Today I tagged fwupd 2.0.0, which includes lots of new hardware support, a ton of bugfixes and more importantly a redesigned device prober and firmware loader that allows it to do some cool tricks. As this is a bigger-than-usual release I’ve written some more verbose releases notes below.
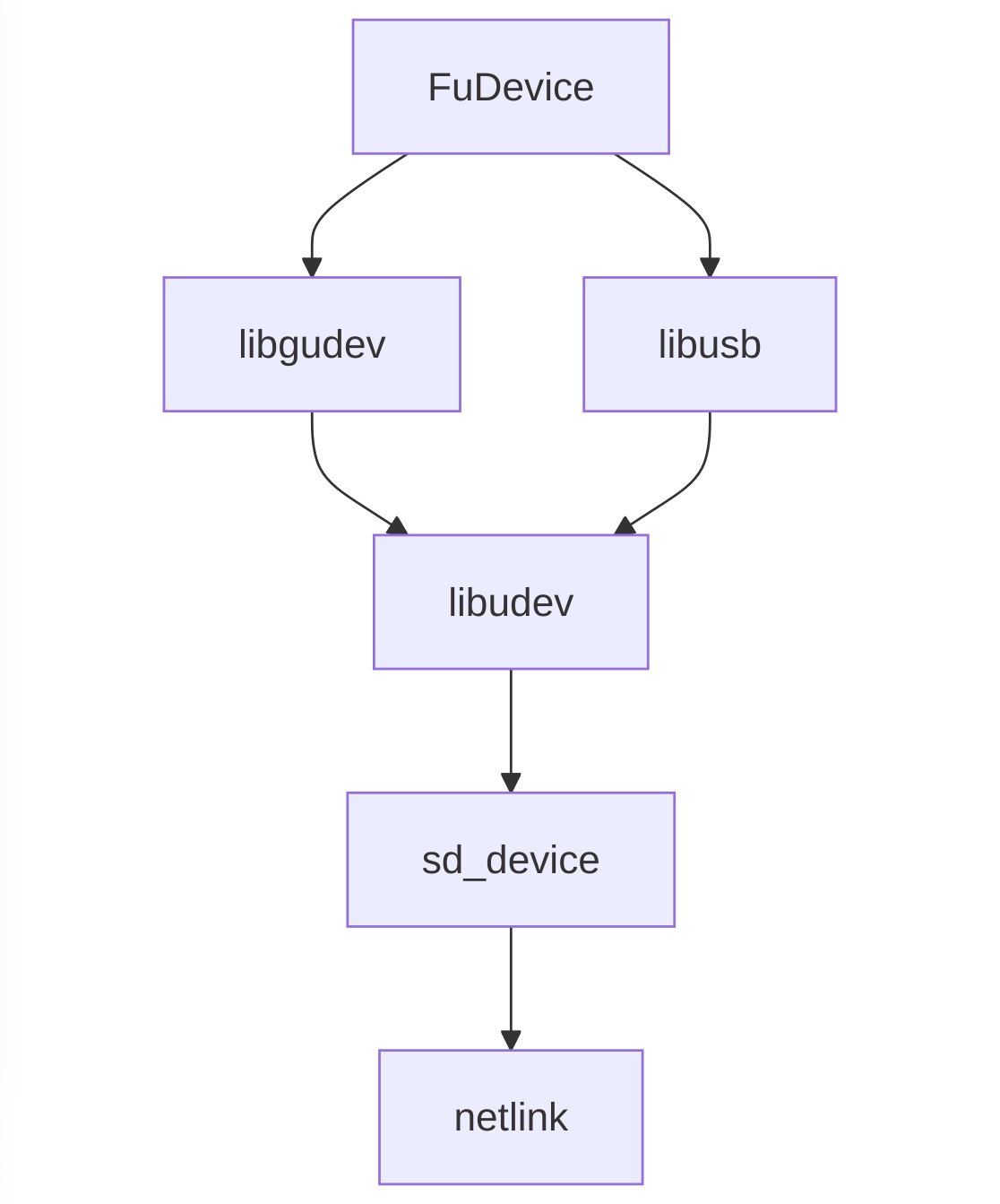
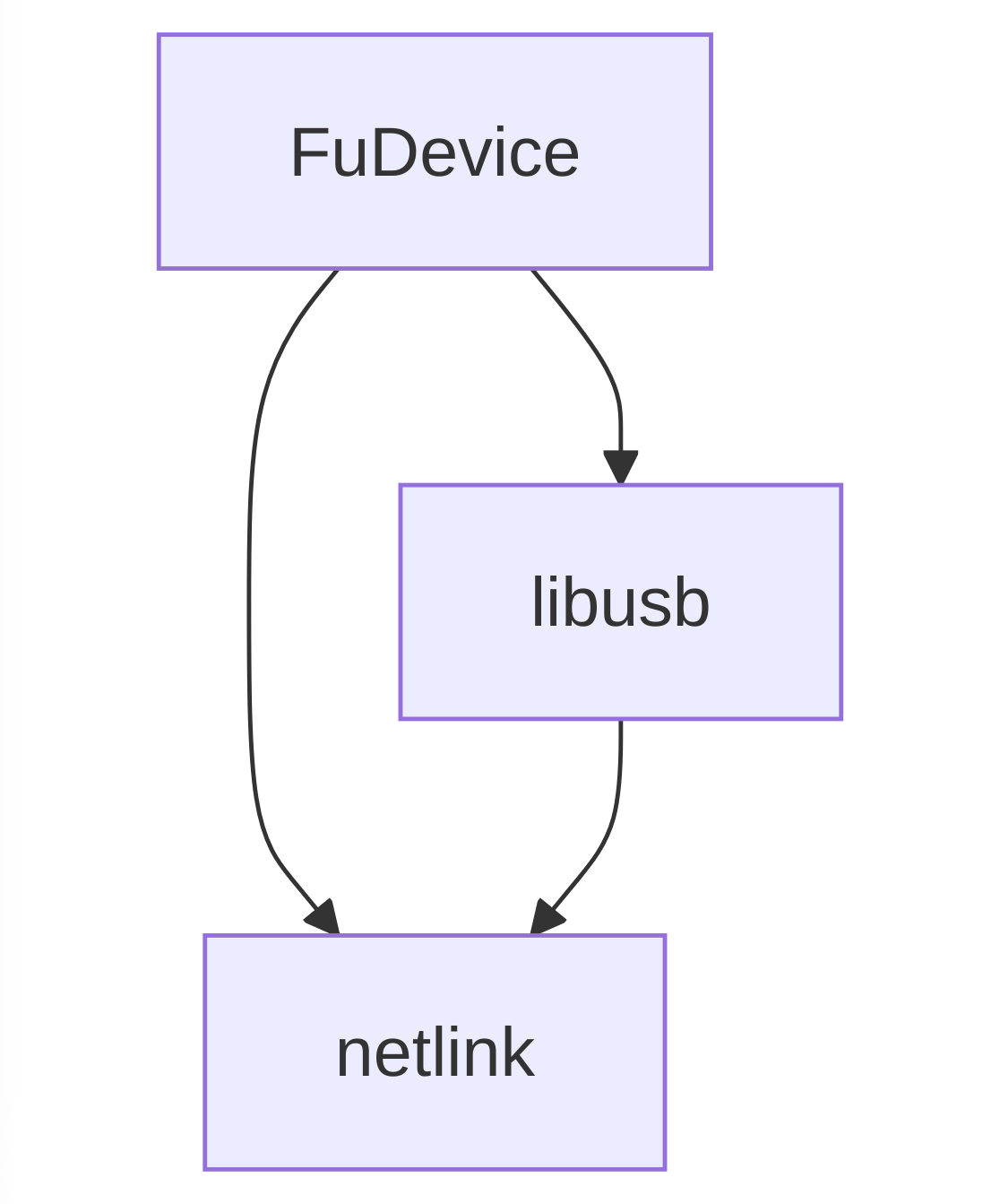
The first notable thing is that we’ve removed the requirement of GUsb in the daemon, and now use libusb directly. This allowed us to move the device emulation support from libgusb up into libfwupdplugin, which now means we can emulate devices created from sysfs too. This means that we can emulate end-to-end firmware updates on fake hidraw and nvme devices in CI just like we’ve been able to emulate using fake USB devices for some time. This increases the coverage of testing for every pull request, and makes sure that none of our “improvements” actually end up breaking firmware updates on some existing device.
The emulation code is actually pretty cool; every USB control request, ioctl(), read() (and everything inbetween) is recorded from a target device and saved to a JSON file with a unique per-request key for each stage of the update process. This is saved to a zip archive and is usually uploaded to the LVFS mirror and used in the device-tests in fwupd. It’s much easier than having a desk full of hardware and because each emulation is just that, emulated, we don’t need to do the tens of thousands of 5ms sleeps in between device writes — which means most emulations take a few ms to load, decompress, write and verify. This means you can test [nearly] “every device we support” in just a few seconds of CI time.
