October 16, 2012
community, freesoftware
No Comments
This year, we hosted a Humanitarian Free and Open source software track at the Open World Forum for the third time. The track has been of great value to participants as a way of communicating with other practitioners in the space, and exchanging best practices and experiences around funding, community, and working with NGOs.
Once again, we had great participation from representatives of a wide range of projects, in crisis management, healthcare, social enterprise and microfinance. And the quality of the presentations was excellent – when discussing after the conference with Leslie Hawthorn what our favourite presentations were, the short answer was “all of them”. My personal favourites were Mark Prutsalis’s description of the EUROSHA project, Heather Blanchard’s experiences from working closely with aid agencies, and Leslie’s presentation with Julius Awakame of the great work that OpenMRS is doing in electronic medical record management targeting the poorest communities in the world.
The number one request I have had for the track is to turn it into more of a conversation – part presentations to establish a baseline for discussion, but mostly workshops or discussion forums on issues common to projects in HFOSS. Some organisations have funding, but have not succeeded in developing a commercial ecosystem of partners to support the deployment of the software. Other organisations have a partner ecosystem, but have not succeeded in growing an active community or identifying a sustainable funding model. Others have vibrant communities, but do not have either the funding or the organisational infrastructure to have a full time staff, or to bid for projects with aid agencies.
How would you feel about making next year’s Humanitarian track at the Open World Forum a worldwide meeting place of leaders of HFOSS projects, over two days, with a more traditional conference component including presentations, round-tables and workshops, and a Humanitarian BarCamp the day afterwards in Paris? I bet that if we can get critical mass for the idea that we could make this a regular meeting place for these projects. If there is somewhere else more appropriate as a meeting of minds, I’m happy to point people there instead, but I do not have the impression that there is. It has become obvious to me that there is a need for such a meeting place, and Paris in the Autumn seems like the ideal place to have it – central location, easy accessibility internationally from Europe, America, Asia and Africa.
Is there interest in making a real Humanitarian FOSS conference in Paris next year?
September 14, 2012
community, freesoftware, General
13 Comments

Speed bump ahead!
This week I was reminded that the first step in an Open Source project is often the hardest. We’ve been using MediaWiki for a project at work, with the “ConfirmAccount” extension to deal with spammers – a very nice extension indeed! It adds account creation requests to a queue where they can be handled by members of the bureaucrat group.
We had one wishlist item. We wanted to have a notification email sent out to every member of the group when a new request was received. There is an existing feature to send a notification email to a configurable email address, but not to the whole bureaucrat group.
So I said to myself, how hard can that be? And I rolled up my sleeves and set aside an afternoon to make the change, and submit it upstream. After a few false-starts which were nothing to do with MediaWiki, I got down to it.
First task: Upgrade to the latest version of MediaWiki – the version on Fedora 17 is MediaWiki 1.16.5, and the latest stable version is 1.19.2. So I download the latest version, and follow the upgrade instructions to over-write the system MediaWiki install in /usr/share/mediawiki with the upstream version. Unfortunately, the way that $IP (the Install Path) is set changed in version 1.17, in a way that took a little time to work around.
Once that was done, I downloaded the HEAD of the trunk branch from SVN which was linked from the old version of the extension home page, and got the extension working. That needed a few additional modules, and some configuration to get the email notifications working locally, but eventually, I was good to go.
I got to work making my change. It took a while, but once I figured out how to turn on debugging and the general idiom for database queries, it was easy enough. After a couple of hours hacking and testing, I was happy with the result.
The first date
I headed back to the extension home page to figure out how to submit a patch. At the same time, out of habit, I joined the project IRC channel, #mediawiki on Freenode, reasoning that if I got lost I could ask for help there. No indication on the Extension page, but a web search showed me that MediaWiki uses Bugzilla. So I registered for Yet Another Bugzilla Account, and confirmed my email address a few minutes later. Then I created a bug on Bugzilla, and attached my patch to the report.
Simultaneously, on IRC, I was asking for help and was told by a very nice community guy called Dereckson that the preferred way to submit patches was through Gerrit. It turned out that the extension home page should have been pointing to the more recent Git repository all along, and I had been developing against the wrong version of MediaWiki. Dereckson updated the extension page with the right repository information as soon as he discovered it hadn’t been updated before. No big deal, I cloned the Git repository, and tried to apply the patch from svn to git. Unfortunately, it didn’t work – some other changes related to translatable strings had changed code in the same area, and I had to re-do the change, but that was pretty easy.
