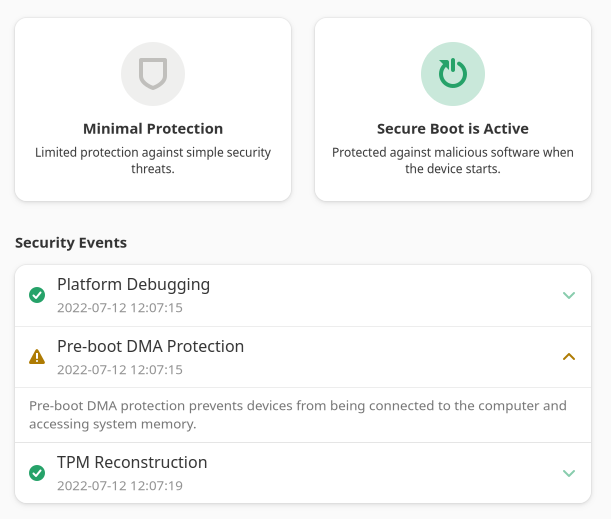
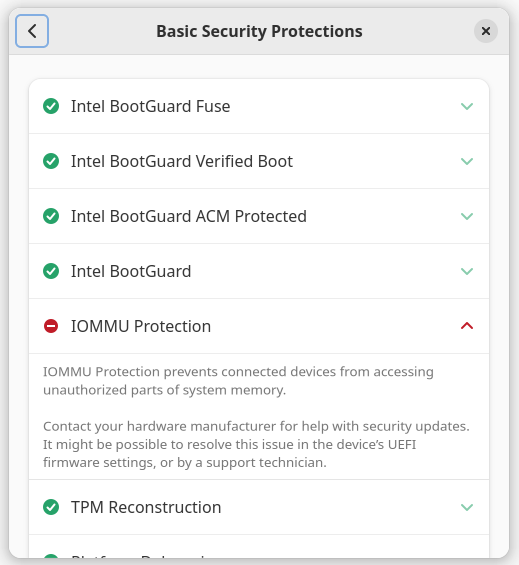
A couple of months ago, Binarly announced LogoFAIL which is a pretty serious firmware security problem. There is lots of complexity Alex explains much better than I might, but essentially a huge amount of system firmware running right now is vulnerable: The horribly-insecure parsing in the firmware allows the user to use a corrupted OEM logo (the one normally shown as the system boots) to run whatever code they want, providing a really useful primitive to do basically anything the attacker wants when running in a super-privileged boot state.
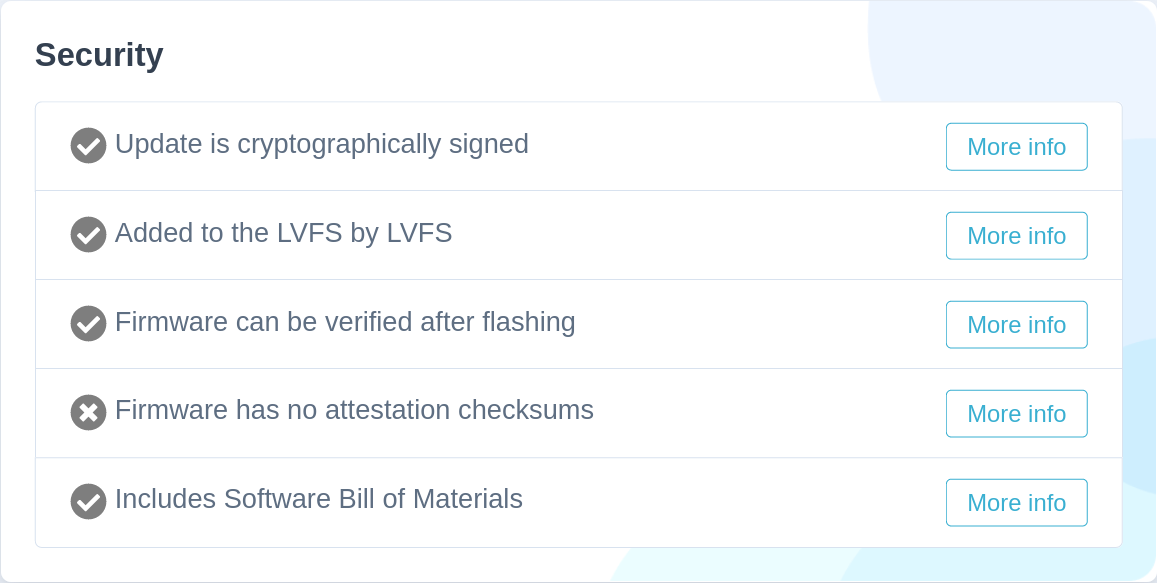
Vendors have to release new firmware versions to address this, and OEMs using the LVFS have pumped out millions of updates over the last few weeks.