Another nice change is the removal of GUdev as a dependency. GUdev is a nice GObject abstraction over libudev and then sd_device from systemd, but when you’re dealing with thousands of devices (that you’re poking in weird ways), and tens of thousands of device children and parents the “immutable device state” objects drift from reality and the abstraction layers really start to hurt. So instead of using GUdev we now listen to the netlink socket and parse those events into fwupd FuDevice objects, rather than having an abstract device with another abstract device being used as a data source. It has also allowed us to remove at least one layer of caching (that we had to work around in weird ways), and also reduce the memory requirement both at startup and at runtime at the expense of re-implementing the netlink parsing code. It also means we can easily start using ueventd, which makes it possible to run fwupd on Android. More on that another day!
The biggest change, and the feature that’s been requested the most by enterprise customers is the ability to “stream” firmware from archives into devices. What fwupdmgr used to do (and what 1_9_X still does) is:
- Send the cabinet archive to the daemon as a file descriptor
- The daemon then loads the input stream into memory (copy 1)
- The memory blob is parsed as a cabinet archive, and the blocks-with-header are re-assembled into whole files (copy 2)
- The payload is then typically chunked into pieces, with each chunk being allocated as a new blob (copy 3)
- Each chunk is sent to the device being updated
This worked fine for a 32MB firmware payload — we allocate ~100MB of memory and then free it, no bother at all.
Where this fails is for one of two cases: huge firmware or underpowered machine — or in the pathological case, huge video conferencing camera firmware with inexpensive Google ChromeBook. In that example we might have a 1.5GB firmware file (it’s probably a custom Android image…) on a 4GB-of-RAM budget ChromeBook. The running machine has a measly 1GB free system memory, and then fwupd immediately OOMs when just trying to parse the archive, let alone deploy the firmware.
So what can we do to reduce the number of in memory copies, or maybe even remove them all completely? There are two tricks that fwupd 2.0.x uses to load firmware now, and those two primitives we now use all over the source tree:
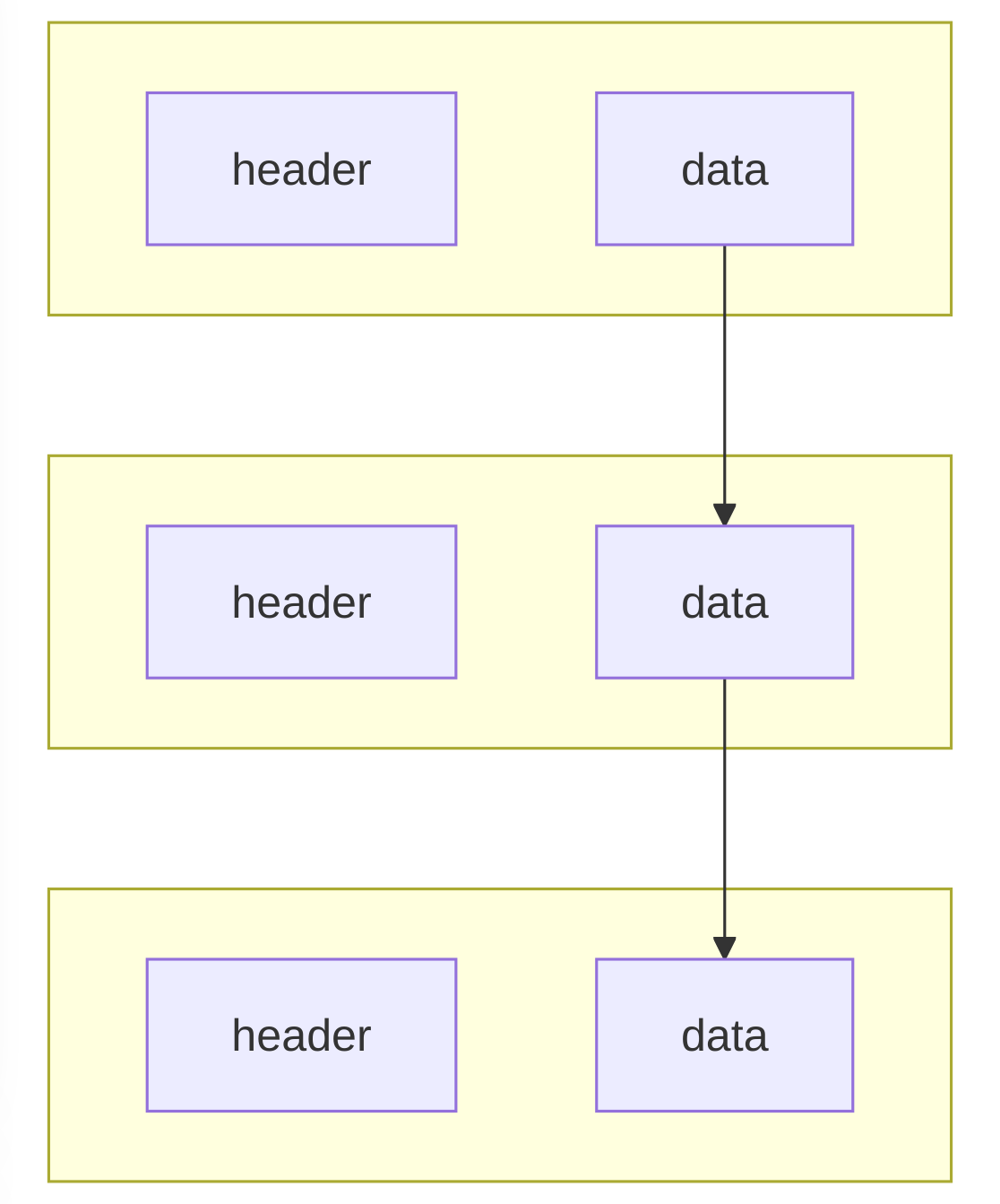
Partial Input Stream:
This models an input stream (which you can think of like a file descriptor) that is made up of a part of a different input stream at a specific offset. So if you have a base input stream of [123456789] you can build two partial input streams of, say, [234] and [789]. If you try and read() 5 bytes from the first partial stream you just get 3 bytes back. If you seek to offset 0x1 on the second partial input stream you get the two bytes of [89].
Composite Input Stream
