January 17th, 2010 — General
It’s accepted wisdom that all men are created equal. A lot of people derive from this the idea that all people should be treated equally and have the same rights. It’s the basis for democracy after all. As such, many communities strive to achieve equality and even set it as their explicit goal.
However, in recent times there were two cases that made me doubt in equality as a good goal for any community. The first was the discussion about Fedora’s target audience, in particular defining the target as someone who “is likely to collaborate […] with Fedora” which excludes a whole lot of lazy or uninterested people. The other is Lefty’s surveys where nobody wondered that the surveys assume everyone’s opinion is equally important.
Then there are a lot of places where not having equality is normal and everybody would look at you funny if you were to advocate it. Meritocracy is a very positive world in the open source development communities for example. It’s a known fact that the maintainer decides which patches go in and which don’t. (audio of the talk) So what’s the right way here?
I had a discussion about this with my girlfriend and we found a lot of similar places in the real world where groups wanted to appeal to everyone and ended up being unrecognizable from everyone surrounding them: The Greens for example became just another party without any differences. Apple is in the process of losing it’s style – you’re not special anymore if you have an iPhone or an iPod – everybody has one. And Google does evil these days. All of them saw an increase in “market share” in the process though.
So it seems that in the end it all comes down to this: Is it worth giving up one’s values for more market share?
I personally think everybody who tries to be inclusive is betraying his foundations and original goals. I’m not goint to call it “sells their soul”, because it sounds cheesy, but that’s how it feels to me. So GNOME, please do not give up requesting Freedom. And Fedora, please continue to target the people involved in being bleeding edge. Because the people who are crazy enough to think they can change the world, are the ones who do.
January 4th, 2010 — General
First of all, I need to excuse to my fellow blog readers for never posting a link to the video hackfest conclusions. The page still looks spot-on, maybe apart from the timeline. I’d add half a year to it.
I’ve also just started my new job in Red Hat‘s desktop team. The job description so far just involves hacking on the same old stuff: world domination. I haven’t heard Flash or browsers mentioned, but I think I’ve heard the words video editing and video conferencing. Exciting times ahead for me!
PS: I would have linked my new work email address, but I’m not going to mention it anywhere. These people already had enough Schadenfreude trying to invent connotations for it.
November 21st, 2009 — General
Carl stayed true to his awesomeness from yesterday: He updated the hackfest notes with the things we did today. In particular, it includes “hacking ideas” that we’d like to work on.
I’ve spent a lot of time discussing the ideas of my gst-plugins-cairo design with all people. And I have to say I’m happy to say that the general approach has seen excitement from all sides and there doesn’t seem to be any big issues with it. THe best way to summarize it is probably an event from today: Edward ran a gst-launch pipeline as a benchmark for gst-plugins-cairo and it completed in 0.2 seconds.
November 20th, 2009 — General
The Video hackfest is on!
I originally wanted to summarize the happenings of the day, but Carl took notes: Go read them. I just want to add that I’m very happy with how it’s turning out: Lots of discussions happening all around, the weather is great and the hostel is awesome. Off to bed so I don’t miss any discussions tomorrow…
October 26th, 2009 — General
While preparing the video hackfest I realized Google maps is still not the best guide for walking: “Please stay clear of pedestrian precincts“.
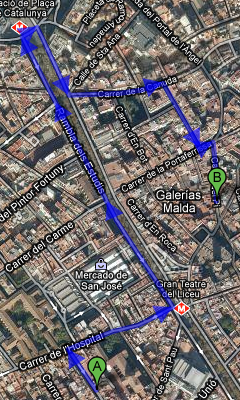
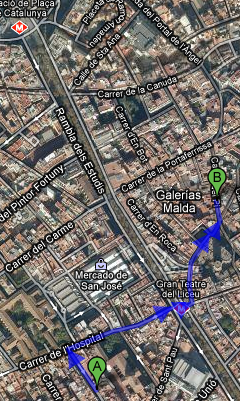
Google’s suggested way from the accomodation to the venue on the left, my suggestion on the right. I guess I’ll do it my way.
Also, for everyone living behind a rock: The video hackfest is officially announced, lots of video goodness for everyone ahead.
October 14th, 2009 — General
This is the result of applying my recent gstreamer-cairo hacking to a real-world application – Webkit. It’s very fast here and could record that video you see there while playing it without breaking a sweat. If you want to run the demo yourself, try http://people.freedesktop.org/~company/stuff/video-demo.html. (Be warned: That link downloads roughly 200MB of movie data. And it’ll likely only run in recent Epiphany or Safari releases.)
Also, thanks to the X foundation funding and Collabora hosting, we will be doing a video hackfest in Barcelona from 19th to 22nd next months. GStreamer, Cairo, X, GL and driver hackers will focus on stabilizing these features so that movies will be first class citizens in the future of your desktop, no matter what you intend to do with them, including doing video browsing lowfat style.
