WebKitGTK 2.50.3 contains a workaround for CVE-2025-13947, an issue that allows websites to exfiltrate files from your filesystem. If you’re using Epiphany or any other web browser based on WebKitGTK, then you should immediately update to 2.50.3.
Websites may attach file URLs to drag sources. When the drag source is dropped onto a drop target, the website can read the file data for its chosen files, without any restrictions. Oops. Suffice to say, this is not how drag and drop is supposed to work. Websites should not be able to choose for themselves which files to read from your filesystem; only the user is supposed to be able to make that choice, by dragging the file from an external application. That is, drag sources created by websites should not receive file access.
I failed to find the correct way to fix this bug in the two afternoons I allowed myself to work on this issue, so instead my overly-broad solution was to disable file access for all drags. With this workaround, the website will only receive the list of file URLs rather than the file contents.
WebKitGTK has a bunch of different confusing API versions. Here are the three API versions that are currently supported by upstream:
webkitgtk-6.0: This is WebKitGTK for GTK 4 (and libsoup 3), introduced in WebKitGTK 2.40. This is what’s built by default if you build WebKit with -DPORT=GTK.
webkit2gtk-4.1: This is WebKitGTK for GTK 3 and libsoup 3, introduced in WebKitGTK 2.32. Get this by building with -DPORT=GTK -DUSE_GTK3=ON.
webkit2gtk-4.0: This is WebKitGTK for GTK 3 and libsoup 2, introduced in WebKitGTK 2.6. Get this by building with -DPORT=GTK -DUSE_GTK3=ON -DUSE_SOUP2=ON.
webkitgtk-6.0 contains a bunch of API changes, and all deprecated APIs were removed. If you’re upgrading to webkitgtk-6.0, then you’re also upgrading your application from GTK 3 to GTK 4, and have to adapt to much bigger GTK API changes anyway, so this seemed like a good opportunity to break compatibility and fix old mistakes for the first time in a very long time.
webkit2gtk-4.1 is exactly the same as webkit2gtk-4.0, except for the libsoup API version that it links against.
webkit2gtk-4.0 is — remarkably — mostly API stable since it was released in September 2014. Some particular C APIs have been deprecated and don’t work properly anymore, but no stable C APIs have been removed during this time, and library ABI is maintained. (Caveat: WebKitGTK used to have unstable DOM APIs, some of which were removed before the DOM API was eventually stabilized. Nowadays, the DOM APIs are all stable but deprecated in webkit2gtk-4.1 and webkit2gtk-4.0, and removed in webkitgtk-6.0.)
If you are interested in history, here are the older API versions that do not matter anymore:
webkit2gtk-5.0: This was an unstable API version used during development of the GTK 4 API, intended for WebKit developers rather than application developers. It was obsoleted by webkitgtk-6.0.
webkit2gtk-3.0: original API version of WebKitGTK for GTK 3 and libsoup 2, obsoleted by webkit2gtk-4.0. This was the original “WebKit 2” API version, which was only used by a few applications before it was removed one decade ago (history).
webkitgtk-3.0: note the missing “2”, this is “WebKit 1” (predating the modern multiprocess architecture) for GTK 3. This API version was widely-used on Linux, and its removal one decade ago precipitated a security crisis which I called The Great API Break. (This crisis was worth it. Modern WebKit’s multiprocess architecture is far more secure than the old single-process architecture.)
webkitgtk-1.0: the original WebKitGTK API version, this is “WebKit 1” for GTK 2. This API version was also widely-used on Linux before it was removed in The Great API Break.
Fedora and RHEL users, are you confused by all the different confusing downstream package names? Here is your map:
webkitgtk6.0, webkit2gtk4.1, and webkit2gtk4.0: This is the current binary package naming in Fedora, corresponding precisely to the WebKitGTK API version to reduce confusion.
webkit2gtk3: old name for webkit2gtk4.0, still used in RHEL 9 and RHEL 8
webkitgtk4: even older name for webkit2gtk4.0, still used in RHEL 7
webkitgtk3: this is the webkitgtk-3.0 API version, still used in RHEL 7
webkitgtk: this is webkitgtk-1.0, used in RHEL 6
Notably, webkit2gtk4.0, webkit2gtk3, and webkitgtk4 are all the same thing.
We all think we’re smart enough to not be tricked by a phishing attempt, right? Unfortunately, I know for certain that I’m not, because I entered my GitHub password into a lookalike phishing website a year or two ago. Oops! Fortunately, I noticed right away, so I simply changed my unique, never-reused password and moved on. But if the attacker were smarter, I might have never noticed. (This particular attack website was relatively unsophisticated and proxied only an unauthenticated view of GitHub, a big clue that something was wrong. Update: I want to be clear that it would have been very easy for the attacker to simply redirect me to the real github.com after stealing my credentials, in which case I would not have noticed the attack and would not have known to change my password.)
You might think multifactor authentication is the best defense against phishing. Nope. Although multifactor authentication is a major security improvement over passwords alone, and the particular attack that tricked me did not attempt to subvert multifactor authentication, it’s actually unfortunately pretty easy for phishers to defeat most multifactor authentication if they wish to do so:
Multifactor authentication based on phone calls is also insecure (because SIM swapping isn’t going away; determined attackers will steal your phone number if it’s an obstacle to them)
Multifactor authentication based on authenticator apps (using TOTP or HOTP) is much better in general, but still fails against phishing. When you paste your one-time access code into a phishing website, the phishing website can simply “proxy” the access code you kindly provided to them by submitting it to the real website. This only allows authenticating once, but once is usually enough.
Fortunately, there is a solution: passkeys. Based on FIDO2 and WebAuthn, passkeys resist phishing because the authentication process depends on the domain of the service that you’re actually connecting to. If you think you’re visiting https://example.com, but you’re actually visiting a copycat website with a Cyrillic а instead of Latin a, then no worries: the authentication will fail, and the frustrated attacker will have achieved nothing.
The most popular form of passkey is local biometric authentication running on your phone, but any hardware security key (e.g. YubiKey) is also a good bet.
target.com Is More Secure than Your Bank!
I am not joking when I say that target.com is more secure than your bank (which is probably still relying on SMS or phone calls, and maybe even allows you to authenticate using easily-guessable security questions):
target.com is introducing passkeys!
Good job for supporting passkeys, Target.
It’s probably perfectly fine for Target to support passkeys alongside passwords indefinitely. Higher-security websites that want to resist phishing (e.g. your employer’s SSO service) should consider eventually allowing only passkeys.
No Passkeys in WebKitGTK
Unfortunately for GNOME users, WebKitGTK does not yet support WebAuthn, so passkeys will not work in GNOME Web (Epiphany). That’s my browser of choice, so I’ve never touched a passkey before and don’t actually know how well they work in practice. Maybe do as I say and not as I do? If you require high security, you will unfortunately need to use Firefox or Chrome instead, at least for the time being.
Why Was Michael Visiting a Fake github.com?
The fake github.com appeared higher than the real github.com in the DuckDuckGo search results for whatever I was looking for at the time. :(
With the release of WebKitGTK 2.40.0, WebKitGTK now finally provides a stable API and ABI for GTK 4 applications. The following API versions are provided:
webkit2gtk-4.0: this API version uses GTK 3 and libsoup 2. It is obsolete and users should immediately port to webkit2gtk-4.1. To get this with WebKitGTK 2.40, build with -DPORT=GTK -DUSE_SOUP2=ON.
webkit2gtk-4.1: this API version uses GTK 3 and libsoup 3. It contains no other changes from webkit2gtk-4.0 besides the libsoup version. With WebKitGTK 2.40, this is the default API version that you get when you build with -DPORT=GTK. (In 2.42, this might require a different flag, e.g. -DUSE_GTK3=ON, which does not exist yet.)
webkitgtk-6.0: this API version uses GTK 4 and libsoup 3. To get this with WebKitGTK 2.40, build with -DPORT=GTK -DUSE_GTK4=ON. (In 2.42, this might become the default API version.)
