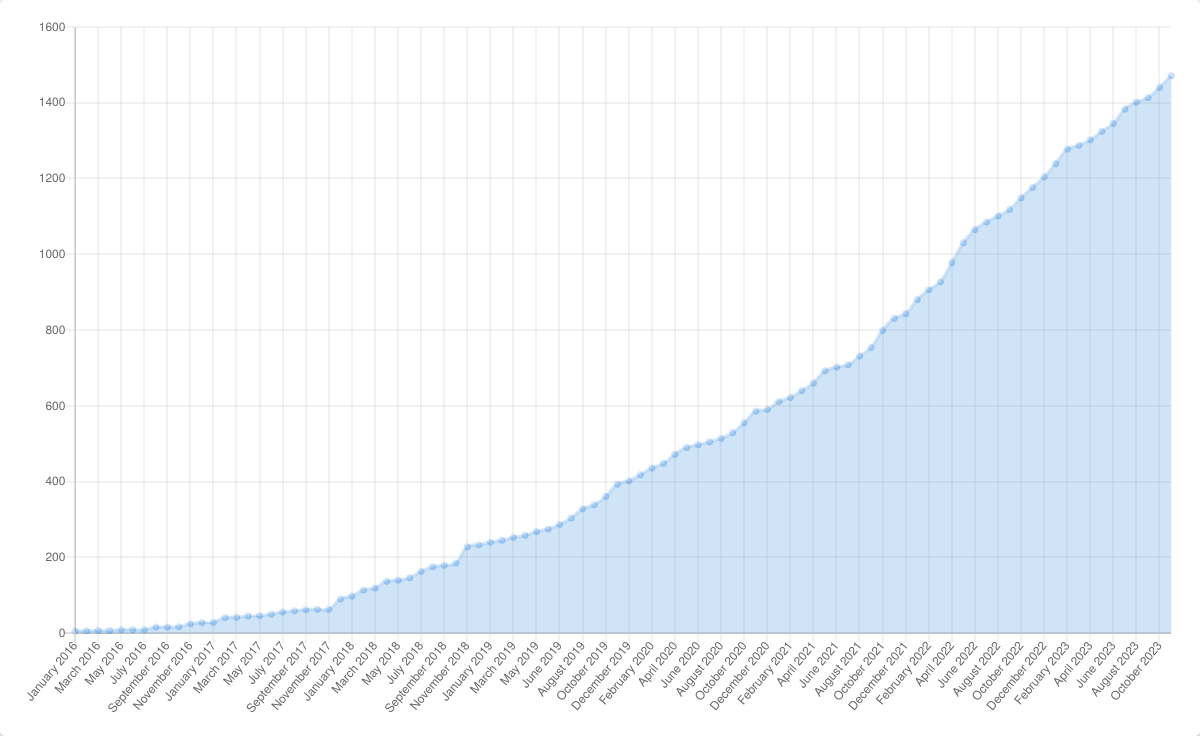
At the moment, when a vendor decides to support a new device using the LVFS in Linux or ChromeOS they have to do a few things:
- Write a plugin for fwupd that understands how to copy the firmware into the specific device
- Add a quirk entry into a file that matches a specific VID/PID or VEN/DEV to tell fwupd what plugin to load for this new device
- Actually ship that fwupd version in the next ChromeOS release, or convince Linux distros to rebase to the new version
- Get an account on the LVFS
- Upload some firmware, test it, then push it to end-users
Then the next device comes along a few months later. This time the vendor only has to update a quirk file with a new VID/PID, convince the distributor to ship the new fwupd update and then push the new firmware. Lets look at the timescales for each thing:
- Write plugin: Depends on programmer and GLib proficiency, but typically a few weeks
- Add quirk entry: 2 minutes to write, usually less than 12 hours for upstream review
- Ensure latest fwupd is shipped (~30 days for upstream, +~10 days for Fedora, +several months for Ubuntu, and +almost infinity for Debian stable
- Get LVFS account: 10 minutes for me to add, usually a few days to get legal clearance and to do vendor checks
- Upload firmware: Less than 5 minutes to write release notes and upload the file, and then stable remote is synced every 6 hours
So the slow part is step 3, and it’s slower than the others by several orders of magnitude – and it’s also the part that we have to do even when adding just one more VID/PID in the quirk file. We’ve ruled out shipping quirk entries in the metadata as it means devices don’t enumerate when offline (which is a good chunk of the fwupd userbase).