I’m both excited and anxious about this hackfest, I’m not used to being in charge when ots of awesome hackers meet in one place.
October 5th, 2009 — General
Here’s the pipeline:
gst-launch-0.10 filesrc location=/home/lvs/The\ Matrix\ -\ Theatrical\ Trailer.avi ! decodebin ! queue ! cairomixer sink_0::xx=0.5 sink_0::xy=0.273151 sink_0::yx=-0.273151 sink0::yy=0.5 sink_0::alpha=0.6 sink_0::xpos=72 sink_0::ypos=48 sink_2:xx=1.38582 sink_2::xy=-0.574025 sink_2::yx=0.574025 sink2::yy=1.38582 sink_2::alpha=0.7 sink_2::xpos=20 sink_2::ypos=150 sink_2::zorder=10 sink_1::xpos=300 sink_1::ypos=100 ! video/x-cairo,width=800,height=500 ! pangotimeoverlay ! cairoxsink filesrc location=/home/lvs/the_incredibles-tlr_m480.mov ! decodebin ! cairocolorspace ! video/x-cairo ! queue ! cairomixer0. filesrc location=/home/lvs/transformers.trailer.480.mov ! decodebin ! cairocolorspace ! video/x-cairo ! queue ! cairomixer0.
Here’s the result:
CPU utilization when playing this is roughly 30%, which I attribute mostly to the video decoding. The Intel 945 GPU takes 25% doing this. If I use the sync=false property, the video is done after 59s. It’s also completely backwards compatible when no hardware acceleration is available. In fact I used the same pipeline to record the video, just replacing the sink with a theoraenc.
Implementation details are here and here. Total amount of code written is roughly 10.000 lines, put into the right spots in gstreamer, cairo, pixman and the xserver. Of course, the code is not limited to GStreamer. I expect Webkit and Mozilla will use it too, once it’s properly integrated. And then we can do these effects in Javascript.
August 30th, 2009 — General
I wanted to do something “easy”. And with that I mean hack on code that doesn’t need reviews by other people or tests or API/ABI stability. But I wanted to do something useful. And I found something: I dug out Byzanz, the desktop to GIF recorder tool I wrote almost 4 years ago.
The first thing that stood out to me was the ugly functions this code uses. Functions like gdk_drawable_copy_to_image() or gnome_vfs_xfer_uri() are really not to be used if you want maintainable code. So I replaced GDK with Cairo functions and gnome-vfs with gvfs. It looks much nicer now and is more powerful, too. So if you still have code that uses outdated libraries, make the code use modern ones. It’s worth it.
This whole process comes at a bit of a cost though: Byzanz absolutely requires bugfixes that are only in the (so far) unreleased git master trees of Cairo, Gtk and GStreamer. So for now Byzanz is the most demanding application available on the GNOME desktop!
Next I realised that I learned a lot about coding in the last 4 years. My code looked really ugly back then. So I made it not use bad things like nesting main loops (do NOT ever use gtk_dialog_run()), follows conventions (like gio async functions handling) and refactored it to have a sane structure. While doing that I easily got rid of all the bugs people complained about. That was fun.
Then I made sure to document the goals that guided my design of Byzanz. From the README:
- purpose
Byzanz records animations for presentation in a web browser. If something doesn’t fit this goal, it should not be part of Byzanz.
- correctness
When Byzanz provides a feature, it does this correctly. In particular, it does not crash or corrupt data.
- simplicity
The user interface and programming code are simple and easy to understand and don’t contain any unecessary features.
Byzanz does not attempt to be smarter than you are.
- unobtrusiveness
Byzanz does not interfere with the task you are recording, neither by keeping a large settings window around nor by consuming all your CPU during a recording.
Those goals are a really useful thing, because they ensured I didn’t add features, just because I could. For example, I’d really like to add visual clues about key presses or mouse clicks. But I couldn’t find a way to make this work simple and unobtrusive. And making people fiddle with settings before a recording to enable or disable the feature is bad.
But I added a feature: Byzanz can now not only record GIF images, but also to Theora or Flash video. The web has changed in the last 5 years and supports video formats now, so it’s only following Byzanz’s design goals to add these formats. Fwiw, I only added Flash video because it’s the only lossless format. So if you wanna do post-processing in Pitivi (like add text bubbles), you wanna use the Flash format.
I also updated the UI: It asks for the filename before starting the recording, so it can save animations to your FTP while you record. And I added a bunch of niceties like remembering the last filename. Repeating a recording that doesn’t look quite right is 3 clicks: Click record button in panel, return (to select the same file), return (to confirm overwriting). Nifty that.