WebKitGTK 2.38 had a different GTK 4 API version, webkit2gtk-5.0. This was an unstable/development API version and it is gone in 2.40, so applications using it will break. Fortunately, that should be very few applications. If your operating system ships GNOME 42, or any older version, or the new GNOME 44, then no applications use webkit2gtk-5.0 and you have no extra work to do. But for operating systems that ship GNOME 43, webkit2gtk-5.0 is used by gnome-builder, gnome-initial-setup, and evolution-data-server:
For evolution-data-server 3.46, use this patch which applies on evolution-data-server 3.46.4.
For gnome-initial-setup 43, use this patch which applies on gnome-initial-setup 43.2. (Update: for your convenience, this patch will be included in gnome-initial-setup 43.3.)
For gnome-builder 43, all required changes are present in version 43.7.
Remember, patching is only needed for GNOME 43. Other versions of GNOME will have no problems with WebKitGTK 2.40.
There is no proper online documentation yet, but in the meantime you can view the markdown source for the migration guide to help you with porting your applications. Although the API is now stable and it is close to feature parity with the GTK 3 version, there are some problems to be aware of:
No support for accessibility. The GTK and WebKitGTK developers are collaborating on a plan to fix this, and I hope this will be ready for WebKitGTK 2.42.
Various smaller regressions here and there. The GTK 4 version is almost as stable as GTK 3, and now is a good time to start using it. As with any interesting new software, there is still some work to do.
Big thanks to everyone who helped make this possible.
Today, WebKit in Linux operating systems is much more secure than it used to be. The problems that I previously discussed in this old, formerly-popular blog post are nowadays a thing of the past. Most major Linux operating systems now update WebKitGTK and WPE WebKit on a regular basis to ensure known vulnerabilities are fixed. (Not all Linux operating systems include WPE WebKit. It’s basically WebKitGTK without the dependency on GTK, and is the best choice if you want to use WebKit on embedded devices.) All major operating systems have removed older, insecure versions of WebKitGTK (“WebKit 1”) that were previously a major security problem for Linux users. And today WebKitGTK and WPE WebKit both provide a webkit_web_context_set_sandbox_enabled() API which, if enabled, employs Linux namespaces to prevent a compromised web content process from accessing your personal data, similar to Flatpak’s sandbox. (If you are a developer and your application does not already enable the sandbox, you should fix that!)
Unfortunately, QtWebKit has not benefited from these improvements. QtWebKit was removed from the upstream WebKit codebase back in 2013. Its current status in Fedora is, unfortunately, representative of other major Linux operating systems. Fedora currently contains two versions of QtWebKit:
The qtwebkit package contains upstream QtWebKit 2.3.4 from 2014. I believe this is used by Qt 4 applications. For avoidance of doubt, you should not use applications that depend on a web engine that has not been updated in eight years.
The newer qt5-qtwebkit contains Konstantin Tokarev’s fork of QtWebKit, which is de facto the new upstream and without a doubt the best version of QtWebKit available currently. Although it has received occasional updates, most recently 5.212.0-alpha4 from March 2020, it’s still based on WebKitGTK 2.12 from 2016, and the release notes bluntly state that it’s not very safe to use. Looking at WebKitGTK security advisories beginning with WSA-2016-0006, I manually counted 507 CVEs that have been fixed in WebKitGTK 2.14.0 or newer.
These CVEs are mostly (but not exclusively) remote code execution vulnerabilities. Many of those CVEs no doubt correspond to bugs that were introduced more recently than 2.12, but the exact number is not important: what’s important is that it’s a lot, far too many for backporting security fixes to be practical. Since qt5-qtwebkit is two years newer than qtwebkit, the qtwebkit package is no doubt in even worse shape. And because QtWebKit does not have any web process sandbox, any remote code execution is game over: an attacker that exploits QtWebKit gains full access to your user account on your computer, and can steal or destroy all your files, read all your passwords out of your password manager, and do anything else that your user account can do with your computer. In contrast, with WebKitGTK or WPE WebKit’s web process sandbox enabled, attackers only get access to content that’s mounted within the sandbox, which is a much more limited environment without access to your home directory or session bus.
In short, it’s long past time for Linux operating systems to remove QtWebKit and everything that depends on it. Do not feed untrusted data into QtWebKit. Don’t give it any HTML that you didn’t write yourself, and certainly don’t give it anything that contains injected data. Uninstall it and whatever applications depend on it.
Update: I forgot to mention what to do if you are a developer and your application still uses QtWebKit. You should ensure it uses the most recent release of QtWebEngine for Qt 6. Do not use old versions of Qt 6, and do not use QtWebEngine for Qt 5.
Nearly five years ago, when I was in grad school, I stumbled across the paper Collaboration in the open-source arena: The WebKit case when trying to figure out what I would do for a course project in network theory (i.e. graph theory, not computer networking; I’ll use the words “graph” and “network” interchangeably). The paper evaluates collaboration networks, which are graphs where collaborators are represented by nodes and relationships between collaborators are represented by edges. Our professor had used collaboration networks as examples during lecture, so it seemed at least mildly relevant to our class, and I wound up writing a critique on this paper for the class project. In this paper, the authors construct collaboration networks for WebKit by examining the project’s changelog files to define relationships between developers. They perform “community detection” to visually group developers who work closely together into separate clusters in the graphs. Then, the authors use those graphs to arrive at various conclusions about WebKit (e.g. “[e]ven if Samsung and Apple are involved in expensive patent wars in the courts and stopped collaborating on hardware components, their contributions remained strong and central within the WebKit open source project,” regarding the period from 2008 to 2013).
At the time, I contacted the authors to let them know about some serious problems I found with their work. Then I left the paper sitting in a short-term to-do pile on my desk, where it has been sitting since Obama was president, waiting for me to finally write this blog post. Unfortunately, nearly five years later, the authors’ email addresses no longer work, which is not very surprising after so long — since I’m no longer a student, the email I originally used to contact them doesn’t work anymore either — so I was unable to contact them again to let them know that I was finally going to publish this blog post. Anyway, suffice to say that the conclusions of the paper were all correct; however, the networks used to arrive at those conclusions suffered from three different mistakes, each of which was, on its own, serious enough to invalidate the entire work.
So if the analysis of the networks was bogus, how did the authors arrive at correct conclusions anyway? The answer is confirmation bias. The study was performed by visually looking at networks and then coming to non-rigorous conclusions about the networks, and by researching the WebKit community to learn what is going on with the major companies involved in the project. The authors arrived at correct conclusions because they did a good job at the latter, then saw what they wanted to see in the graphs.
I don’t want to be too harsh on the authors of this paper, though, because they decided to publish their raw data and methodology on the internet. They even published the python scripts they used to convert WebKit changelogs into collaboration graphs. Had they not done so, there is no way I would have noticed the third (and most important) mistake that I’ll discuss below, and I wouldn’t have been able to confirm my suspicions about the second mistake. You would not be reading this right now, and likely nobody would ever have realized the problems with the paper. The authors of most scientific papers are not nearly so transparent: many researchers today consider their source code and raw data to be either proprietary secrets to be guarded, or simply not important enough to merit publication. The authors of this paper deserve to be commended, not penalized, for their openness. Mistakes are normal in research papers, and open data is by far the best way for us to be able to detect mistakes when they happen.
