With the industry support from HP (and our existing sponsors of Lenovo, Dell, Framework, OSFF and of course Linux Foundation and Red Hat) we can turbo-charge the growth of the LVFS even more. Thanks!
Over 145 million firmware updates have been deployed now, from over a hundred different vendors to millions of different Linux devices.
With the huge industry support from Lenovo and Dell (and our existing sponsors of Framework, OSFF, and of course both the Linux Foundation and Red Hat) we can build this ecosystem stronger and higher than before; we can continue the great work we’ve done long into the future.
tl;dr: I’m asking the biggest users of the LVFS to sponsor the project.
The Linux Foundation is kindly paying for all the hosting costs of the LVFS, and Red Hat pays for all my time — but as LVFS grows and grows that’s going to be less and less sustainable longer term. We’re trying to find funding to hire additional resources as a “me replacement” so that there is backup and additional attention to LVFS (and so that I can go on holiday for two weeks without needing to take a laptop with me).
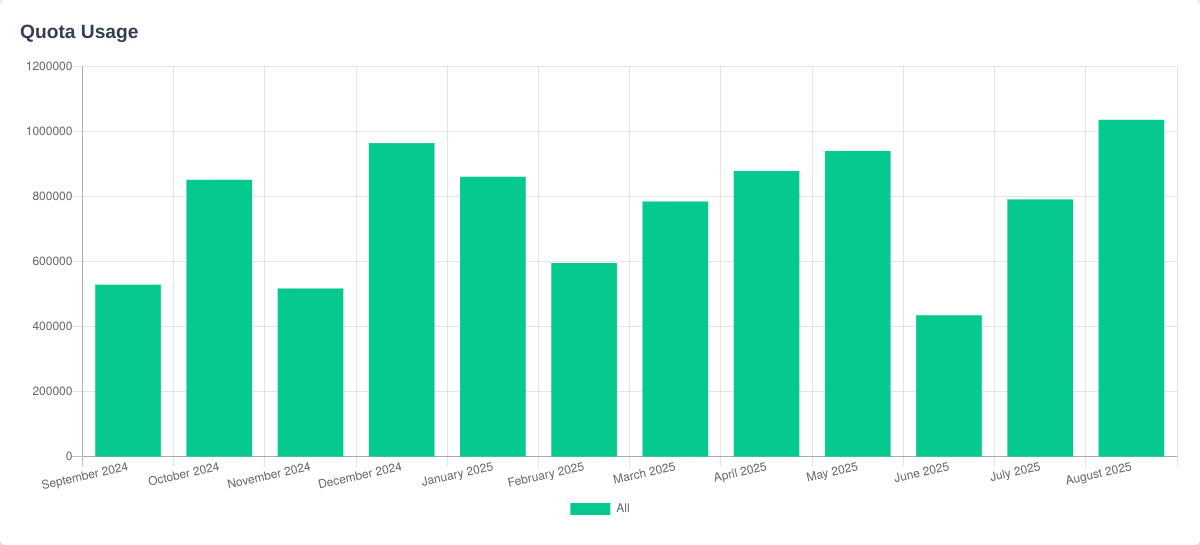
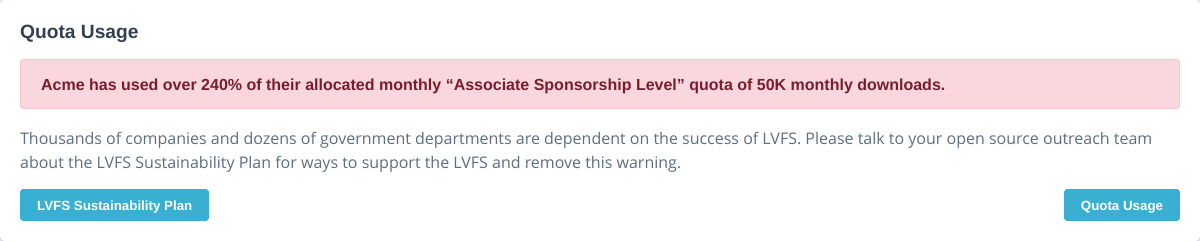
This year there will be a fair-use quota introduced, with different sponsorship levels having a different quota allowance. Nothing currently happens if the quota is exceeded, although there will be additional warnings asking the vendor to contribute. The “associate” (free) quota is also generous, with 50,000 monthly downloads and 50 monthly uploads. This means that almost all the 140 vendors on the LVFS should expect no changes.
Vendors providing millions of firmware files to end users (and deriving tremendous value from the LVFS…) should really either be providing a developer to help write shared code, design abstractions and review patches (like AMD does) or allocate some funding so that we can pay for resources to take action for them. So far no OEMs provide any financial help for the infrastructure itself, although two have recently offered — and we’re now in a position to “say yes” to the offers of help.
I’ve written a LVFS Project Sustainability Plan that explains the problem and how OEMs should work with the Linux Foundation to help fund the LVFS.