I did try to submit a patch by following the procedure in the git workflow document, but without an account on Gerrit it didn’t work, of course. Dereckson convinced me to apply to developer access. After some initial resistance, because I really didn’t want to be a MediaWiki developer just to submit a drive-by patch, I requested developer access with the comment “I just wanted to submit one patch to an extension I use, Extension:ConfirmAccount.” Half an hour later, jeremyb approved my request with the comment “That’s what you think now!” 🙂
Then I went to the documentation on getting access and followed the instructions there until I was directed to upload my ssh key to labs and found I did not have access to that resource. Thanks again to Dereckson (once more to the rescue!) on IRC, I found my way to getting set up for git and Gerrit, and got an SSH key set up for Gerrit. Then I went back to the instructions for submitting a patch and a quick “git review” later, I had submitted my first patch ever to Gerrit.

Jumping through hoops (CC by-sa, rwp-roger@flickr)
Pretty quickly, the first couple of reviews came in. First comment: “There’s some whitespace issues here.” Gee, thanks. Second comment, from Dereckson (again!) started with a “Thank you”, said the idea was a good one, and then gave me an example of the project norms for commit comments, and made one comment on the code suggesting I use an option.
As a first time user of Gerrit, I noticed a few issues with it for newbies. It’s not at all clear to me how to distinguish “important” commenters from trivial-to-change things like whitespace issues. It’s also not clear whether a -1 blocks a commit, or how to have a discussion with someone about the approach taken in a patch. Also, it was unclear what the suggested way to update a patch was and propose a new, improved version. My first try, I made some changes, committed them into a new revision on my local branch, and pushed the lot for review (normal git workflow, I daresay). Unfortunately, this was not correct. I ended up squashing the two commits with a “rebase -i”, and since then I have been using “commit –amend”.
After a few more rounds of comments (another whitespace comment, and a suggestion to avoid hard-coding the group name), I am currently on the 5th patchset, which I think does what it says it should, and will pass review muster, when someone gets around to reviewing it. I’ve been told that the review time for a small patch like this can be up to 5 or 10 days, and I don’t know exactly how I know that the process is over and it’s good to commit.
Sunk costs
The end result is that for a small change to a fairly simple MediaWiki extension, I spent about 2 hours coding, and about 4 or 5 hours (a full afternoon) going through the various hoops involved in submitting the change for review upstream.
I’m aware that this is a one-off cost – that now that I have a Bugzilla account, and a git and Gerrit account, it will be easier next time. Now that I have spent the time reading the MediaWiki coding conventions, git workflow, and have spent time understanding how to use Gerrit, I won’t have these issues again. The next patch will only take a few minutes to submit, and I won’t be wondering if I did something wrong if I don’t get a review in the first 10 minutes.
But along with some installation and firewall issues, I ended up spending slightly more than a full day on this. In hindsight, I’m saying to myself “was it really worth a full day of work to avoid maintaining this 20 line patch over time?”
I think it’s important that projects make newcomers jump through some hoops when joining your project – the tools you use and the community processes you follow are an important part of your culture. Sometimes, however, the initial investment that you have to put into the first-time use of a tool – the investment that regular contributors never see any more – is big.
If you’ve never used Bugzilla, git, Gerrit, or SSH, how long would it take you to submit a first patch to a project? How many hurdles does someone have to jump through to submit a patch for your project? Is there a way to ease people into it? I could imagine something like an email based process for newcomers, and only after they’ve made a few contributions, insist that all of the community’s preferred tools and processes be used. Or having true single sign-on, where you have only one account-creation process for all of your interactions with the project, so that you don’t end up creating a wiki account, a Bugzilla account, a Labs account and configuring a Gerrit account.
I want to make clear – I am not picking on MediaWiki here. I rate the project well above average in the speed and friendliness with which I was helped at every turn. But they, like every project, have adopted tools to make it easier for regular contributors, and to help ensure that no patches get dropped on the floor because of poor processes. Here’s the $64,000 question: are the tools and processes which make it easier for regular contributors making it harder for first-time contributors?