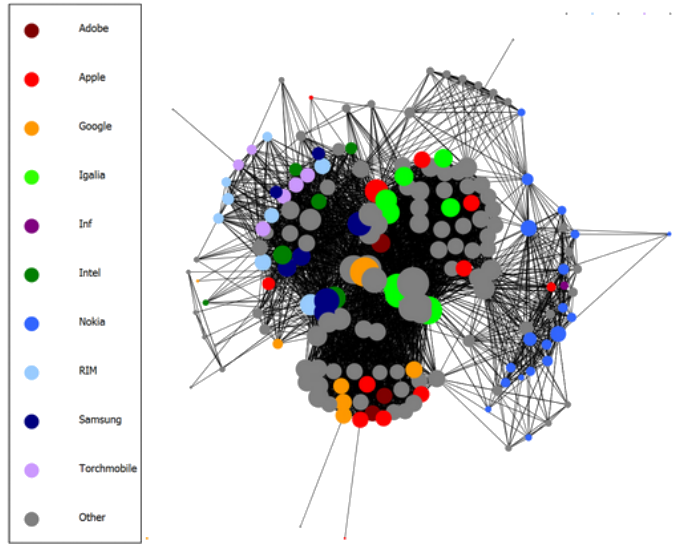
A collaboration network from the paper. The paper reports that this network represents collaboration between September 2008 (when Google began contributing to WebKit) and February 2011 (the departure of Nokia from the project). Because the authors posted their data online, I noticed that this was a mistake in the paper: the graph actually represents the period between February 2011 and July 2012. The paper’s analysis of this graph is therefore questionable, but note this was only a minor mistake compared to the three major mistakes that impact this network. Note the suspiciously-high number of unaffiliated (“Other”) contributors in a corporate-dominated project.
The rest of this blog post is a simplified version of my original school paper from 2016. I’ve removed maybe half the original content, including some flowery academic language and unnecessary references to class material (e.g. “community detection was performed using fast modularity maximization to generate an alternate visualization of the network,” good for high scores on class papers, not so good for blog posts). But rewriting everything to be informal takes a long time, and I want to finish this today so it’s not still on my desk five more years from now, so the rest of this blog post is still going to be much more formal than normal. Oh well. Tone shift now!
We (“we” means “I”) examine various methodological issues discovered by analyzing the paper. The first section discusses the effects on the collaboration network of choosing a poor definition of collaboration. The second section discusses a major source of error in detecting the company affiliation of many contributors. The third section describes a serious mistake in the data collection process. Each of these issues is quite severe, and any one alone calls into question the validity of the entire study. It must be noted that such issues are not necessarily unique to this paper, and must be kept in mind for all future studies that utilize collaboration networks.
Mistake #1: Poorly-defined Collaboration
The precise definition used to model collaboration has tremendous impact on the usefulness of the resultant collaboration network. Many collaboration networks are built using definitions of collaboration that are self-evidently useful, where there is little doubt that edges in the network represent real-world collaboration. The paper adopts an approach to building collaboration networks where developers are represented by nodes, and an edge exists between two nodes if the corresponding developers modified the same source code file during the time period under consideration for the construction of the network. However, it is not clear that this definition of collaboration is actually useful. Consider that it is a regular occurrence for developers who do not know each other and may have never communicated to modify the same files. Consider also that modifying a common file does not necessarily reflect any shared interest in a particular portion of the software project. For instance, a file might be modified when making an interface change in another file, or when fixing a build error occurring on a particular platform. Such occurrences are, in fact, extremely common in the WebKit project. Additionally, consider that there exist particular source code files that are unusually central to the project, and must be modified more frequently than other files. It is highly likely that almost all developers will at one point or another make some change in such a file, and therefore be connected via a collaboration edge to all other developers who have ever modified that file. (My original critique shows a screenshot of the revision history of WebPageProxy.cpp, to demonstrate that the developers modifying this file were working on unrelated projects.)
It is true, as assumed by the paper, that particular developers work on different portions of the WebKit source code, and collaborate more with particular other developers. For instance, developers who work for the same company typically, though not always, collaborate most with other developers from that same company. However, the paper’s naive definition of collaboration should ensure that most developers will be considered to have collaborated equally with most other developers, regardless of the actual degree of collaboration. For instance, consider developers A and B who regularly collaborate on a particular source file. Now, developer C, who works on a platform that does not use this file and would not ordinarily need to modify it, makes a change to some cross-platform interface in another file that requires updating this file. Developer C is now considered to have collaborated with developers A and B on this file! Clearly, this is not a desirable result, as developers A and B have collaborated far more on the development of the file. Moreover, consider that an edge exists between two developers in the collaboration network if they have ever both modified any file anywhere in WebKit during the time period under review; then we can expect to form a network that is almost complete (a “full” graph where edges exists between most nodes). It is evident that some method of weighting collaboration between different contributors would be desirable, as the unweighted collaboration network does not seem useful.
One might argue that the networks presented in the paper clearly show developers exist in subcommunities on the peripheries of the network, that the network is clearly not complete, and that therefore this definition of collaboration sufficed, at least to some extent. However, this is only due to another methodological error in the study. Mistake #3, discussed later, explains how the study managed to produce collaboration networks with noticeable subcommunities despite these issues.
We note that the authors chose this same definition of collaboration in their more recent work on OpenStack, so there exist multiple studies using this same flawed definition of collaboration. We speculate that this definition of collaboration is unlikely to be more suitable for OpenStack or for other software projects than it is for WebKit. The software engineering research community must explore alternative models of collaboration when undertaking future studies of software development collaboration networks in order to more accurately reflect collaboration.
Mistake #2: Misdetected Contributor Affiliation
One difficulty when building collaboration networks is the need to correctly match each contributor with the correct company affiliation. Although many free software projects are dominated by unaffiliated contributors, others, like WebKit, are primarily developed by paid contributors. Looking at the number of times a particular email domain appears in WebKit changelog entries made during 2015, most contributors commit using corporate emails, but many developers commit to WebKit using personal email accounts, such as Gmail accounts; additionally, many developers use generic webkit.org email aliases, which were previously available to active WebKit contributors. These developers may or may not be affiliated with companies that contribute to the project. Use of personal email addresses is a source of inaccuracy when constructing collaboration networks, as it results in an undercount of corporate contributions. We can expect this issue has led to serious inaccuracies in the reported collaboration networks.
This substantial source of error is neither mentioned nor accounted for; all contributors using such email accounts were therefore miscategorized as unaffiliated. However, the authors clearly recognized this issue, as it has been accounted for in their more recent work covering OpenStack by cross-referencing email addresses from git revision history with a database containing corporate affiliations maintained by the OpenStack Foundation. Unfortunately, no such effort was made for the WebKit data set.
The WebKit project was previously dominated by contributors with chromium.org email domains. This domain is equivalent to webkit.org in that it can be used by contributors to the Chromium project regardless of corporate affiliation; however, most contributors with Chromium emails are actually Google employees. The high use of Chromium emails by Google employees appears to have led to a dramatic — by roughly an entire order of magnitude — undercount of Google’s contributors to the WebKit project, as only contributors with google.com emails were considered to be Google employees. The vast majority of Google employees used chromium.org emails, and so were counted as unaffiliated developers. This explains the extraordinarily high number of unaffiliated developers in the networks presented by the paper, despite the fact that WebKit development is, in reality, dominated by corporate contributors.