I’m aware funding open source software is a delicate matter and I certainly do not want to cause anyone worry. We need the LVFS to have strong foundations; it needs to grow, adapt, and be resilient – and it needs vendor support.
Draft timeline, which is probably a little aggressive for the OEMs — so the dates might be moved back in the future:
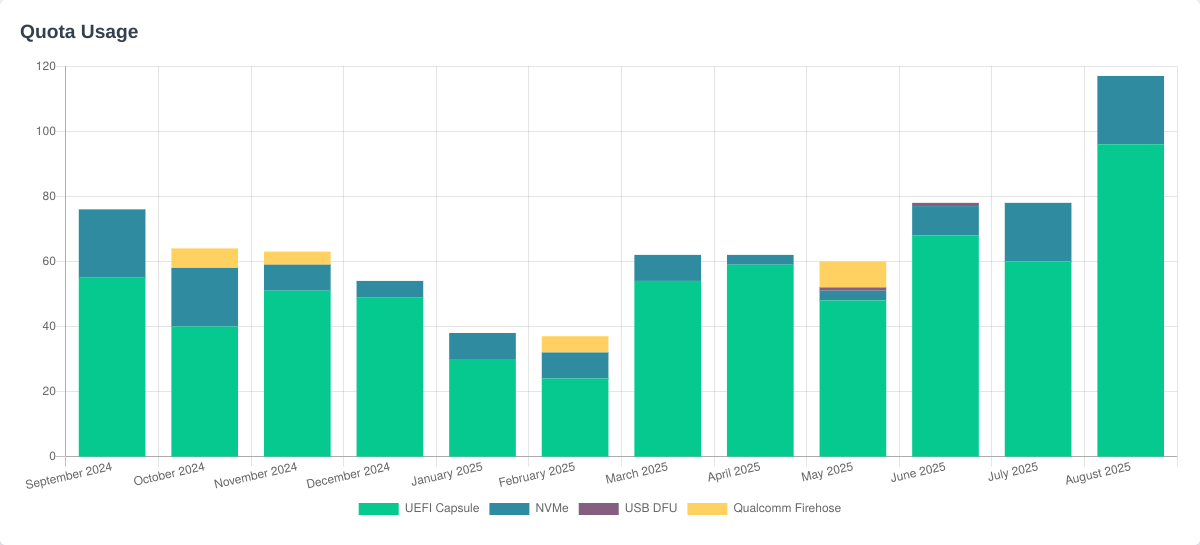
APR 2025: We started showing the historical percentage “fair use” download utilization graph in vendor pages. As time goes on this will also be recorded into per-protocol sections too.
JUL 2025: We started showing the historical percentage “fair use” upload utilization, also broken into per-protocol sections:
JUL 2025: We started restricting logos on the main index page to vendors joining as startup or above level — note Red Hat isn’t sponsoring the LVFS with money (but they do pay my salary!) — I’ve just used the logo as a placeholder to show what it would look like.
AUG 2025: I created this blogpost and sent an email to the lvfs-announce mailing list.
AUG 2025: We allow vendors to join as startup or premier sponsors shown on the main page and show the badge on the vendor list
APR 2026: Start showing over-quota warnings on the per-firmware pages
APR 2026: Turn off detailed per-firmware analytics to vendors below startup sponsor level
AUG 2026: Turn off access to custom LVFS API for vendors below Startup Sponsorship level, for instance:
/lvfs/component/{}/modify/json
/lvfs/vendors/auth
/lvfs/firmware/auth
DEC 2026: Limit the number of authenticated automated robot uploads for less than Startup Sponsorship levels.
A few weeks ago I was invited to talk about firmware updates for servers using fwupd/LVFS at Prem’Day 2025. I gave the hardware vendors a really hard time, and got lots of instant feedback from customers in the the audience from the “little green thumbs” that people could raise. The main takeaway from the Prem’Day community seemed to be that proprietary tooling adds complexity without value, and using open ecosystems enable users to better operate their infrastructure.
Since getting back to the UK I’ve had some really interesting discussions with various companies; there might be some nice announcements soon.
I’ve just tagged fwupd 2.0.4 — with lots of nice new features, and most importantly with new protocol support to allow applying the latest dbx security update.
The big change to the uefi-dbx plugin is the switch to an ISO date as a dbx version number for the Microsoft KEK.
The original trick of ‘count the number of Microsoft-owned hashes‘ worked really well, just until Microsoft started removing hashes in the distributed signed dbx file. In 2023 we started ‘fixing up‘ the version based on the last-added checksum to make the device have an artificially lower version than in reality. This fails with the latest DBXUpdate-20241101 update, where frustratingly, more hashes were removed than added. We can’t allow fwupd to update to a version that’s lower than what we’ve got already, and it somewhat gave counting hashes idea the death blow.