So, if you have a jhbuild: Get the shiny new Byzanz 0.2.0.
July 23rd, 2009 — General
I named this post “Tracker” first as I started writing from that perspective, but the problems I’m about to talk are more related to what is called “semantic desktop” and not specific to Tracker, which is just the GNOME implementation to that idea.
This post is a collection of my thoughts on this whole topic. What I originally wanted to do was improve Epiphany’s history handling. Epiphany still deletes your history after 10 days for performance reasons. When people suggesting Tracker I started investigating it, both for this purpose and in general.
How did this all start?
It gained traction when people realized that a lot of places on the desktop refer to the same things, but they all do it incompatibly. (me, me, me, me, me and I might be in your IRC, mail program and feed reader, too.) So they set out to change it. Unfortunately, such a change would have required changes to almost all applications. And that is hard. An easier approach is to just index all files and collect the information from them without touchig the applications. And thus, Tracker and Beagle were born and competed on doing just that.
However, indexing has lots of problems. Not only do you need to support all those ever-changing file formats, you also need to do the indexing. And that takes lots of CPU and IO and is duplicated work and storage. So the idea was born to instead write plugins that grab the information from the applications while they are running.
But still, people weren’t convinced, as the only things they got from this is search tools, even if they automatically update. And their data is still duplicated.
What’s a sematic desktop anyway?
Well, it’s actually quite smple. It’s just a bunch of statements in the form <subject> <predicate> <object> (called triples), like “Evolution sends emails”. Those statements come complete with a huge spec and lots of buzzwords, but it’s always just about <subject> <predicate> <object>.
Unfortunately, statements don’t help you a whole lot, there’s a huge difference between “Evolution sends emails” and “I send emails”. You need a dictionary (called ontology). The one used by Tracker is the Nepomuk ontology.
And when you have stored lots of triples stored according to your ontologies, then you can query them (using SPARQL). See Philip’s posts (1, 2) for an intro.
So why is that awesome?
If all your data is stored this way, you can easily access information from other applications without having to parse their formats. And you can easily talk to the other applications about that data. So you can have a button in evolution for IM or one in empathy to send emails. Implementing something like Wave should be kinda trivial.
And of course, you get an awesome search.
No downsides?
Of course there are downsides. For a start, one has to agree on the ontologies: How should all the data be represented? (Do we use a model like OOXML, ODF or HTML for storing documents?) Then there also is the question about security. (Should all apps be able to get all passwords”? Or should everyone be able to delete all data?) It’s definitely not easy to get right.
How does Tracker help?
Tracker tries to solve 2 problems: It tries to supply a storage and query daemon for all the data (called a triple-store) and it tries to solve the infrastructure to indexing files. The storage backend makes sense. Its architecture is sound, it’s fast and you can send useful queries its way. It has a crew of coders developing it that know their stuff. So yes, it’s the thing you want to use. Unless you don’t buy in to the semantic desktop hype.
What about the indexing?
Well, the whole idea of indexing the files on my computer is problematic. The biggest problem I have is thatthe Tracker people lack the expertise to know what data to index and how. It doesn’t help a whole lot if Tracker parses all JPEG files in the Pitures/ folder when the real data is stored in F-Spot. It doesn’t help a whole lot when you have Empathy and Evolution plugins that both have a contact named Kelly Hildebrand, but you don’t know if they’re talking about the same person. You just end up with a bunch of unrelated data.
There was something about hype?
Yeah, the semantic desktop has been an ongoing hype for a while without showing great results. Google Desktop is the best example, Beagle was supposed to be awesome but hasn’t had a release for a while, let alone Dashboard, and it hasn’t caught on in GNOME, either, even though we talk about it for more than 3 years.
But then, Nokia still builds on Tracker for Harmattan, the Zeitgeist team tries to collect data from multiple applications and make use of it in innovative ways. People are definitely still trying. But it’s not clear to me that anyone has figured out a way to make use of it yet.
Now, do I want to use it in my application or not?
Tracker is not up to the quality standards people are used from GNOME software. It’s an exciting and rapidly changing code base with lots of downright idiotic behaviors – like crashing when it accidentally takes more than 80MB memory while parsing a large file – and unsolved problems. Some parts don’t compile, the API is practically not documented and the dependancy list is not small (at least if you wanna hack on it). It also ships a tool to delete your database. Which is nice for debugging, but somewhat like shipping a tool that does rm -rf ~. In summary, I feel remembered of the GStreamer 0.7 or Gtk 1.3 days. Products with solid foundations, a potentially bright future ahead but not there yet. So it’s at best beta quality. I’d call it alpha.