Mistake #3: Missing Most Changelog Data
The paper incorrectly claims to have gathered its data from both WebKit’s Subversion revision history and from its changelog files. We must draw a distinction between changelog entries and Subversion revision history. Changelog entries are inserted into changelog files that are committed into the Subversion repository; they are completely separate from the Subversion history. Each subproject within the WebKit project has its own set of changelog files used to record changes under the corresponding directory.
In fact, the paper processed only the changelog files. This was actually a good choice, as WebKit’s changelog files are much more accurate than the Subversion history, for two reasons. Firstly, it is easy for a contributor to change the email address entered into a changelog file, e.g. after a change in company affiliation. However, it is difficult to change the email address used to commit to Subversion, as this requires requesting a new Subversion account from the Subversion administrator; accordingly, contributors are more likely to use older email addresses, lacking accurate company affiliation, in Subversion revisions than in changelog files. Secondly, many Subversion revisions are not directly committed by contributors, but rather are actually committed by the commit queue bot, which runs various tests before committing the revision. Subversion revisions are also, more rarely, committed by a completely different contributor than the patch author. In both cases, the proper contributor’s name will appear in only the changelog file, and not the Subversion data. Some developers are dramatically more likely to use the commit queue than others. Various other reviews of WebKit contribution history that examine data from Subversion history rather than from changelog files are flawed for this reason. Fortunately, by relying on changelog files rather than Subversion metadata, the authors avoid this problem.
Unfortunately, a serious error was made in processing the changelog data. WebKit has many different sets of changelog files, stored in various project subdirectories (JavaScriptCore, WebCore, WebKit, etc.), as well as toplevel changelogs stored in the root directory of the project. Regrettably, the authors were unaware of the changelogs in subdirectories, and based their analysis only on the toplevel changelogs, which contain only changes that occurred in subdirectories that lack their own changelog files. In practice, this inadvertently restricted the scope of the analysis to a very small minority of changes, primarily to build system files, manual tests, and the WebKit website. That is, the reported collaboration networks do not reflect collaboration on any actual source code files. All source code files are contained in subdirectories with their own changelog files, and therefore no source code files were actually considered in the analysis of collaboration on source code changes.
We speculate that the analysis’s focus on build system files likely exaggerates the effects of clustering in the network, as different companies used different build systems and thus were less likely to edit the build systems used by other companies, and that an analysis based on the correct data would display less of a clustering effect. Certainly, there would be dramatically more edges in the already-dense networks, because an edge exists between two developers if there exists any one file in WebKit that both developers have modified. Omitting all of the source code files from the analysis therefore dramatically reduces the likelihood of edges existing between nodes in the network.
Conclusion
We found that the original study was impacted by an unsuitable definition of collaboration used to build the collaboration networks, severe errors in counting contributor affiliation (including the classification of most Google employees as unaffiliated developers), and the omission of almost all the required data from the analysis, including all data on modifications to source code files. The authors constructed and studied essentially meaningless networks. Nevertheless, the authors were able to derive many accurate conclusions about the WebKit project from their inaccurate collaboration networks. Such conclusions illustrate the dangers of seeking to find particular meanings or explanations through visual inspection of collaboration networks. Researchers must work forwards from the collaboration networks to arrive at their conclusions, rather than backwards by attempting to match the networks to conclusions gained from prior knowledge.
Original Report
Wow, OK, you actually read this far? Since this blog post criticizes an academic paper, and since this blog post does not include various tables and examples that support my arguments, I’ve attached my original analysis in full. It is a boring, student-quality grad school project written with the objective of scoring the highest-possible grade in a class rather than for clarity, and you probably don’t want to look at it unless you are investigating the paper in detail. (If you download that, note that I no longer work for Igalia, and the paper was not authorized by Igalia either; I used my company email to disclose my affiliation and maybe impress my professor a little.) Phew, now I can finally remove this from my desk!
It’s that time of year again: a new GNOME release, and with it, a new Epiphany. The pace of Epiphany development has increased significantly over the last few years thanks to an increase in the number of active contributors. Most notably, Jan-Michael Brummer has solved dozens of bugs and landed many new enhancements, Alexander Mikhaylenko has polished numerous rough edges throughout the browser, and Andrei Lisita has landed several significant improvements to various Epiphany dialogs. That doesn’t count the work that Igalia is doing to maintain WebKitGTK, the WPE graphics stack, and libsoup, all of which is essential to delivering quality Epiphany releases, nor the work of the GNOME localization teams to translate it to your native language. Even if Epiphany itself is only the topmost layer of this technology stack, having more developers working on Epiphany itself allows us to deliver increased polish throughout the user interface layer, and I’m pretty happy with the result. Let’s take a look at what’s new.
Intelligent Tracking Prevention
Intelligent Tracking Prevention (ITP) is the headline feature of this release. Safari has had ITP for several years now, so if you’re familiar with how ITP works to prevent cross-site tracking on macOS or iOS, then you already know what to expect here. If you’re more familiar with Firefox’s Enhanced Tracking Protection, or Chrome’s nothing (crickets: chirp, chirp!), then WebKit’s ITP is a little different from what you’re used to. ITP relies on heuristics that apply the same to all domains, so there are no blocklists of naughty domains that should be targeted for content blocking like you see in Firefox. Instead, a set of innovative restrictions is applied globally to all web content, and a separate set of stricter restrictions is applied to domains classified as “prevalent” based on your browsing history. Domains are classified as prevalent if ITP decides the domain is capable of tracking your browsing across the web, or non-prevalent otherwise. (The public-friendly terminology for this is “Classification as Having Cross-Site Tracking Capabilities,” but that is a mouthful, so I’ll stick with “prevalent.” It makes sense: domains that are common across many websites can track you across many websites, and domains that are not common cannot.)
ITP is enabled by default in Epiphany 3.38, as it has been for several years now in Safari, because otherwise only a small minority of users would turn it on. ITP protections are designed to be effective without breaking too many websites, so it’s fairly safe to enable by default. (You may encounter a few broken websites that have not been updated to use the Storage Access API to store third-party cookies. If so, you can choose to turn off ITP in the preferences dialog.)
For a detailed discussion covering ITP’s tracking mitigations, see Tracking Prevention in WebKit. I’m not an expert myself, but the short version is this: full third-party cookie blocking across all websites (to store a third-party cookie, websites must use the Storage Access API to prompt the user for permission); cookie-blocking latch mode (“once a request is blocked from using cookies, all redirects of that request are also blocked from using cookies”); downgraded third-party referrers (“all third-party referrers are downgraded to their origins by default”) to avoid exposing the path component of the URL in the referrer; blocked third-party HSTS (“HSTS […] can only be set by the first-party website […]”) to stop abuse by tracker scripts; detection of cross-site tracking via link decoration and 24-hour expiration time for all cookies created by JavaScript on the landing page when detected; a 7-day expiration time for all other cookies created by JavaScript (yes, this applies to first-party cookies); and a 7-day extendable lifetime for all other script-writable storage, extended whenever the user interacts with the website (necessary because tracking companies began using first-party scripts to evade the above restrictions). Additionally, for prevalent domains only, domains engaging in bounce tracking may have cookies forced to SameSite=strict, and Verified Partitioned Cache is enabled (cached resources are re-downloaded after seven days and deleted if they fail certain privacy tests). Whew!