Instead of trying to map the hash into a low-integer version, we now use the last-listed hash in the EFI signature list to map directly to an ISO date, e.g. 20250117. We’re providing the mapping in a local quirk file so that the offline machine still shows something sensible, but are mainly relying on the remote metadata from the LVFS that’s always up to date. There’s even more detail in the plugin README for the curious.
We also changed the update protocol from org.uefi.dbx to org.uefi.dbx2 to simplify the testing matrix — and because we never want version 371 upgrading to 20230314 automatically — as that would actually be a downgrade and difficult to explain.
If we see lots of dbx updates going out with 2.0.4 in the next few hours I’ll also backport the new protocol into 1_9_X for the soon-to-be-released 1.9.27 too.
You might be surprised to hear that closed source firmware typically contains open source dependencies. In the case of EDK II (probably the BIOS of your x64 machine you’re using now) it’s about 20 different projects, and in the case of coreboot (hopefully the firmware of the machine you’ll own in the future) it’s about another 10 — some overlapping with EDK II. Examples here would be things like libjpeg (for the OEM splash image) or libssl (for crypto, but only the good kind).
It makes no sense for each person building firmware to write the same SBOM for the OSS code. Moving the SBOM upstream means it can be kept up to date by the same team writing the open source code. It’s very similar to what we encouraged desktop application developers to do with AppStream metadata a decade or so ago. That was wildly successful, so maybe we can do the same trick again here.
My proposal would to submit a sbom.cdx.json to each upstream project in CycloneDX format, stored in a location amenable to the project — e.g. in ./contrib, ./data/sbom or even in the root project folder. The location isn’t important, only the file suffix needs to be predictable.
Notice the CycloneDX word there not SPDX — the latter is great for open source license compliance, but I was only able to encode 43% of our “example firmware SBOM” into SPDX format, even with a lot of ugly hacks. I spent a long time trying to jam a round peg in a square hole and came to the conclusion it’s not going to work very well. SPDX works great as an export format to ensure license compliance (and the uswid CLI can already do that now…) but SPDX doesn’t work very well as a data source. CycloneDX is just a better designed format for a SBOM, sorry ISO.
Let’s assume we check in a new file to ~30 projects. With my upstream-maintainer hat on, nobody likes to manually edit yet-another-file when tagging releases, so I’m encouraging projects shipping a CycloneDX sbom.cdx.json to use some of the auto-substituted tokens, e.g.
@VCS_TAG@ → git describe --tags --abbrev=0 e.g. 1.2.3
@VCS_VERSION@ → git describe --tags e.g. 1.2.3-250-gfa2371946
@VCS_BRANCH@ → git rev-parse --abbrev-ref HEAD e.g. staging
@VCS_COMMIT@ → git rev-parse HEAD e.g. 3090e61ee3452c0478860747de057c0269bfb7b6
@VCS_SBOM_AUTHORS@ → git shortlog -n -s -- sbom.cdx.json e.g. Example User, Another User
@VCS_SBOM_AUTHOR@ → @VCS_SBOM_AUTHORS@[0] e.g. Example User
@VCS_AUTHORS@ → git shortlog -n -s e.g. Example User, Another User
@VCS_AUTHOR@ → @VCS_AUTHORS@[0] e.g. Example User
Using git in this way during the built process allows us to also “fixup” SBOM files with either missing details, or when the downstream ODM patches the project to do something upstream wouldn’t be happy with shipping upstream.
For fwupd (which I’m using as a cute example, it’s not built into firmware…) the sbom.cdx.json file would be something like this:
Putting it all together means we can do some pretty clever things assuming we have a recursive git checkout using either git modules, sub-modules or sub-projects:
And then we have a sbom.cdx.json that we can use as an input file used for building the firmware blob. If we can convince EDK2 to merge the additional sbom.cdx.json for each built module then it all works like magic, and we can build the 100% accurate external SBOM into the firmware binary itself with no additional work. Comments most welcome.
We’re trying to increase the fwupd coverage score, so we can mercilessly refactor and improve code upstream without risks of regressions. To do this we run thousands of unit tests for each part of the libfwupdpublic API and libfwupdpluginprivate API. This gets us a long way, but what we really want to do is emulate the end-to-end firmware update of every real device we support.