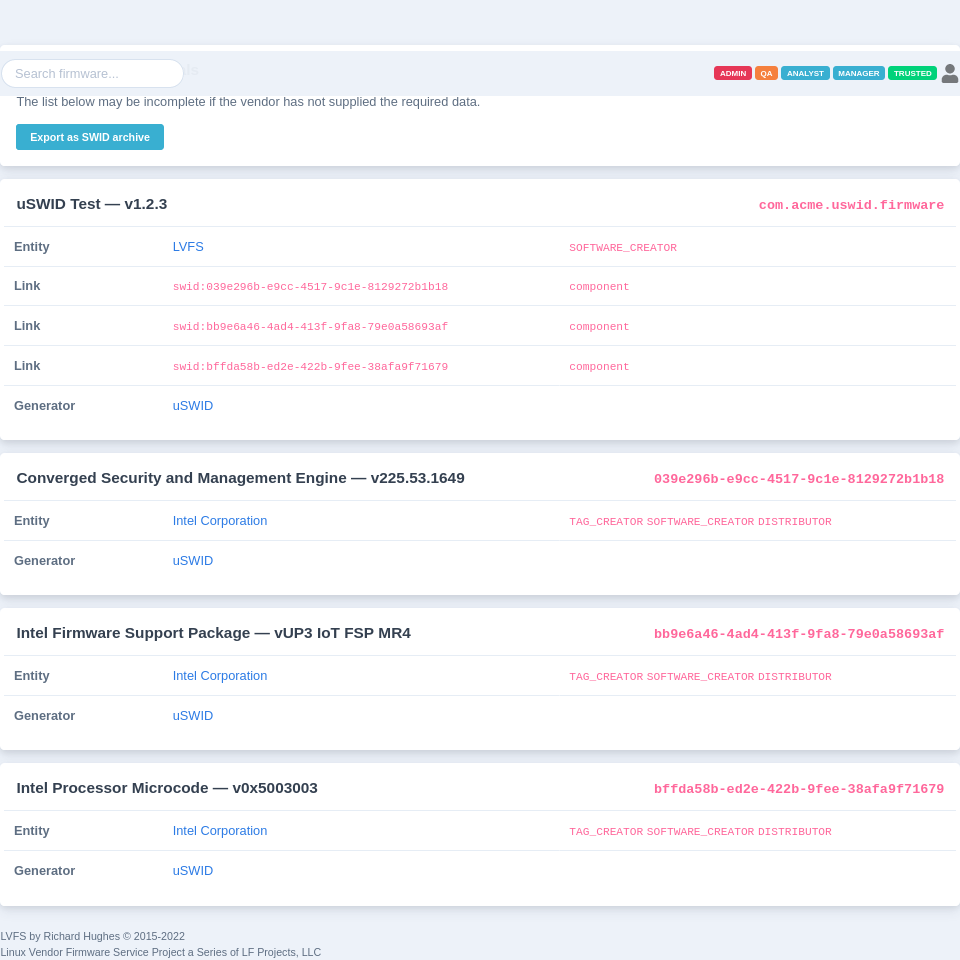
So, what can we do to check that your system firmware has been patched [correctly] by the OEM? The only real way we can detect this is by dumping the BIOS in userspace, decompressing the various sections and looking at the EFI binary responsible for loading the image. In an ideal world we’d be able to look at the embedded SBoM entry for the specific DXE, but that’s not a universe we live in yet — although it is something I’m pushing the IBVs really hard to do. What we can do right now is token matching (or control flow analysis) to detect the broken and fixed image loader versions.