WebKit has many additional privacy protections not tied to the ITP setting and therefore not discussed here — did you know that cached resources are partioned based on the first-party domain? — and there’s more that’s not very well documented which I don’t understand and haven’t mentioned (tracker collusion!), but that should give you the general idea of how sophisticated this is relative to, say, Chrome (chirp!). Thanks to John Wilander from Apple for his work developing and maintaining ITP, and to Carlos Garcia for getting it working on Linux. If you’re interested in the full history of how ITP has evolved over the years to respond to the changing threat landscape (e.g. tracking prevention tracking), see John’s WebKit blog posts. You might also be interested in WebKit’s Tracking Prevention Policy, which I believe is the strictest anti-tracking stance of any major web engine. TL;DR: “we treat circumvention of shipping anti-tracking measures with the same seriousness as exploitation of security vulnerabilities. If a party attempts to circumvent our tracking prevention methods, we may add additional restrictions without prior notice.” No exceptions.
Updated Website Data Preferences
As part of the work on ITP, you’ll notice that Epiphany’s cookie storage preferences have changed a bit. Since ITP enforces full third-party cookie blocking, it no longer makes sense to have a separate cookie storage preference for that, so I replaced the old tri-state cookie storage setting (always accept cookies, block third-party cookies, block all cookies) with two switches: one to toggle ITP, and one to toggle all website data storage.
Previously, it was only possible to block cookies, but this new setting will additionally block localStorage and IndexedDB, web features that allow websites to store arbitrary data in your browser, similar to cookies. It doesn’t really make much sense to block cookies but allow other types of data storage, so the new preferences should better enforce the user’s intent behind disabling cookies. (This preference does not yet block media keys, service workers, or legacy offline web application cache, but it probably should.) I don’t really recommend disabling website data storage, since it will cause compatibility issues on many websites, but this option is there for those who want it. Disabling ITP is also not something I want to recommend, but it might be necessary to access certain broken websites that have not yet been updated to use the Storage Access API.
Accordingly, Andrei has removed the old cookies dialog and moved cookie management into the Clear Personal Data dialog, which is a better place because anyone clearing cookies for a particular website is likely to also want to clear other personal data. (If you want to delete a website’s cookies, then you probably don’t want to leave its SQL databases intact, right?) He had to remove the ability to clear data from a particular point in time, because WebKit doesn’t support this operation for cookies, but that function is probably rarely-used and I think the benefit of the change should outweigh the cost. (We could bring it back in the future if somebody wants to try implementing that feature in WebKit, but I suspect not many users will notice.) Treating cookies as separate and different from other forms of website data storage no longer makes sense in 2020, and it’s good to have finally moved on from that antiquated practice.
New HTML Theme
Carlos Garcia has added a new Adwaita-based HTML theme to WebKitGTK 2.30, and removed support for rendering HTML elements using the GTK theme (except for scrollbars). Trying to use the GTK theme to render web content was fragile and caused many web compatibility problems that nobody ever managed to solve. The GTK developers were never very fond of us doing this in the first place, and the foreign drawing API required to do so has been removed from GTK 4, so this was also good preparation for getting WebKitGTK ready for GTK 4. Carlos’s new theme is similar to Adwaita, but gradients have been toned down or removed in order to give a flatter, neutral look that should blend in nicely with all pages while still feeling modern.
This should be a fairly minor style change for Adwaita users, but a very large change for anyone using custom themes. I don’t expect everyone will be happy, but please trust that this will at least result in better web compatibility and fewer tricky theme-related bug reports.
Left: Adwaita GTK theme controls rendered by WebKitGTK 2.28. Right: hardcoded Adwaita-based HTML theme with toned down gradients.
Although scrollbars will still use the GTK theme as of WebKitGTK 2.30, that will no longer be possible to do in GTK 4, so themed scrollbars are almost certain to be removed in the future. That will be a noticeable disappointment in every app that uses WebKitGTK, but I don’t see any likely solution to this.
Media Permissions
Jan-Michael added new API in WebKitGTK 2.30 to allow muting individual browser tabs, and hooked it up in Epiphany. This is good when you want to silence just one annoying tab without silencing everything.
Meanwhile, Charlie Turner added WebKitGTK API for managing autoplay policies. Videos with sound are now blocked from autoplaying by default, while videos with no sound are still allowed. Charlie hooked this up to Epiphany’s existing permission manager popover, so you can change the behavior for websites you care about without affecting other websites.
Configure your preferred media autoplay policy for a website near you today!
Improved Dialogs
In addition to his work on the Clear Data dialog, Andrei has also implemented many improvements and squashed bugs throughout each view of the preferences dialog, the passwords dialog, and the history dialog, and refactored the code to be much more maintainable. Head over to his blog to learn more about his accomplishments. (Thanks to Google for sponsoring Andrei’s work via Google Summer of Code, and to Alexander for help mentoring.)
Additionally, Adrien Plazas has ported the preferences dialog to use HdyPreferencesWindow, bringing a pretty major design change to the view switcher:
Left: Epiphany 3.36 preferences dialog. Right: Epiphany 3.38. Note the download settings are present in the left screenshot but missing from the right screenshot because the right window is using flatpak, and the download settings are unavailable in flatpak.
User Scripts
User scripts (like Greasemonkey) allow you to run custom JavaScript on websites. WebKit has long offered user script functionality alongside user CSS, but previous versions of Epiphany only exposed user CSS. Jan-Michael has added the ability to configure a user script as well. To enable, visit the Appearance tab in the preferences dialog (a somewhat odd place, but it really needs to be located next to user CSS due to the tight relationship there). Besides allowing you to do, well, basically anything, this also significantly enhances the usability of user CSS, since now you can apply certain styles only to particular websites. The UI is a little primitive — your script (like your CSS) has to be one file that will be run on every website, so don’t try to design a complex codebase using your user script — but you can use conditional statements to limit execution to specific websites as you please, so it should work fairly well for anyone who has need of it. I fully expect 99.9% of users will never touch user scripts or user styles, but it’s nice for power users to have these features available if needed.
HTTP Authentication Password Storage
Jan-Michael and Carlos Garcia have worked to ensure HTTP authentication passwords are now stored in Epiphany’s password manager rather than by WebKit, so they can now be viewed and deleted from Epiphany, which required some new WebKitGTK API to do properly. Unfortunately, WebKitGTK saves network passwords using the default network secret schema, meaning its passwords (saved by older versions of Epiphany) are all leaked: we have no way to know which application owns those passwords, so we don’t have any way to know which passwords were stored by WebKit and which can be safely managed by Epiphany going forward. Accordingly, all previously-stored HTTP authentication passwords are no longer accessible; you’ll have to use seahorse to look them up manually if you need to recover them. HTTP authentication is not very commonly-used nowadays except for internal corporate domains, so hopefully this one-time migration snafu will not be a major inconvenience to most users.
New Tab Animation
Jan-Michael has added a new animation when you open a new tab. If the newly-created tab is not visible in the tab bar, then the right arrow will flash to indicate success, letting you know that you actually managed to open the page. Opening tabs out of view happens too often currently, but at least it’s a nice improvement over not knowing whether you actually managed to open the tab or not. This will be improved further next year, because Alexander is working on a completely new tab widget to replace GtkNotebook.
New View Source Theme
Jim Mason changed view source mode to use a highlight.js theme designed to mimic Firefox’s syntax highlighting, and added dark mode support.
