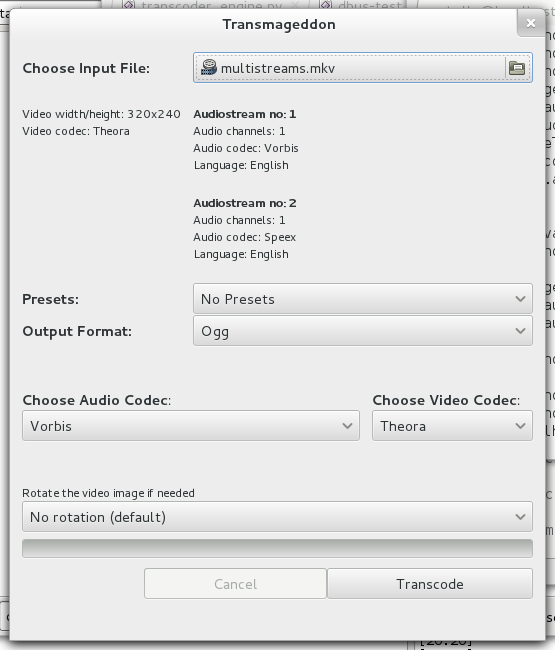
Transmageddon multistream development snapshot
Why not a treeview? People could also select what streams they want to be added to a transcoded file (if target container supports that).
Why is GstDiscoverer 30-50x slower than taglib?
This is a really big problem!
I haven’t profiled it, but Discoverer is a very different thing than taglib. There are tag extraction API’s in GStreamer which you should use for getting tags, and which you could compare to taglib, but Discoverer is not that. Discoverer is for actually analyzing the incoming media streams providing detailed information about the streams, which include tag information, but also technical details about the codecs and so on.
Ok. Which one is the tag extraction API in GStreamer comparable to taglib (synchronous API)?
I want to try it.
Why is it slower? Partly because it always plugs decoders and decodes data, even if that is not required for just reading tags and metadata. Someone needs to add a mode to it that makes it stop autoplugging elements as soon as all the interesting metadata has been extracted (tags and stream info like width/height/codec/framerate or sample rate/channels). Basically what the tagreadbin used by Nokia (and in bugzilla) did/does.
For gst-mediainfo I used tabs. There is one notebook for audio, one for video and one for subtitles.