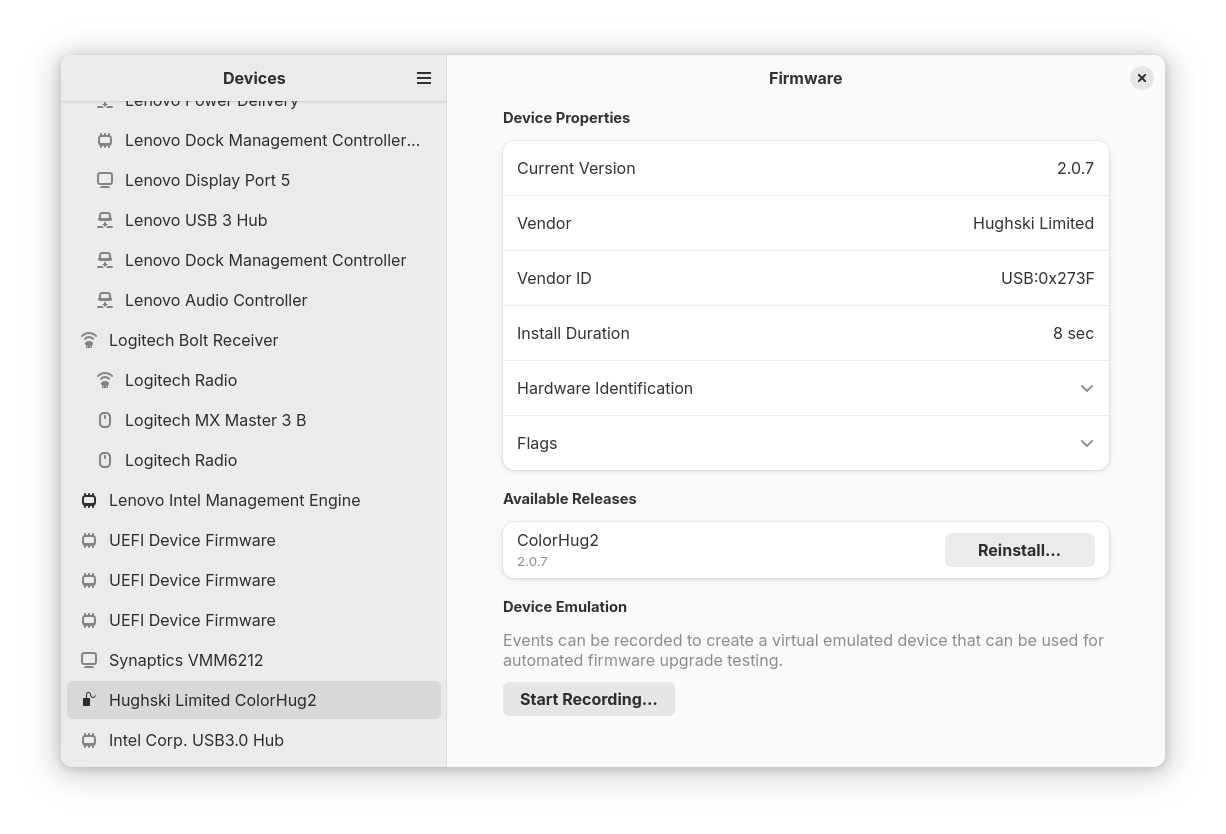
It’s not trivial (or quick) connecting hundreds of devices to a specific CI machine, and so for some time we’ve supported recording USB device enumeration, re-plug, firmware write, re–re-plug and re-enumeration. For fwupd 2.0.0 we added support for all sysfs-based devices too, which allows us emulate a real world NVMe disk doing actual ioctls() and reads() in every submitted CI job. We’re now going to ask vendors to record emulations for existing plugins of the firmware update so we can run those in CI too.
The device emulation docs are complicated and there’s lots of things that the user can do wrong. What I really wanted was a “click, click, save-as, click” user experience that doesn’t need to use the command line. The tl;dr: is that we’ve now added the needed async API in fwupd 2.0.1 (probably going to be released on Monday) and added the click, click UI to gnome-firmware:
There’s a slight niggle when the user starts recording the first “internal” device (e.g. a NVMe disk) that we need to ask the user to restart the daemon or the computer. This is because we can’t just hotplug the internal non-removable device, and need to “start recording” then “enumerate device(s)” rather than the other way around. Recording all the device enumeration isn’t free in CPU or RAM (and is possibly a security problem too), and so we don’t turn it on by default. All the emulation is also all controlled using polkit now, so you need the root password to do anything remotely interesting.
Some of the strings are a bit unhelpful, and some a bit clunky, so if you see anything that doesn’t look awesome or is hard to translate please tell us and we can fix it up. Of course, even better would be a merge request with a better string.
If you want to try it out there’s a COPR with all the right bits for Fedora 41. It’ll might also work on Fedora 40 if you remove gnome-software. I’ll probably switch the Flathub build to 48.alpha when fwupd 2.0.1 is released too. Feedback welcome.
Today I tagged fwupd 2.0.0, which includes lots of new hardware support, a ton of bugfixes and more importantly a redesigned device prober and firmware loader that allows it to do some cool tricks. As this is a bigger-than-usual release I’ve written some more verbose releases notes below.
The first notable thing is that we’ve removed the requirement of GUsb in the daemon, and now use libusb directly. This allowed us to move the device emulation support from libgusb up into libfwupdplugin, which now means we can emulate devices created from sysfs too. This means that we can emulate end-to-end firmware updates on fake hidraw and nvme devices in CI just like we’ve been able to emulate using fake USB devices for some time. This increases the coverage of testing for every pull request, and makes sure that none of our “improvements” actually end up breaking firmware updates on some existing device.