I added a new WebKitGTK 2.30 API to expose the paste as plaintext editor command, which was previously internal but fully-functional. I’ve hooked it up in Epiphany’s context menu as “Paste Text Only.” This is nice when you want to discard markup when pasting into a rich text editor (such as the WordPress editor I’m using to write this post).
Jan-Michael has implemented support for reordering pinned tabs. You can now drag to reorder pinned tabs any way you please, subject to the constraint that all pinned tabs stay left of all unpinned tabs.
Jan-Michael added a new import/export menu, and the bookmarks import/export features have moved there. He also added a new feature to import passwords from Chrome. Meanwhile, ignapk added support for importing bookmarks from HTML (compatible with Firefox).
Jan-Michael added a new preference to web apps to allow running them in the background. When enabled, closing the window will only hide the the window: everything will continue running. This is useful for mail apps, music players, and similar applications.
Continuing Jan-Michael’s list of accomplishments, he removed Epiphany’s previous hidden setting to set a mobile user agent header after discovering that it did not work properly, and replaced it by adding support in WebKitGTK 2.30 for automatically setting a mobile user agent header depending on the chassis type detected by logind. This results in a major user experience improvement when using Epiphany as a mobile browser. Beware: this functionality currently does not work in flatpak because it requires the creation of a new desktop portal.
Stephan Verbücheln has landed multiple fixes to improve display of favicons on hidpi displays.
Zach Harbort fixed a rounding error that caused the zoom level to display oddly when changing zoom levels.
Vanadiae landed some improvements to the search engine configuration dialog (with more to come) and helped investigate a crash that occurs when using the “Set as Wallpaper” function under Flatpak. The crash is pretty tricky, so we wound up disabling that function under Flatpak for now. He also updated screenshots throughout the user help.
Sabri Ünal continued his effort to document and standardize keyboard shortcuts throughout GNOME, adding a few missing shortcuts to the keyboard shortcuts dialog.
When you connect to a Wi-Fi network, that network might block your access to the wider internet until you’ve signed into the network’s captive portal page. An untrusted network can disrupt your connection at any time by blocking secure requests and replacing the content of insecure requests with its login page. (Of course this can be done on wired networks as well, but in practice it mainly happens on Wi-Fi.) To detect a captive portal, NetworkManager sends a request to a special test address (e.g. http://fedoraproject.org/static/hotspot.txt) and checks to see whether it the content has been replaced. If so, GNOME Shell will open a little WebKitGTK browser window to display http://nmcheck.gnome.org, which, due to the captive portal, will be hijacked by your hotel or airport or whatever to display the portal login page. Rephrased in security lingo: an untrusted network may cause GNOME Shell to load arbitrary web content whenever it wants. If that doesn’t immediately sound dangerous to you, let’s ask me from four years ago why that might be bad:
Web engines are full of security vulnerabilities, like buffer overflows and use-after-frees. The details don’t matter; what’s important is that skilled attackers can turn these vulnerabilities into exploits, using carefully-crafted HTML to gain total control of your user account on your computer (or your phone). They can then install malware, read all the files in your home directory, use your computer in a botnet to attack websites, and do basically whatever they want with it.
If the web engine is sandboxed, then a second type of attack, called a sandbox escape, is needed. This makes it dramatically more difficult to exploit vulnerabilities.
The captive portal helper will pop up and load arbitrary web content without user interaction, so there’s nothing you as a user could possibly do about it. This makes it a tempting target for attackers, so we want to ensure that users are safe in the absence of a sandbox escape. Accordingly, beginning with GNOME 3.36, the captive portal helper is now sandboxed.
How did we do it? With basically one line of code (plus a check to ensure the WebKitGTK version is new enough). To sandbox any WebKitGTK app, just call webkit_web_context_set_sandbox_enabled(). Ta-da, your application is now magically secure!
No, really, that’s all you need to do. So if it’s that simple, why isn’t the sandbox enabled by default? It can break applications that use WebKitWebExtension to run custom code in the sandboxed web process, so you’ll need to test to ensure that your application still works properly after enabling the sandbox. (The WebKitGTK sandbox will become mandatory in the future when porting applications to GTK 4. That’s thinking far ahead, though, because GTK 4 isn’t supported yet at all.) You may need to use webkit_web_context_add_path_to_sandbox() to give your web extension access to directories that would otherwise be blocked by the sandbox.
The sandbox is critically important for web browsers and email clients, which are constantly displaying untrusted web content. But really, every app should enable it. Fix your apps! Then thank Patrick Griffis from Igalia for developing WebKitGTK’s sandbox, and the bubblewrap, Flatpak, and xdg-desktop-portal developers for providing the groundwork that makes it all possible.
Once upon a time, beginning with GNOME 3.14, Epiphany had supported displaying PDF documents via the Evince NPAPI browser plugin developed by Carlos Garcia Campos. Unfortunately, because NPAPI plugins have to use X11-specific APIs to draw web content, this didn’t suffice for very long. When GNOME switched to Wayland by default in GNOME 3.24 (yes, that was three years ago!), this functionality was left behind. Using an NPAPI plugin also meant the code was inherently unsandboxable and tied to a deprecated technology. Epiphany disabled support for NPAPI plugins by default in Epiphany 3.30, hiding the functionality behind a hidden setting, which has now finally been removed for Epiphany 3.36, killing off NPAPI for good.
Jan-Michael Brummer, who comaintains Epiphany with me, tried bringing back PDF support for Epiphany 3.34 using libevince, but eventually we decided to give up on this approach due to difficulty solving some user experience issues. Also, the rendering occurred in the unsandboxed UI process, which was again not good for security.
But PDF support is now back in Epiphany 3.36, and much better than before! Thanks to Jan-Michael, Epiphany now supports displaying PDFs using the amazing PDF.js. We are thankful for Mozilla’s work in developing PDF.js and open sourcing it for us to use. Viewing PDFs in Epiphany using PDF.js is more convenient than downloading them and opening them in Evince, and because the PDF is rendered in the sandboxed web process, using web technologies rather than poppler, it’s also approximately one bazillion times more secure.
Look, it’s a PDF!
One limitation of PDF.js is that it does not support forms. If you need to fill out PDF forms, you’ll need to download the PDF and open it in Evince, just as you would if using Firefox.