July 27, 2012
General, running
5 Comments
For those of you who have been keeping an eye out for me in A Coruna this week I’m sorry to be letting you down. Instead of Galicia, I will be in the Alps this weekend, finally running the race I have spent the last 4 months preparing for: the 6000D.
I have written a post about my final preparations, and a fundraising update (I’m running the race in aid of Muscular Dystrophy Ireland, a group near and dear to my heart) over at “Run for MDI”. It’s not too late to make a donation, if you’d like to. Thanks to the support of friends, family and colleagues, we have raised over €1600 so far!
I am sorry to be missing you all – but if anyone wants to follow along tomorrow and check on my progress, you can track me live during the race.
July 6, 2012
General, home, running
1 Comment
Fancy yourself as a smartypants who knows everything there is to know about everything? Could you name all the cities who have had two or more soccer teams win a European club tournament? Or name the artist and song that kept “Penny Lane” and “Strawberry Fields Forever” off the number one spot in the UK in 1967? Can you name the flower found on the Hong Kong flag? Will you be in Lyon on July 11th?
I’m organising a table quiz next week, Wednesday 11 July, to raise funds for Muscular dystrophy Ireland in advance of running the 6000D in three weeks time (eek!). So far, mostly because of my injury, work and training commitments, fundraising has been slow – but with the race approaching we’re heading full steam ahead, and I’m once again asking for your support and donations.
For those of you who are not in Lyon next week, you are cordially invited to Johnny’s Kitchen, 48 rue Saint Georges, in Vieux Lyon, for a quiz in aid of this cause. There will be a raffle on the night, and the owner is donating €1 for any drinks sold to quiz attendees. Doors open at 8pm, and we’ll kick off the quiz around 8.30. Entry is €3 per person, and all proceed go directly to MDI.
For those of you who can’t be there next week, you can also donate online! We’ve collected almost €700 to date, and I’m hoping to reach €1500 by the time of the race.
Thanks everyone for your support!
April 16, 2012
community, freesoftware, work
30 Comments
I’m joining Red Hat on May 2nd, where I’ll be working with the Open Source and Standards team. We’ll be working hard to help all of the projects that Red Hat contributes to kick ass at growing community. I have known several of the team from years gone past, and interviewing for the position was frankly a pleasure.
I’d like to thank Karsten Wade for thinking of me and making the connections back in February. When my future boss described the position and the team to me around then, and asked me whether I might be interested, I couldn’t help myself from saying “I think you just described my dream job”. I know you’re supposed to show restraint and play hard to get in these situations, but I got carried away.
Red Hat is one of the few companies out there that could tempt me away from independent consulting. They have a range of projects covering the server, desktop, middleware, cloud services and virtualisation. They are the top, or one of the top, corporate contributors to dozens of projects I use every day. I love the Red Hat philosophy of working with communities to make great Free and Open Source software.
Of course, that doesn’t mean that everything is roses. There are projects within Red Hat (or that Red Hat contributes heavily to) which need to improve their community processes, that could do a better job of promoting themselves, or that have hung on to former business models post-acquisition, at the expense of community growth. And it’ll be our job to fix those issues. It’ll be challenging, it’ll be a slow, incremental process. But I have no doubt that it will be very rewarding. I’m looking forward to it!