There is an active development team, but that team is focused on the next Maemo release and not on desktop integration. This is quite important, because it likely means that the development focus will probably only be on new applications for the Maemo platform and not on porting old applications (in particular GNOME ones) to use Tracker. And that in turn means there will not be deeper desktop integration. Unless someone comes up and works on it.
So I don’t want to use Tracker?
The idea of the semantic desktop has great potential. if every application makes its data available for every other application in a common data store that everybody agrees on, you can get very nice integration of that data. But that requires that it’s not treated as an add-on that crawls the desktop itself, but that applications start using Tracker as their exclusive primary data store. Until EDS is just a compatibility frontend for Tracker, it’s not there yet.
So if you use Tracker, you will not have to port yor application to use it in the future, when GNOME requires it. You also get rid of the Save button in your application and gain automatic backup, crash recovery and full text search. But if you don’t use Tracker, you don’t save your data on unfinished software, and you don’t have to rip it out when Nokia (or whoever) figures out that Tracker is not the future.
Conclusion
I have no idea if Tracker or the semantic desktop is the right idea. I don’t even know if it is the right idea for a new Epiphany history backend. It’s probably roughly the same amount of work I have to do in both cases. But I’m worried about its (self)perception as an add-on instead of as an integral part of every application.
July 10th, 2009 — General
While doing my treeview related optimizations, I encountered quite a few things that help improving performance of tree views. (Performance here means both CPU usage and responsiveness of the application.) So in case you’re using tree views or entry completions and have issues with their performance, these tips might help. I often found them to be noticable for tree views with more than 100 rows, though they were usually measurable before that. With 1000 rows or more they do help a lot.
Don’t use GtkTreeModelSort
While GtkTreeModelSort is a very convenient way to implement sorting for small amounts of data, it has quite a bit of overhead, both with handling inserts and deletions. If you’re using a custom model, try implementing GtkTreeSortable yourself. When doing so, you can even use your own sort functions to make sorting really fast. If you are using GtkTreeModelFilter, you should hope this bug gets fixed.
Use custom sort functions whenever possible
As sorting a large corpus of data calls the sort function at least O(N*log(N)) times, it’s a very performance critical function. The default sort functions operate on the GValues and use gtk_tree_model_get() which copies the values for every call. For strings, it even uses g_utf_collate(). This is very bad for sort performance. So especially when sorting strings, it’s vital to have the collated strings available in your model and avoid using gtk_tree_model_get() to get good performance with thousands of rows.
Do not use gtk_tree_view_column_set_cell_data_func()
Unless you exactly know what you are doing, use gtk_tree_view_column_set_attributes(). Cell data function have to fulfill some assumptions (that probably aren’t documented) and are very performance sensitive. The implicit assumption is that they set identical properties on the cell renderer for the same iter – until the iter is changed with gtk_tree_model_row_changed(). I’ve seen quite a few places with code like this:
/* FIXME: without this the tree view looks wrong. Why? */
gtk_widget_queue_resize (tree_view);
The performance problem is that this function is called at least once for every row when figuring out the size of the model, and again whenever a row needs to be resized or rendered. So better don’t do anything that takes longer than 0.5ms. Certainly don’t load icons here or anything like this…
Don’t do fancy stuff in your tree model’s get_value function
This applies when you write your own tree model. The same restrictions as in the cell data functions apply here. Doing them wrong has the same problems as I said in the last paragraph, as this function is more low level; it gets called O(N*log(N)) times when sorting for example. Luckily there’s a simple way around it: Cache the values in your model, that’s what it’s supposed to do. And you don’t forget to call gtk_tree_model_row_changed() when a value changes.
Batch your additions
This mostly applies when writing your own tree model or when sorting. If you want to add lots of rows, it is best to first add all the rows, then make sure all the values are correct, then resort the model and only then emit thegtk_tree_model_row_added() signal for all the rows. When not writing a custom model, use gtk_list_store_insert_with_values() and gtk_tree_store_insert_with_values(). These functions do all of this already.
Fix sizes of your cell renderers if possible
This one is particularly useful when using tree views with only one column. If you have a know width and height in advance, you can use gtk_cell_renderer_set_fixed_size() to fix the size of the cell renderer in advance. This will cause the tree view to not call the get_size function for the cell renderer for every row. And this will make in particular text columns a lot quicker, because there’s no need to layout the text to compute its size anymore.
A good example for where this is really useful is GtkEntryCompletion when displaying text. As the width of the entry completion is known in advance (as big as the entry you are completing on) and the height of a cell displaying text is always the same, you can use this code on the cell renderer:
gtk_cell_renderer_set_fixed_size (text_renderer, 1, -1);
gtk_cell_renderer_text_set_fixed_height_from_font (text_renderer, 1);
Now no get_size functions will be called at all and the completion popup will still look the same.
And with these tips, there should be no reason to not stuff millions of rows into a tree view and be happy. :)