The emulation code is actually pretty cool; every USB control request, ioctl(), read() (and everything inbetween) is recorded from a target device and saved to a JSON file with a unique per-request key for each stage of the update process. This is saved to a zip archive and is usually uploaded to the LVFS mirror and used in the device-tests in fwupd. It’s much easier than having a desk full of hardware and because each emulation is just that, emulated, we don’t need to do the tens of thousands of 5ms sleeps in between device writes — which means most emulations take a few ms to load, decompress, write and verify. This means you can test [nearly] “every device we support” in just a few seconds of CI time.
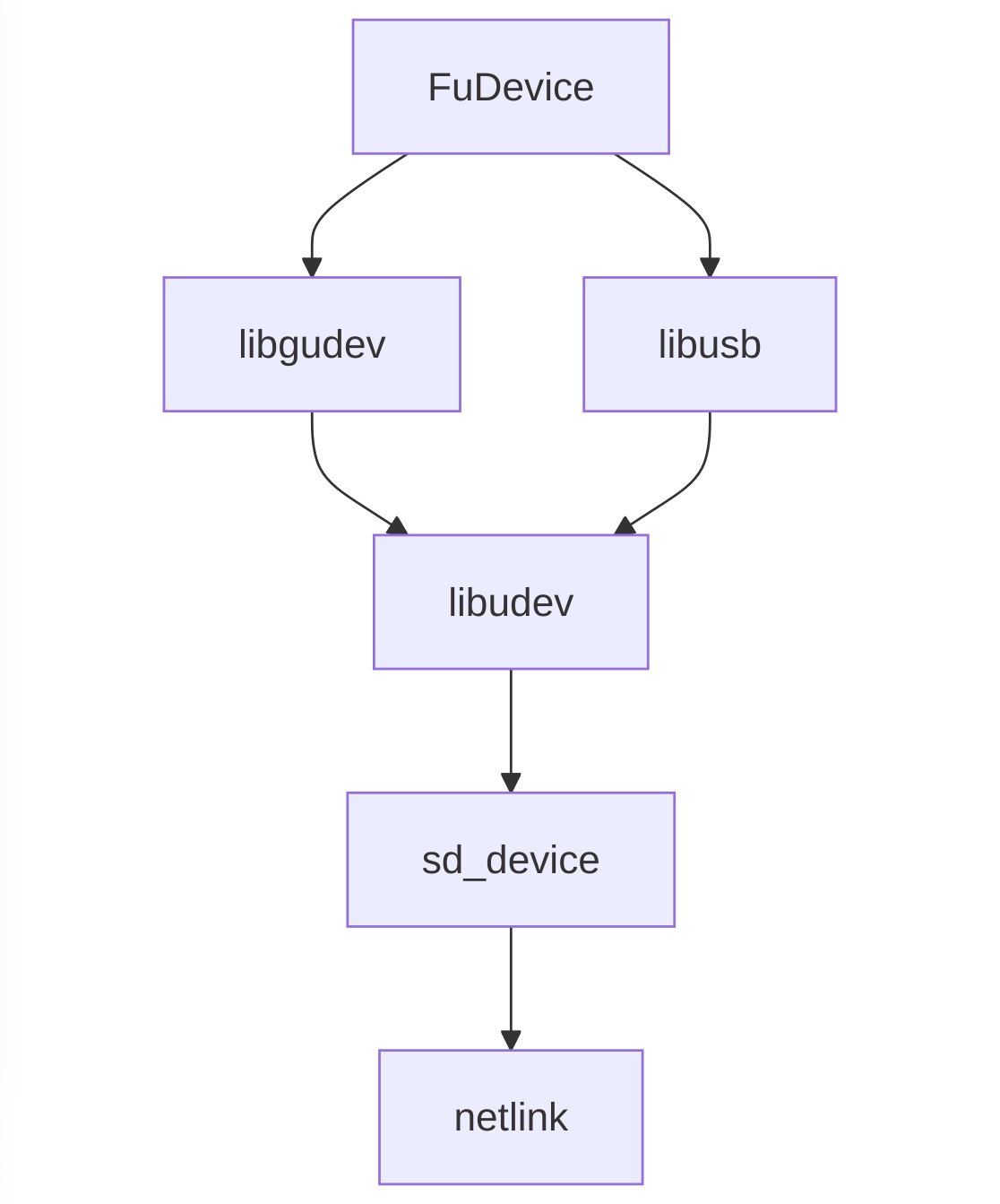
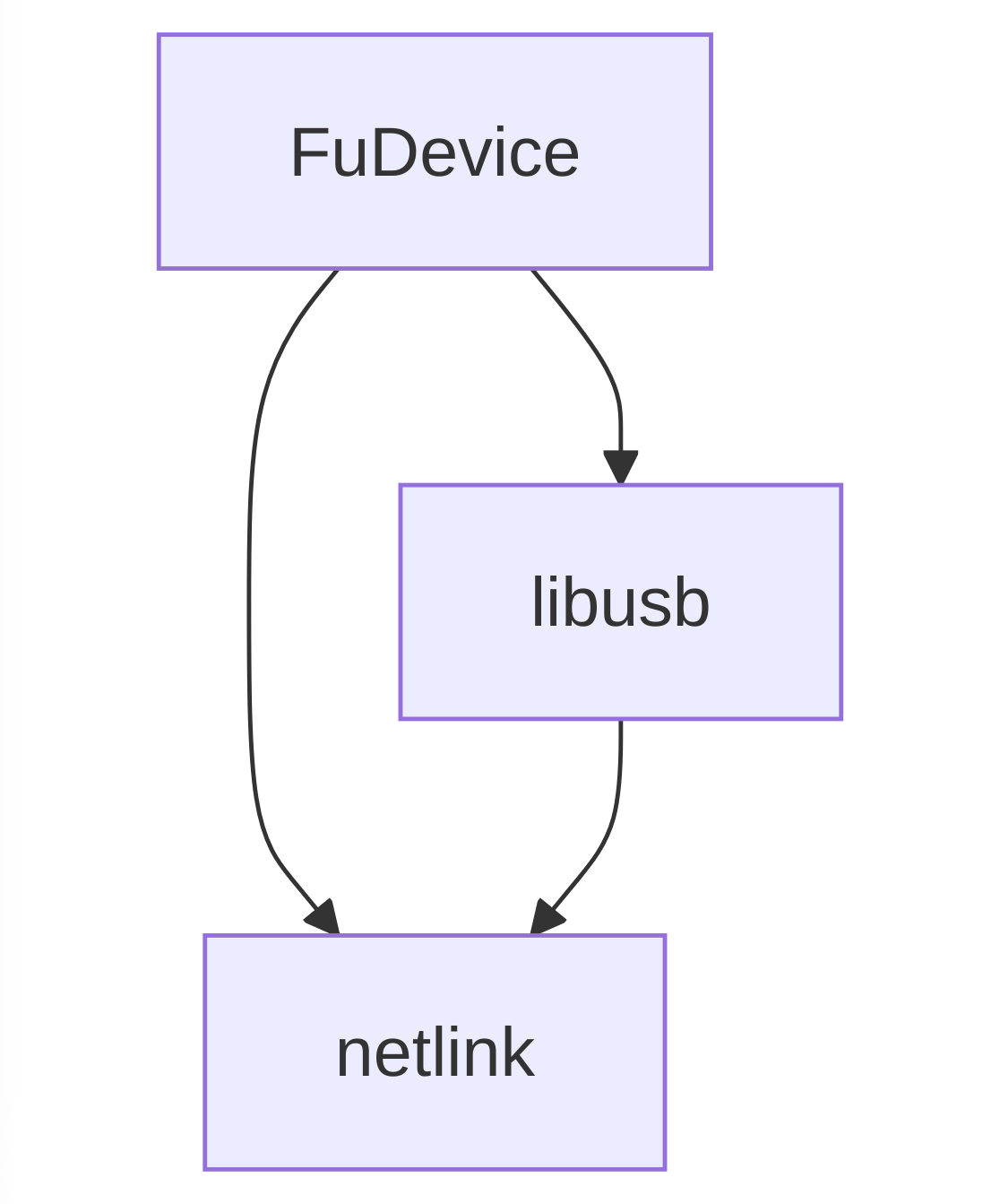
Another nice change is the removal of GUdev as a dependency. GUdev is a nice GObject abstraction over libudev and then sd_device from systemd, but when you’re dealing with thousands of devices (that you’re poking in weird ways), and tens of thousands of device children and parents the “immutable device state” objects drift from reality and the abstraction layers really start to hurt. So instead of using GUdev we now listen to the netlink socket and parse those events into fwupd FuDevice objects, rather than having an abstract device with another abstract device being used as a data source. It has also allowed us to remove at least one layer of caching (that we had to work around in weird ways), and also reduce the memory requirement both at startup and at runtime at the expense of re-implementing the netlink parsing code. It also means we can easily start using ueventd, which makes it possible to run fwupd on Android. More on that another day!
The oldThe new
The biggest change, and the feature that’s been requested the most by enterprise customers is the ability to “stream” firmware from archives into devices. What fwupdmgr used to do (and what 1_9_X still does) is:
Send the cabinet archive to the daemon as a file descriptor
The daemon then loads the input stream into memory (copy 1)
The memory blob is parsed as a cabinet archive, and the blocks-with-header are re-assembled into whole files (copy 2)
The payload is then typically chunked into pieces, with each chunk being allocated as a new blob (copy 3)
Each chunk is sent to the device being updated
This worked fine for a 32MB firmware payload — we allocate ~100MB of memory and then free it, no bother at all.