March 21, 2012
General, running
3 Comments
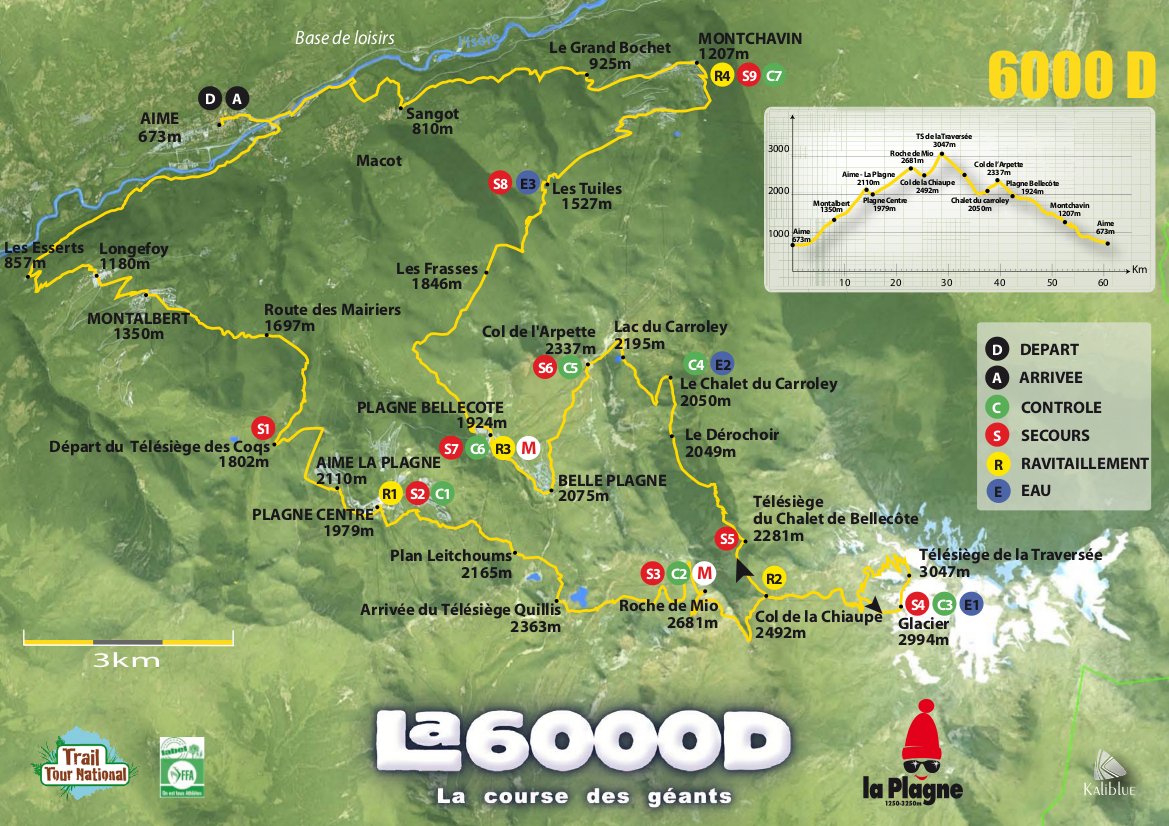
Map of the 6000D
This Summer, on July 28th, I’ll be running a 60km mountain trail race in La Plagne in the Alps, the 6000D. And to provide myself with an added incentive, and to give back something to an organisation that has helped my family in the past, I will be raising money for Muscular Dystrophy Ireland in the process.
I’ve got a blog (in both English and French) specifically for the event to cover my training and fundraising activities, and to give people more information about muscular dystrophy and MDI. I’ve posted a first blog post detailing how I got involved in this as well as some information on muscular dystrophy, MDI and the 600D race up there. I have set an ambitious funding goal of €3000 – and you can follow along and donate on mycharity.ie right now!
In the coming months, I hope that all my friends and family will help me raise money and donate to this great cause. I’ll periodically post updates here, but primarily I’ll be keeping people up to date on the Run for MDI blog and the 6000dForMdi twitter feed. Yu can also subscribe to a newsletter if you don’t want to visit the site regularly – I’ll send out occasional email updates with what’s been going on.
Please help spread the word, and consider donating to help this great cause!
February 16, 2012
community, General
No Comments
Mentoring, lawyer/developer relations, organising events… a few pieces I’ve written/delivered were released recently.
As an OuterCurve mentor I wrote a short article targeted at project managers considering submitting their projects to the Google Summer of Code this year.
My piece on getting people together was included in the recently released Open Advice book, edited and put together by Lydia Pintscher and others. It’s in great company – there are some excellent articles in there. My personal favourites are “Everyone else might be wrong, but probably not”, from Evan Prodromou, “Documentation and my former self” by Anne Gentle, “Software that has the quality with no name” by Federico Mena Quintero and “Who are You, What are You Selling, and Why Should I Care?” by Sally Khudairi, but there are more where those came from.
My write-up of the talk I gave in the Legal Issues DevRoom at FOSDEM, “Gray areas in software licensing” was published on LWN (it’s behing a pay wall for a few days, email me and I’ll share a direct link). Bradley Kuhn informs me that it will be available in audio form in the very near future in the FaiF oggcast.