Dark Mode
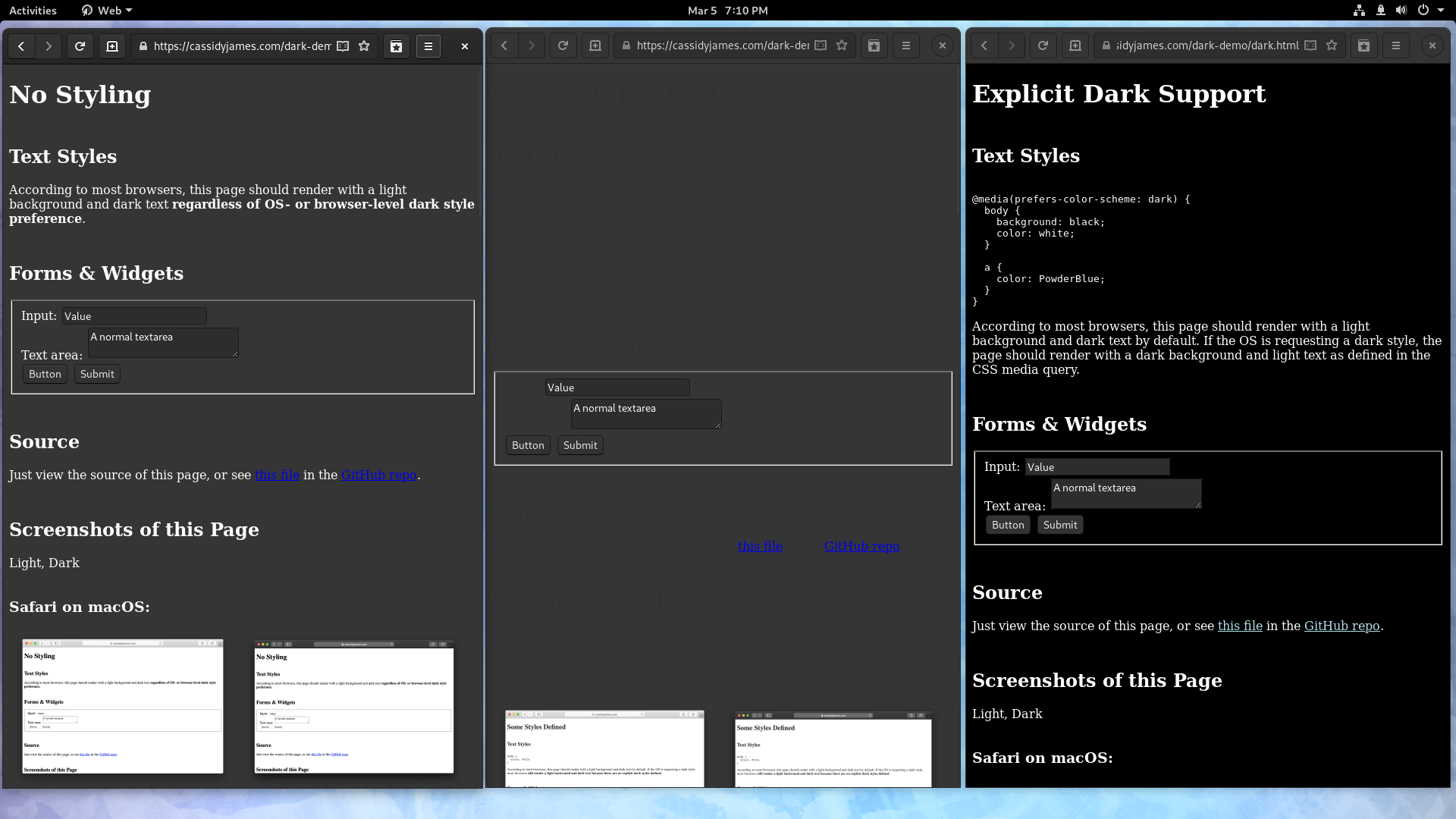
Thanks to Carlos Garcia, it should finally be possible to use Epiphany with dark GTK themes. WebKitGTK has historically rendered HTML elements using the GTK theme, which has not been good for users of dark themes, which broke badly on many websites, usually due to dark text being drawn on dark backgrounds or various other problems with unexpected dark widgets. Since WebKitGTK 2.28, WebKit will try to manually change to a light GTK theme when it thinks a dark theme is in use, then use the light theme to render web content. (This work has actually been backported to WebKitGTK 2.26.4, so you don’t need to upgrade to WebKitGTK 2.28 to benefit, but the work landed very recently and we haven’t blogged about it yet.) Thanks to Cassidy James from elementary for providing example pages for testing dark mode behavior.
Broken dark mode support prior to WebKitGTK 2.26.4. Notice that the first two pages use dark color schemes when light color schemes are expected, and the dark blue links are hard to read over the dark gray background. Also notice that the text in the second image is unreadable.
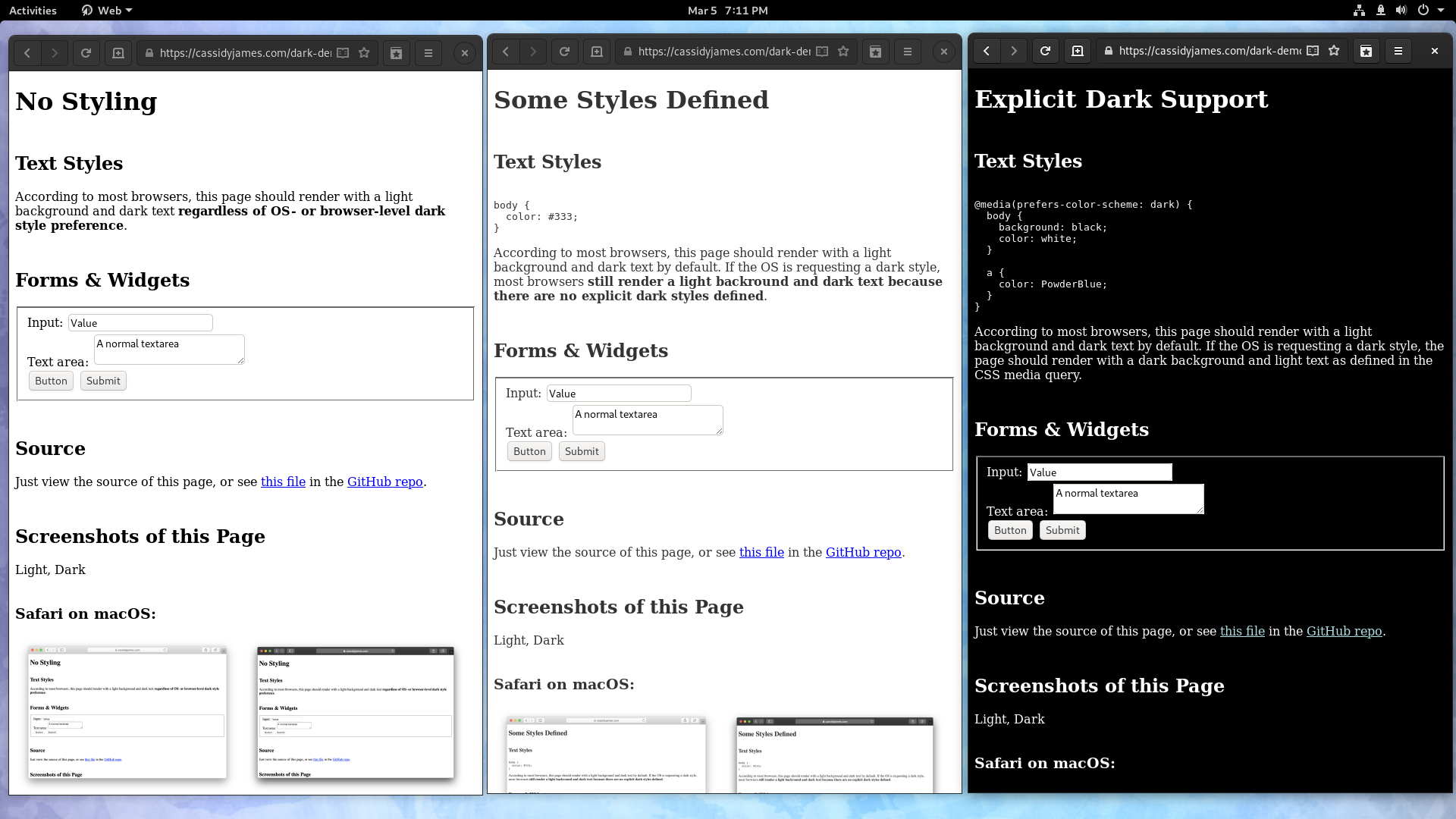
Since WebKitGTK 2.26.4, dark mode works as it does in most other browsers. Websites that don’t support dark mode are light, and websites that do support dark mode are dark. Widgets themed using GTK are always light.