This models a different kind of input stream, which is made up of one or more partial input streams. In some cases there can be hundreds of partial streams making up one composite stream. So if you take the first two partial input streams defined a few lines before, and then add them to a composite input stream you get [234789] — and reading 8 bytes at offset 0x0 from that would give you what you expect.
This means the new way of processing firmware archives can be:
- Send the cabinet archive to the daemon as a file descriptor
- The daemon parses it as a cab archive header, and adds the data section of each block to a partial stream that references the base stream at a specific offset
- The daemon “collects” all the partial streams into a composite stream for each file in the archive that spans multiple blocks
- The payload is split into chunks, with each chunk actually being a partial stream of the composite file stream
- Each chunk is read from the stream, and sent to the device being updated
Sooo…. We never actually read the firmware payload from the cabinet file descriptor until we actually send the chunk of payload to the hardware. This means we have to seek() all over the place, possibly many times for each chunk, but in the kernel a seek() is really just doing some pointer maths to a memory buffer and so it’s super quick — even faster in real time than the “simple” process we used in 1_9_X. The only caveat is that you have to use uncompressed cabinet archives (the default for the LVFS) — as using MSZIP decompression currently does need a single copy fallback.
This means we can deploy a 1.5GB firmware payload using an amazingly low 8MB of RSS, and using less CPU that copying 1.5GB of data around a few times. Which means, you can now deploy that huge firmware to that $3,000 meeting room camera from a $200 ChromeBook — but also means we can do the same in RHEL for 5G mobile broadband radios on low-power, low-cost IoT hardware.
Making such huge changes to fwupd meant we could justify branching a new release, and because we bumped the major version it also made sense to remove all the deprecated API in libfwupd. All the changes are documented in the README file, but I’ve already sent patches for gnome-firmware, gnome-software and kde-discover to make the tiny changes needed for the library bump.
My plan for 2.0.x is to ship it in Flathub, and in Fedora 42 — but NOT Fedora 41, RHEL 9 or RHEL 10 just yet. There is a lot of new code that’s only had a little testing, and I fully expect to do a brown paperbag 2.0.1 release in a few days because we’ve managed to break some hardware for some vendor that I don’t own, or we don’t have emulations for. If you do see anything that’s weird, or have hardware that used to be detected, and now isn’t — please let us know.
Anyway, enough talking for now, enjoy!
Awesome, thanks for your hard work on this!!
Fantastic work! Thanks so much for all your work on the this.
Thank you for your work, fwupd is such an important and valuable tool!
Well done, Richard! Thank you for your great work.
Congratulations on the release and thanks for fwupd! It’s truly one of the crown jewels of Linux – firmware updates work just as well as on Windows and with more transparency and trustworthiness. Well done!