And my presentation “Crafting Communities to Craft Software” at Redmonk Brew (aka Monkigras), which I reprised in a modified form as “Sustainable mentorship” for FOSDEM in the cross-desktop DevRoom, based largely on an article I wrote a while back was very well received – thank you for the praise! Videos from London and Brussels should be going online soon. In a related note, Kohsuke Kawaguchi’s presentation on creating a developer community was also awesome.
And finally, Stormy Peters published her write-up of the hiring process which led to Karen Sandler becoming the GNOME Foundation Executive Director. I had the pleasure of being part of the process, and I think I contributed something useful to it.
December 9, 2011
freesoftware, General, work
3 Comments
Earlier this week, I wrote:
I hate docs that tell you what to do, but not why. As soon as a package name or path changes, you’re dust. This is maybe the 4th time I’ve been configuring Apache to delegate stuff to Tomcat using mod_jk, and every time is just like the first.
For those who don’t know, mod_jk is a module inplementing the wire protocol AJP/13, which allows a normal HTTP web server to forward on certain requests to a second server. In this case, we want to forward requests for JSP pages and servlets to Tomcat 6. This allows you to do neat things like serve static content with Apache and only forward on the dynamic Java stuff to Tomcat. The user sees a convenient URL (no port :8080 on the hostname) and the administrator gets to serve multiple web scripting languages on the same server, or load balance requests for Java server resources across several hosts.
I have spent enough time on it at this point, I think, that I understand all of the steps in the process, and have stripped it down to the bare minimum that one would need to do in terms of configuration to get things working. And so I’m putting my money where my mouth is, and this is my attempt to write a nice explanation of how mod_jk does its thing, and how to avoid some of the common mistakes I had.
First, a remark: Apache is one of those pieces of software that has gotten harder, rather than easier, to configure as time has gone on. Distributions each package it differently, with different “helpful” mechanisms that make common tasks like enabling a module easier, and to enable convenient packaging of modules like PHP, independent of the core package. But the overall effect is that a lot of magic done by distributions makes it much harder to follow the upstream documentation. Config files are called different names, or stored in different places. Different distributions handle the inclusion of config file snippets differently. And so on.
This is not to say that Apache, Tomcat and mod_jk don’t have some nice docs – they do, but often the docs don’t correspond to the distros, or haven’t been updated in a while, and often they don’t explain why you have to do something, putting emphasis instead on what you need to do. After all my reading, I finally found the Holy Grail I was looking for – the simple document of how to configure mod_jk – but even this has its shortcomings. The article doesn’t mention Tomcat, for example, which left me digging around for information on the configuration I needed to do to Tomcat, which led me to this, which led me to over-write the sample workers.properties file in the simple set-up document.
But if you understand the First Principles, you can figure out what’s going on with any organisation of configuration. That’s what I’m hoping to get across here.
How does mod_jk do its thing?
The first issue I had trouble getting my head around was how, exactly, all this was supposed to work. In particular, I didn’t quite understand how the configuration worked on the Tomcat size of things.
As I understand it, here’s what happens:
- A GET request comes in to httpd for http://localhost/examples/jsp/num/numguess.jsp
- Apache processes the request, and find a matching pattern for the URL among JkMount directives
- Apache then reads the file specified by the JkWorkersFile option to figure out what to do with the request. Let’s say that config file says to forward to localhost:8009 using the protocol ajp13
- Tomcat has a Connector listening on port 8009, with the protocol AJP/13, which handles the request and replies on the wire. Apache httpd sends the reply back to the client
Apache httpd configuration
There are two steps to configuring Apache:
- Enabling the module
- Configuring mod_jk
Apache provides a handy utility called “a2enmod” which will enable a module for you, once it’s installed. What happens behind the scenes for modules depends on the distribution. On Ubuntu, module load instructions are put in a file called /etc/apache2/mods-available/<module>.load optionally alongside a sample configuration file /etc/apache2/mods-available/<module>.conf. To enable the module, you create a symlink to the .load file in /etc/apache2/mods-enabled.