Where this fails is for one of two cases: huge firmware or underpowered machine — or in the pathological case, huge video conferencing camera firmware with inexpensive Google ChromeBook. In that example we might have a 1.5GB firmware file (it’s probably a custom Android image…) on a 4GB-of-RAM budget ChromeBook. The running machine has a measly 1GB free system memory, and then fwupd immediately OOMs when just trying to parse the archive, let alone deploy the firmware.
So what can we do to reduce the number of in memory copies, or maybe even remove them all completely? There are two tricks that fwupd 2.0.x uses to load firmware now, and those two primitives we now use all over the source tree:
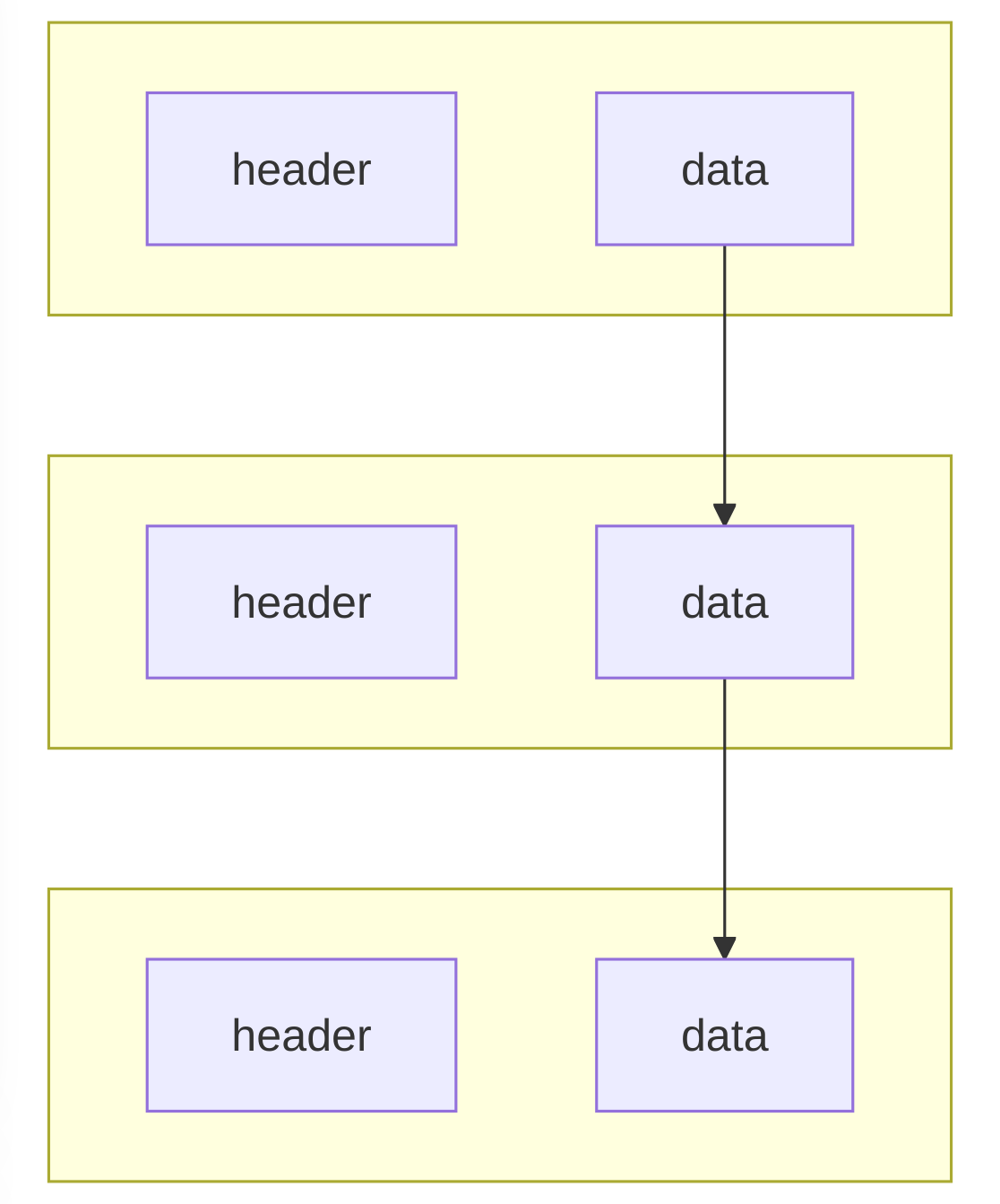
Partial Input Stream:
This models an input stream (which you can think of like a file descriptor) that is made up of a part of a different input stream at a specific offset. So if you have a base input stream of [123456789] you can build two partial input streams of, say, [234] and [789]. If you try and read() 5 bytes from the first partial stream you just get 3 bytes back. If you seek to offset 0x1 on the second partial input stream you get the two bytes of [89].
