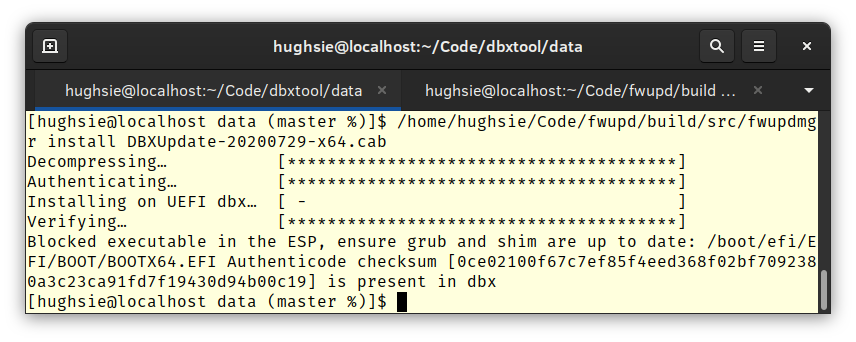
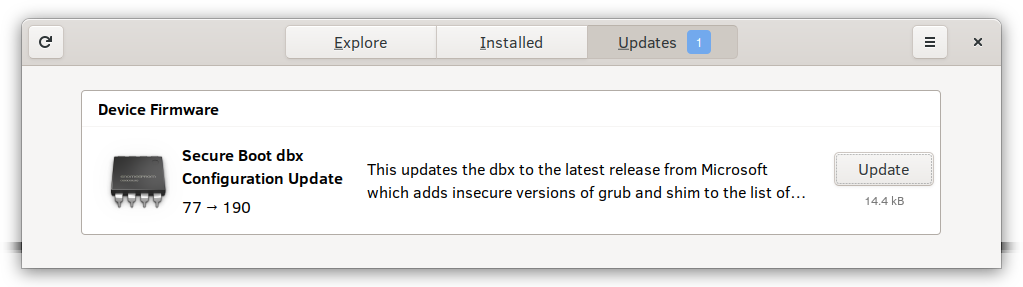
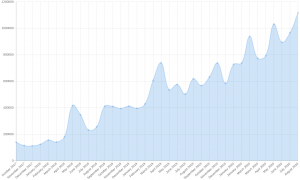
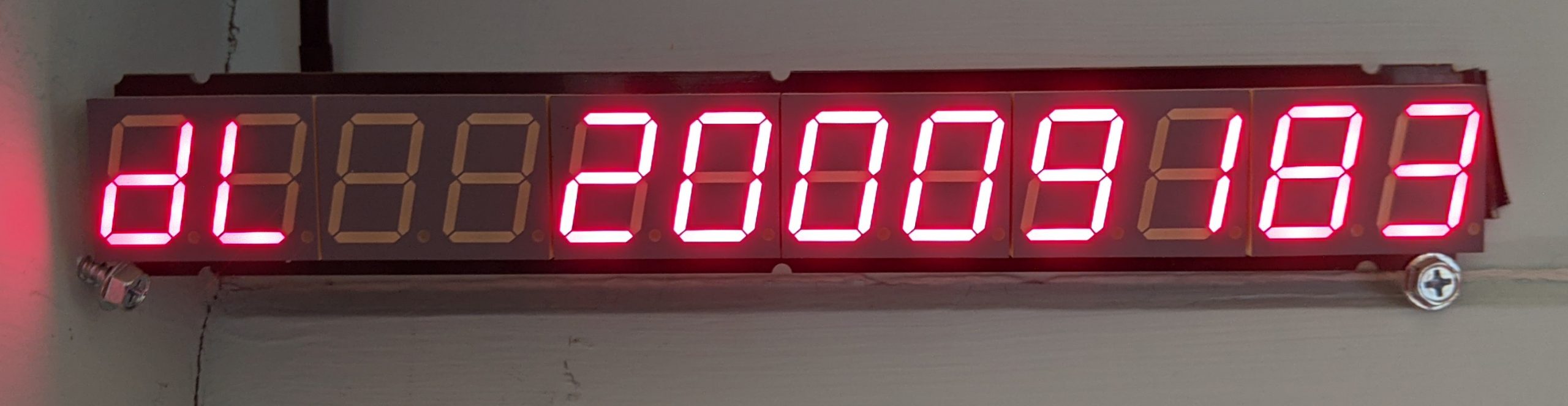A few hours ago the LVFS provided its 20 millionth firmware update and although it’s just another somewhat unusual base-10 number, it’s an achievement I’m immensely proud of. As one of my friends said last week, “20 million of anything is a big deal”. Right from the start, the fwupd daemon and LVFS website data provider was a result of collaboration between many different companies and open source projects, and is now cemented as an integral part of the firmware ecosystem. People building open source projects, especially low level infrastructure like this, are not good at celebrating success and it’s no wonder so many talented maintainers burn out over long years of dedicated service. This post celebrates some of the things we’ve done.

Little known to most people, fwupd and the LVFS grew out of the frustration of distributing the ColorHug firmware. If you bought one of those devices all those years ago, you can know you were a tiny part in starting all this. I still use ColorHug devices for all kinds of automated firmware testing, perhaps even more so than for screen calibration. My experience building OpenHardware devices really pushed me to make the LVFS free-for-all, on the logic that I wouldn’t have been able to justify even a $100/year subscription. Certainly making the service free in all respects meant that it was almost risk-free for companies to test the service.