On my Ubuntu laptop, my jk.load contains:
LoadModule jk_module /usr/lib/apache2/modules/mod_jk.so
On OpenSuse, on the other hand, a line similar to this is explicitly added to the file /etc/apache2/sysconfig.d/loadmodule by sysconfig, based on the contents of a field in the configuration file /etc/sysconfig/apache2 – remember how I said that distro packaging makes things harder? If you added the line directly to the loadmodule file, the change would be lost the next time Apache restarts.
In both cases, these files (on Ubuntu, the mods-available/*.load files, and on OpenSuse the sysconfig.d/* files) are loaded by the main Apache config file (httpd.conf) at start-up.
Configuring mod_jk
The minimum configuration that mod_jk needs is a pointer to a Workers definition config file (JkWorkersFile). Other useful configuration options are a path to a log file (JkLogFile – which should be writable by the user ID which owns the httpd process) and a desired log level – I set JkLogLevel to “debug” while getting things set up. On OpenSuse, I also needed to set JkShmFile, since for the default file location (/srv/www/logs/jk-runtime-status) the directory didn’t exist and wasn’t writable by wwwrun, the user that owns the httpd process.
This configuration, and the configuration of paths below, is usually in a separate config file – in both Ubuntu and OpenSuse, it’s jk.conf in /etc/apache2/conf.d (files ending in .conf in this directory are automatically parsed at start-up). To avoid errors in the case where mod_jk is not present or loaded, you can surround all Jk directives with an “<IfModule mod_jk.c>…</IfModule>” check if you’d like.
The JkMount directive configures what will get handled by which worker (more on workers later). It takes two arguments: a path, and the name of the worker to handle requests matching the path. Unix wildcards (globs) are accepted, so
JkMount /examples/*.jsp ajp13_worker
will match all files under /examples ending in .jsp and will pass them off to the ajp13_worker worker.
If you want Apache to serve any static content under your webapps, you’ll also need either a Directory or Alias entry to handle them. Putting together with the previous section, the following (from Ubuntu) was the jk.conf file I used to pass the handling of JSPs and servlets off to Tomcat, and serves static stuff through Apache:
<IfModule mod_jk.c>
JkWorkersFile /etc/libapache2-mod-jk/workers.properties
JkLogFile /var/log/apache2/mod_jk.log
JkLogLevel debug
Alias /examples /usr/share/tomcat6-examples/examples
JkMount /examples/*.jsp ajp13_worker
JkMount /examples/servlets/* ajp13_worker
</IfModule>
I should use Directory to prevent Apache from serving anything it shouldn’t, like Tomcat config files under WEB-INF – I could also just use “JkMount /examples/* ajp13_worker” to have everything handled by Tomcat.
Now that Apache’s config is done, we need to configure mod_jk itself, via the workers.properties file we set in the JkWorkersFile parameter.
workers.properties
Sample workers.properties files contain a lot of stuff you probably don’t need. The basic, unavoidable parameters you will need are the name of a worker (which you’ve already used as the 2nd argument for JkMount above), and a hostname and port to send requests to, and a protocol type (there are several options for worker type besides AJP/1.3 – “lb” for “load balancer” is the most important to read up on). For the above jk.conf, the simplest possible workers.properties file is:
worker.list=ajp13_worker
worker.ajp13_worker.port=8009
worker.ajp13_worker.host=localhost
worker.ajp13_worker.type=ajp13
And that’s it! The last step is to set up Tomcat to handle AJP 1.3 requests on port 8009.
Configuring Tomcat
In principle, Tomcat doesn’t need to know anything about mod_jk.It just needs to know that requests are coming in on a given port, with a given protocol.
Typically, an AJP 1.3 connector is already defined in te default server.xml (in /usr/tomcat6 on both Ubuntu and OpenSuse) when you install Tomcat. The format of the connector configuration is:
<Connector port=”8009″ protocol=”AJP/1.3″ redirectPort=”8443″ />
I am pretty sure that this will work without the redirectPort option, but I haven’t tried it. It basically allows requests received with security constraints specifying encryption to be handled over SSL, rather than unencrypted.
In addition to this, Tomcat does provide a facility to auto-create the appropriate mod_jk configuration on the fly. To do so, you need to specify an ApacheConfig in the Tomcat connector, and point it at the workers.properties file. This facility looks pretty straightforward, but I know I found it confusing in the past when I lost edits to the jk.conf file – I prefer manual configuration myself.