Composite Input Stream
This models a different kind of input stream, which is made up of one or more partial input streams. In some cases there can be hundreds of partial streams making up one composite stream. So if you take the first two partial input streams defined a few lines before, and then add them to a composite input stream you get [234789] — and reading 8 bytes at offset 0x0 from that would give you what you expect.
This means the new way of processing firmware archives can be:
Send the cabinet archive to the daemon as a file descriptor
The daemon parses it as a cab archive header, and adds the data section of each block to a partial stream that references the base stream at a specific offset
The daemon “collects” all the partial streams into a composite stream for each file in the archive that spans multiple blocks
The payload is split into chunks, with each chunk actually being a partial stream of the composite file stream
Each chunk is read from the stream, and sent to the device being updated
Sooo…. We never actually read the firmware payload from the cabinet file descriptor until we actually send the chunk of payload to the hardware. This means we have to seek() all over the place, possibly many times for each chunk, but in the kernel a seek() is really just doing some pointer maths to a memory buffer and so it’s super quick — even faster in real time than the “simple” process we used in 1_9_X. The only caveat is that you have to use uncompressed cabinet archives (the default for the LVFS) — as using MSZIP decompression currently does need a single copy fallback.
This means we can deploy a 1.5GB firmware payload using an amazingly low 8MB of RSS, and using less CPU that copying 1.5GB of data around a few times. Which means, you can now deploy that huge firmware to that $3,000 meeting room camera from a $200 ChromeBook — but also means we can do the same in RHEL for 5G mobile broadband radios on low-power, low-cost IoT hardware.
Making such huge changes to fwupd meant we could justify branching a new release, and because we bumped the major version it also made sense to remove all the deprecated API in libfwupd. All the changes are documented in the README file, but I’ve already sent patches for gnome-firmware, gnome-software and kde-discover to make the tiny changes needed for the library bump.
My plan for 2.0.x is to ship it in Flathub, and in Fedora 42 — but NOT Fedora 41, RHEL 9 or RHEL 10 just yet. There is a lot of new code that’s only had a little testing, and I fully expect to do a brown paperbag 2.0.1 release in a few days because we’ve managed to break some hardware for some vendor that I don’t own, or we don’t have emulations for. If you do see anything that’s weird, or have hardware that used to be detected, and now isn’t — please let us know.
A few people (and multi-billion dollar companies!) have asked for my response to the xz backdoor. The fwupd metadata that millions of people download every day is a 9.5MB XML file — which thankfully is very compressible. This used to be compressed as gzip by the LVFS, making it a 1.6MB download for end-users, but in 2021 we switched to xz compression instead.
What actually happens behind the scenes is that the libxmlb library loads the optionally compressed metadata into a mmap-able binary blob, and then it gets used by fwupd to look for new updates for specific hardware. In libxmlb 0.3.3 we added support for xz as a compression format. Then fwupd 1.8.7 was released with xz support, preferring the xz format to the “legacy” gz format — as the metadata became a 1.1MB download, saving significant amounts of data from the CDN.
Then this week we learned that xz wasn’t the kind of thing we want to depend on. Out of an abundance of caution (and to be clear — my understanding is there is no fwupd or LVFS security problem of any kind) I’ve switched the LVFS to also generate zstd metadata, make libxmlb no longer hard depend on lzma and switched fwupd to prefer the zstd metadata over the xz metadata if the installed version of libjcat supports it. The zstd metadata is also ~3% smaller than xz (and faster to decompress), but the real benefit is that I now trust it a lot more than xz.
I’ll be doing new libxmlb and fwupd releases with the needed changes next week.
In fwupd 1.9.12 and earlier we had the following auto-quit behavior: Auto-quit on idle after 2 hours, unless:
Any thunderbolt controller, thunderbolt retimer or synaptics-mst devices exist.
These devices are both super slow to query and also use battery power to query as you have to power on various hungry things and then power them down to query for the current firmware version.
In 19.13, due to be released in a few days time, we now: Auto-quit after 5 minutes, unless:
Any thunderbolt controller, thunderbolt retimer or synaptics-mst devices exist.
Any D-Bus client (that used or is using fwupd) is still alive, which includes gnome-software if it’s running in the background of the GNOME session
The daemon took more than 500ms to start – on the logic it’s okay to wait 0.5 seconds on the CLI to get results to a query, but we don’t want to be waiting tens of seconds to check for updates on a deeply nested USB hub devices.
The tl;dr: is that most laptop and desktop machines have Thunderbolt or MST devices, and so they already had fwupd running all the time before, and continue to have it running all the time now. Trading 3.3MB of memory and an extra process for instant queries on a machine with GBs of memory is probably worthwhile. For embedded machines like IoT devices, and for containers (that are using fwupd to update things like the dbx) fwupd was probably starting and then quitting after 2h before, and now fwupd is only going to be alive for 5 minutes before quitting.
If any of the thresholds (500 ms) or timeouts (5 mins) are offensive to you then it’s all configurable, see man fwupd.conf for details. Comments welcome.