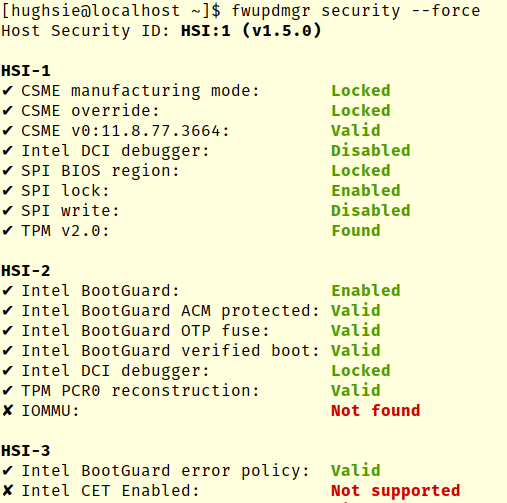
Now the LVFS analyses uploaded firmware for security problems, keeps millions of devices up to date, and also helps governments buy secure hardware using initiatives like the upcoming Host Security ID that I’ll talk more about in future blog posts. How many devices we’ve updated is impossible to know exactly as many large companies and departments mirror the entire LVFS; we just know it’s at least 20 million. In reality it’s probably a single digit multiple of that, although there’s no real way of knowing. We know 1.5 million people have sent the optional “it works for me” report we ask from CLI users, and given the CLI downloads account for ~1% of all downloads it could be a lot higher than 20 million.
A huge number of devices are supported on the LVFS now. There are currently 2393 different public firmwares uploaded by 1401 users from 106 different vendors, using 39 different protocols to update hardware. We’ve run 40,378 automated tests on those files, and extracted 1,170,543 file volume objects which can be scanned by YARA. All impressive numbers I’m sure you’ll agree.
There is one specific person I would like to thank first, my co-maintainer for both projects: Mario Limonciello who is a Senior Principal Software Development Engineer at Dell. Mario has reviewed thousands of my patches over the years, and contributed hundreds himself. I really appreciate his trust and also his confidence to tell me the half-baked and incomplete thing I’m proposing is actually insane. Together we’ve created an architecture that’s easy to maintain with a clean and modern design. Dell were also the first major laptop OEM to tell their suppliers “you need to ship firmware updates using the LVFS” and so did a lot of the initial plumbing work. We re-used most of the initial plugins when other OEMs decided they’d like to join the initiative later.
Peter Jones is another talented member of our team at Red Hat and wrote a lot of the low level UEFI code we’ve used millions of times. Peter has to understand all the crazy broken things that firmware vendors decide to do, and is responsible for most of the EFI code in fwupd. Over the years fwupd has absorbed two of his projects, fwupdate and most recently dbxtool. Without Peter there would have been no UpdateCapsule support, and that’s about half the updates on the LVFS.
Also notable to mention here is Logitech. They’ve shipped a ton of firmware (literally, millions) for their Unifying hardware and were also early adopters of the LVFS and fwupd. Nestor Lopez Casado, many thanks for all your help over the years and I’m glad MouseJack made all this a requirement :)
I’d also like to thank Lenovo; not a specific person, as Lenovo is split up into ThinkPad, ThinkStation and ThinkCenter groups and in each the engineers would probably like to remain anonymous. Lenovo as a combined group is shipping a huge amount of firmware now via the LVFS, and most of the Lenovo supply chain is already wired up to supporting the LVFS. A lot of the ODMs for Lenovo have had to actually install Fedora and learn how to program with GLib C to create a fwupd plugins to support laptop models that are not even on the shelves yet. Training up dozens of people in “how to write a fwupd plugin and deal with a grumpy maintainer” took a lot of time, but now we have companies building custom silicon submitting ready-to-roll plugins, fixes and even enhancements to the GUI tools.
The LVFS isn’t just a way for OEMs to distribute firmware, like a shared FTP site. The LVFS plumbs-itself into the ODM and ISV relationships, so we can get a pipeline right from the firmware author, all the way to the end user. As ODMs such as Wistron and Foxconn use the LVFS for one OEM, it’s very simple for them to also support other OEMs. The feedback loop from vendors to users and back to vendors again has been invaluable when debugging problems with specific firmware releases.
More recently various groups at Google have also been pushing suppliers of the Chromebook ecosystem to use fwupd and the LVFS. I’ve been told there’s now a “fwupd group” inside Google and I know that there are more than a few different models that will only be updatable using fwupd. Google are also using some of the consulting companies familiar with LVFS and fwupd so that it’s not just me explaining how this works over and over to various different small ODMs. I think in the next year this consulting side will explode and help grow the ecosystem even further.
I’d love to list all the OEMs, ODMs, ISVs and consultants that have helped over the last 5 years, but this blog entry would be even larger than it already is. Just know that I appreciate your support, help and guidance.
Talk of growing the ecosystem, the Linux Foundation are taking over the actual site maintenance; I’m not a sysadmin, and Terraform and Docker still scare me. This Christmas we’ll move the little VM I have running in Amsterdam to a proper scalable architecture with 24/7 support. This will let us provide some kind of uptime guarantee and also means I don’t have to worry about applying a security update when I’m on holiday without internet access. The Linux Foundation have been paying the entire CDN cost for the last few years, and for that my wallet is truly grateful.
Finally, I must also thank Red Hat for letting me work on this stuff. Over the last few years fwupd has gone from my “20%” hobby to almost taking over all my developer time. Red Hat doesn’t get enough credit for all the essential plumbing they tirelessly do, and without them paying my salary every month there is no way this kind of free-to-upload and free-to-download service could exist. I firmly believe that fwupd is mutually beneficial to all the Red Hat partners like Intel, Dell and Lenovo – both so that more hardware gets purchased from OEMs, and also so that customers running Fedora and RHEL have up to date firmware.

At a conference last year, I presented a talk where the penultimate slide was “the LVFS is just a website that runs cron jobs” and I had someone I respect come up to me afterwards and tell me something in a stern voice I’ll remember forever: “You didn’t just create a website – you changed an industry!”
Lets look forward to the next 20 million updates.