The four decompressing the various sections words hide how complicated taking an Intel Flash Descriptor image and breaking it into EFI binaries actually is. There are many levels of Matryoshka doll stacking involving hideous custom LZ77 and Huffman decompressors, and of course vendor-specific section types. It’s been several programmer-months spread over the last few years figuring it all out. Programs like UEFITool do a very good job, but we need to do something super-lightweight (and paranoid) at every system boot as part of the HSI tests. We only really want to stream a few kBs of SPI contents, not MBs as it’s actually quite slow and we only need a few hundred bytes to analyze.
In Fedora 40 all the kernel parts are in place to actually get the image from userspace in a sane way. It’s a 100% read-only interface, so don’t panic about bricking your system. This is currently Intel-only — AMD wasn’t super-keen on allowing userspace read access to the SPI, even as root — even though it’s the same data you can get with a $2 SPI programmer and 30 seconds with a Pomona clip.
Intel laptop and servers should both have an Intel PCI SPI controller — but some OEMs manually hide it for dubious reasons — and if that’s the case there’s nothing we can do I’m afraid.
You can help the fwupd project by contributing test firmware we can use to verify we parse it correctly, and to prevent regressions in the future. Please follow these steps only if:
- You have an Intel CPU laptop, desktop or server machine
- You’re running Fedora 39, (no idea on other distros, but you’ll need at least
CONFIG_MTD_SPI_NOR,CONFIG_SPI_INTEL_PCIandCONFIG_SPI_MEMto be enabled in the kernel) - You’re comfortable installing and removing a kernel on the command line
- There’s not already a test image for the same model provided by someone else
- You are okay with uploading your SPI contents to the internet
- You’re running the OEM-provided firmware, and not something like coreboot
- You’re aware that the firmware image we generate may have an encrypted version of your BIOS supervisor password (if set) and also all of the EFI attribute keys you’ve manually set, or that have been set by the various crash reporting programs.
- The machine is not a secure production system or a machine you don’t actually own.
Okay, lets get started:
sudo dnf update kernel --releasever 40
Then reboot into the new kernel, manually selecting the fc40 entry on the grub menu if required. We can check that the Intel SPI controller is visible.
$ cat /sys/class/mtd/mtd0/name BIOS
Assuming it’s indeed BIOS and not some other random system MTD device, lets continue.
$ sudo cat /dev/mtd0 > lenovo-p1-gen4.bin
The filename should be lowercase, have no spaces, and identify the machine you’re using — using the SKU if that’s easier.
Then we want to compress it (as it will have a lot of 0xFF padding bytes) and encrypt it (otherwise github will get most upset that you’re attaching something containing “binary code”):
zip lenovo-p1-gen4.zip lenovo-p1-gen4.bin -e Enter password: fwupd Verify password: fwupd
It’s easier if you use the password of “fwupd” (lowercase, no quotes) but if you’d rather send the image with a custom password just get the password to me somehow. Email, mastodon DM, carrier pigeon, whatever.
If you’re happy sharing the image, can you please create an issue and then attach the zip file and wait for me to download the file and close the issue. I also promise that I’m only using the provided images for testing fwupd IFD parsing, rather than anything more scary.
NOTE: If you’re getting a permission error (even running with sudo) you’re probably hitting a kernel MTD issue we’re trying to debug and fix. I wrote a python script that can be run as root to try to get each partition in turn.
If this script works, can you please also paste the output of that script into the submitted github issue.
Thanks!