Gotchas
I have had quite a few gotchas while figuring all this out – I may as well share for the benefit of future people having the same problems.
- All the documentation for mod_jk installedd with the packages refers to Tomcat5 paths – for example, on OpenSuse, in the readme, I was asked to copy workers.config into /etc/tomcat5/base – a directory which doesn’t exist (even when you change the 5 to a 6)
- If your apache web server uses virtual hosts (and, on Ubuntu, it does by default) then JkMounts are not picked up from the global configuration file! You need to either add “JkMountCopy true” to the VirtualHost section, or have JkMounts per VirtualHost. If you used Alias as I did above, and you try to run a servlet, the error message is just a 404. If you try to load a JSP, you will see the source.
- If you make a mistake in your workers.property file (I had a typo “workers.list=ajp13_worker” for several hours) and your worker name is not found in a “worker.list” entry, you will see no error message at all with warnings set to error or info. With the warning level set to debug, you will see the error message “jk_translate::mod_jk.c (3542): no match for /examples/ found” The chances are you have a typo in either your jk.conf file (check that the name of the worker corresponds to the name you use in workers.properties), or you have a typo somewhere in your workers.properties file (is it really work.list? Does the worker name match? Is it the same as the worker name in the .host, .port and .type configuration?
- Make sure you get Tomcat working correctly first and working perfectly on port 8080 – or you won’t know whether errors you’re seeing are Tomcat errors, Apache errors or mod_jk errors.
I’m sure I’ve made mistakes and forgotten important stuff – I’m happy to get feedback in the comments.
December 7, 2011
community, work
No Comments
For the past few months, I have been offering a new service – a training course tailored to helping a team be effective working with community projects – whether that is engaging an existing community, or growing a community around new code. Details of the topics I cover are up on my site. Developing software in community is as much a social activity as it is a technical activity – and engaging an existing community, like moving into a new neighbourhood or starting at a new school, can be very daunting indeed. This course covers not just the technical issues of community development, but also the social, management and strategic issues involved. Some of the questions that I try to help answer are:
- What are the tools and communication norms?
- How can I get answers to my questions?
- Is there a trick to writing patches that get reviewed quickly?
- How do I figure out who’s in charge?
- How much will it cost me to open source some code/to work with an existing project?
- How does managing volunteers work?
- Is there anything I can do to help my developers be more vocal upstream?
- What legal issues should my developers be aware of?
All of these things, in my experience, are challenges that organisations have to overcome when they start engaging with community projects like Apache, GNOME or the Linux kernel.
If you’re having trouble with these issues, or some subset of them, and are interested in a training seminar, please contact me, and we’ll talk.
November 21, 2011
freesoftware
6 Comments
I will be giving a short training session on Thursday December 1st 2011 at 19h30 in the Maison pour Tous, la Salles de Rancy, on the subject “Présentation et initiation à l’utilisation de Git pour la gestion d’un projet communautaire (ou comment donner l’impression qu’on est un super codeur ?)”(roughly translated: “A presentation of Git usage in community software projects (or: how to make people think you’re a super coder)”. The basic idea is to show people how to use git to (a) save their work regularly and (b) reorganise patches using
git rebase --interactive
to make themselves look smarter than they are.
For those interested but unable to attend, I will be borrowing heavily from Federico Mena Quintero’s 2008 blog post Why I want to have the children of git rebase –interactive
This is a short session, but I plan to plough through a lot of content, like this:
- 10 minutes: What is version control, how does Git (and other DVCS) differ from svn
- 20 minutes: Git basics (initialising a repository, allowing others to pull from it, how clone, status, add, commit, update, pull, push, branch works)
- 20 minutes: Branching, merging – good policy for maintaining a common trunk, submitting patches for review with git format-patch and send-email
- 20 minutes: git rebase, with –interactive using pick, edit and squash; A word of warning on squashing or editing commits when others are cloning your code
- 20 minutes: Questions
Are there things I absolutely should talk about which aren’t listed? I’m assuming that most of the attendees will be somewhat familiar with some version control and potentially even git already, and don’t need a full one hour on the virtues of version control, so I’m assuming I can fly through the basics pretty quickly.
« Previous Entries Next Entries »