Since Carlos had already added support for the prefers-color-scheme media query last year, this now gets us up to dark mode parity with most browsers, except, notably, Safari. Unlike other browsers, Safari allows websites to opt-in to rendering dark system widgets, like WebKitGTK used to do before these changes. Whether to support this in WebKitGTK remains to-be-determined.
Process Swap on Navigation (PSON)
PSON, which debuted in Safari 13, is a major change in WebKit’s process model. PSON is the first component of site isolation, which Chrome has supported for some time, and which Firefox is currently working towards. If you care about web security, you should care a lot about site isolation, because the web browser community has arrived at a consensus that this is the best way to mitigate speculative execution attacks.
Nowadays, all modern web browsers use separate, sandboxed helper processes to render web content, ensuring that the main user interface process, which is unsandboxed, does not touch untrusted web content. Prior to 3.36, Epiphany already used a separate web process to display each browser tab (except for “related views,” where one tab opens another and gains scripting ability over the opened tab, subject to the Same Origin Policy). But in Epiphany 3.36, we now also have a separate web process per website. Each tab will swap between different web processes when navigating between different websites, to prevent any one web process from loading content from different websites.
To make these process swap navigations fast, a pool of prewarmed processes is used to hide the startup cost of launching a new process by ensuring the new process exists before it’s needed; otherwise, the overhead of launching a new web process to perform the navigation would become noticeable. And suspended processes live on after they’re no longer in use because they may be needed for back/forward navigations, which use WebKit’s page cache when possible. (In the page cache, pages are kept in memory indefinitely, to make back/forward navigations fast.)
Due to internal refactoring, PSON previously necessitated some API breakage in WebKitGTK 2.26 that affected Evolution and Geary: WebKitGTK 2.26 deprecated WebKit’s single web process model and required that all applications use one web process per web view, which Evolution and Geary were not, at the time, prepared to handle. We tried hard to avoid this, because we hate to make behavioral changes that break applications, but in this case we decided it was unavoidable. That was the status quo in 2.26, without PSON, which we disabled just before releasing 2.26 in order to limit application breakage to just Evolution and Geary. Now, in WebKitGTK 2.28, PSON is finally available for applications to use on an opt-in basis. (It will become mandatory in the future, for GTK 4 applications.) Epiphany 3.36 opts in. To make this work, Carlos Garcia designed new WebKitGTK APIs for cross-process communication, and used them to replace the private D-Bus server that Epiphany previously used for this purpose.
WebKit still has a long way to go to fully implement site isolation, but PSON is a major step down that road. Thanks to Brady Eidson and Chris Dumez from Apple for making this work, and to Carlos Garcia for handling most of the breakage (there was a lot). As with any major intrusive change of such magnitude, regressions are inevitable, so don’t hesitate to report issues on WebKit Bugzilla.
highlight.js
Once upon a time, WebKit had its own implementation for viewing page source, but this was removed from WebKit way back in 2014, in WebKitGTK 2.6. Ever since, Epiphany would open your default text editor, usually gedit, to display page source. Suffice to say that this was not a very satisfactory solution.
I finally managed to implement view source mode at the Epiphany level for Epiphany 3.30, but I had trouble making syntax highlighting work. I tried using various open source syntax highlighting libraries, but most are designed to highlight small amounts of code, not large web pages. The libraries I tried were not fast enough, so I gave up on syntax highlighting at the time.
Thanks to Jan-Michael, Epiphany 3.36 supports syntax highlighting using highlight.js, so we finally have view source mode working fully properly once again. It works much better than my failed attempts with different JS libraries. Please thank the highlight.js developers for maintaining this library, and for making it open source.
Colors!
Service Workers
Service workers are now available in WebKitGTK 2.28. Our friends at Apple had already implemented service worker support a couple years ago for Safari 11, but we were pretty slow in bringing this functionality to Linux. Finally, WebKitGTK should now be up to par with Safari in this regard.
Cookies!
Patrick Griffis has updated libsoup and WebKitGTK to support SameSite cookies. He’s also tightened up our cookie policy by implementing strict secure cookies, which prevents http:// pages from setting secure cookies (as they could overwrite secure cookies set by https:// pages).
Adaptive Design
As usual, there are more adaptive design improvements throughout the browser, to provide a better user experience on the Librem 5. There’s still more work to be done here, but Epiphany continues to provide the best user experience of any Linux browser at small screen sizes. Thanks to Adrien Plazas and Jan-Michael for their continued work on this.
As before, simply resize your browser window to see Epiphany dynamically transition between desktop mode and mobile mode.
elementary OS
With help from Alexander Mikhaylenko, we’ve also upstreamed many elementary OS design changes, which will be used when running under the Pantheon desktop (and not impact users on other desktops), so that the elementary developers don’t need to maintain their customizations as separate patches anymore. This will eliminate a few elementary-specific bugs, including some keyboard shortcuts that were previously broken only in elementary, and some odd tab bar behavior. Although Epiphany still doesn’t feel quite as native as an app designed just for elementary OS, it’s getting closer.
Epiphany 3.34
I failed to blog about Epiphany 3.34 when I released it last September. Hopefully you have updated to 3.34 already, and are already enjoying the two big features from this release: the new adblocker, and the bubblewrap sandbox.
The new adblocker is based on WebKit Content Blockers, which was developed by Apple several years ago. Adrian Perez developed new WebKitGTK API to expose this functionality, changed Epiphany to use it, and deleted Epiphany’s older resource-hungry adblocker that was originally copied from Midori. Previously, Epiphany kept a large GHashMap of compiled regexes in every web process, consuming a very significant amount of RAM for each process. It also took time to compile these regexes when launching each new web process. Now, the adblock filters are instead compiled into an efficient bytecode format that gets mmapped between all web processes to avoid excessive resource use. The bytecode is interpreted by WebKit itself, rather than by Epiphany’s web process extension (which Epiphany uses to execute custom code in WebKit’s web process), for greatly improved performance.
Lastly, Epiphany 3.34 enabled Patrick’s bubblewrap sandbox, which was added in WebKitGTK 2.26. Bubblewrap is an amazing sandboxing tool, already used effectively by flatpak and rpm-ostree, and I’m very pleased with Patrick’s decision to use it for WebKit as well. Because enabling the sandbox can break applications, it is currently opt-in for GTK 3 apps (but will become mandatory for GTK 4 apps). If your application uses WebKitGTK, you really need to take some time to enable this sandbox using webkit_web_context_set_sandbox_enabled(). The sandbox has introduced a couple regressions that we didn’t notice until too late; notably, printing no longer works, which, half a year later, we still haven’t managed to fix yet. (I’ll try to get to it soon.)
OK, this concludes your 3.36 and 3.34 updates. Onward to 3.38!
Epiphany Technology Preview has moved from https://sdk.gnome.org to https://nightly.gnome.org. The old Epiphany Technology Preview is now end-of-life. Action is required to update. If you installed Epiphany Technology Preview prior to a couple minutes ago, uninstall it using GNOME Software and then reinstall using this new flatpakref.
Apologies for this disruption.
The main benefit to end users is that you’ll no longer need separate remotes for nightly runtimes and nightly applications, because everything is now hosted in one repo. See Abderrahim’s announcement for full details on why this transition is occurring.