So what can we do? We already support two plugins that use the class code, rather than the exact VID/PID. For example, this DFU entry means “match any USB device with class 0xFE (application specific) and subclass 0x01” which means these kind of devices don’t need any updates (although, they still might need a quirk if they are non-complaint, for example needing Flags = detach-for-attach) – but in the most case they just work:
[USB\CLASS_FE&SUBCLASS_01]
Plugin = dfu
The same can be done for Fastboot devices, matching class 0xFF (vendor specific), subclass 0x42 (sic) and protocol 0x03, although the same caveat for non-compliant devices that need things like FastbootOperationDelay = 250:
[USB\CLASS_FF&SUBCLASS_42&PROT_03]
Plugin = fastboot
I think we should move more into this kind of “device opts into fwupd plugin” direction, so the obvious answer is to somehow have a registry of class/subclass/protocol values. The USB consortium defines a few (e.g. class 0xFE subclass 0x02 is an IRDA bridge – remember those!) but the base class 0xFF is completely unspecified. It doesn’t seem right to hijack it, and you only get 255 possible values – and sometimes you really do want the class/subclass to be the correct things, e.g. base class 0x10 is “Audio/Video Devices” for example.
There is something extra we can use, the Microsoft OS Descriptors which although somewhat proprietary are still mostly specified and supported in Linux. The simpler version 1 specification could be used, and although we could squeeze FWUPDPLU or FWUPDFLA as the CompatibleID, we couldn’t squeeze the plugin name (e.g. logitech-bulkcontroller) or the GUID (16 bytes) in an 8 byte Sub-compatibleID. I guess we could just number the plugins, or use half-a-GUID or something, but then it all starts to get somewhat hacky. Also, as a final nail-in-the-coffin, some non-compliant devices also don’t respond well (as in, they hang, and stop working…) when probing the string index of 0xEE – and so it’s also not without risk. If we have an “allowlist or denylist of devices that don’t support Microsoft OS Descriptors” (like Microsoft had to do) then we’re either back at updating the quirk file for each device added – which is what we wanted to avoid in the first place – or we risk regressions on end-user machines. So pass.
The version 2 specification is somewhat more helpful. It defines a new device capability that can return variable length properties, using a UUID as a key – although we do need to use the newish “BOS” descriptor. This is only available in devices using USB 2.1 and newer, although that’s probably the majority of devices in use these days. If I understand correctly, using a USB-C requires the device to support USB-2 and above, so that’s probably most new-design modern devices covered in reality.
Lets dig into this specification a bit: Some USB 2/3 devices already export a BOS “Binary Object Store” descriptor, which includes things like Wireless USB details, USB 2.0 extensions, SuperSpeed USB connection details and a Container ID. We could certainly hijack a new bDevCapabilityType which would allow us to store a binary blob (e.g. Plugin=foobarbaz\nFlags=QuirkValueHere\n) but that doesn’t seem super awesome to just use a random out-of-specification (looking at you fastboot…) value.
What the BOS descriptor does give us is the ability to use the platform capability descriptor, which is bDevCapabilityType=0x05 according to Microsoft OS Descriptors 2.0 Specification. For UUID D8DD60DF-4589-4CC7-9CD2-659D9E648A9F, this is identified as a structured blob of data Windows usually uses to put workarounds like the suspend mode of the device and that kind of thing.
The descriptor allows us to create a “descriptor set” which is really a posh way of saying “set these per-device registry keys when plugged in” which we could certainly (ab?)use for setting fwupd quirks and matching to plugins. It’s literally the REG_EXPAND_SZ, REG_DWORD things you can see in regedit.exe. Worst case you plug the device into Windows, and you get a few useless REG_SZ’s created of things like “fwupd.Plugin=logitech_hidpp” which Windows will ignore (or we hope so) and that we can use in fwupd to remove the need for most of the quirk files completely. Of course, you’ll still need a new enough fwupd that actually contains the device plugin update code, but we can’t do anything at all about that unless someone invents an OpenHardware time machine.
Can anybody see a problem? If so, tell me now as I’m going to prototype this next week. Of course, it needs vendor buy-in but I think the LVFS is at a point where we can tell them what to do. :) Comments welcome.