Flatpak relies on OSTree to distribute apps. This means that flatpak repositories, such as Flathub, are really just OSTree repositories. At the core of an OSTree repository is the summary file, which describes the content of the repository. This is similar to the metadata that “apt-get update” downloads.
Every time you do an flatpak install it needs the information in the summary file. The file is cached between operations, but any time the repository changes the local copy needs to be updated.
This can be pretty slow, with Flathub having around 1000 applications (times 4 architectures). In addition, the more applications there are, the more likely it is that one has been updated since the last time which means you need to update.
This isn’t yet a major problem for Flathub, but its just a matter of time before it is, as apps keep getting added:
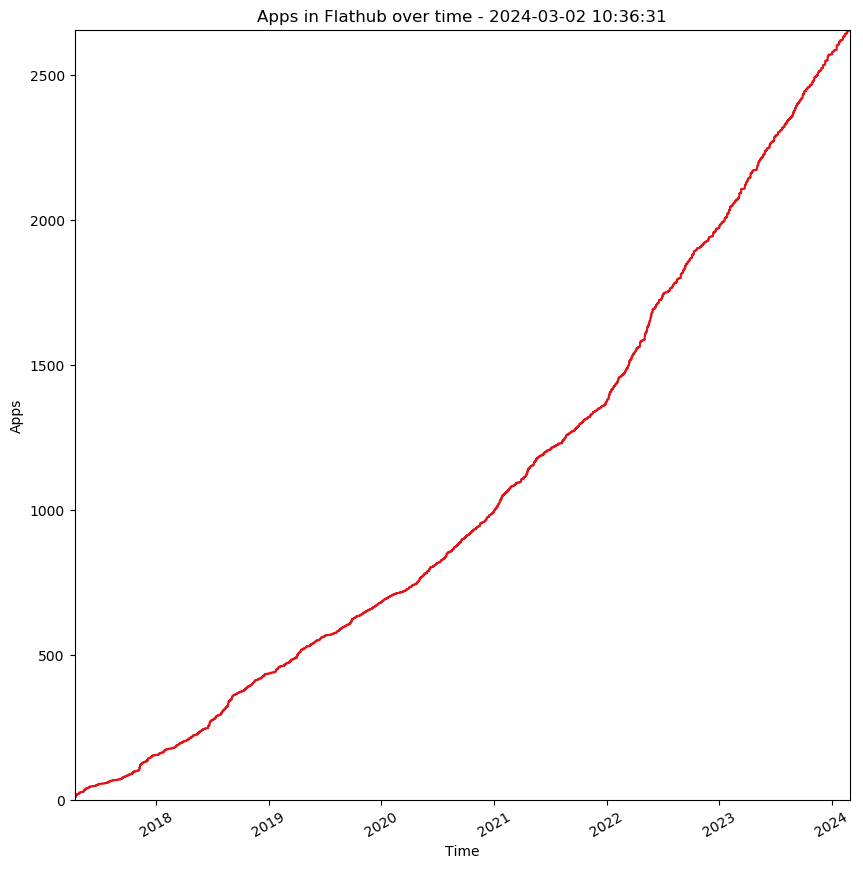
This is particularly problematic if we want to add new architectures, as that multiplies the number of applications.
So, the last month I’ve been working in OSTree and Flatpak to solve this by changing the flatpak repository format. Today I released Flatpak 1.9.2 which is the first version to support the new format, and Flathub is already serving it (and the old format for older clients).
The new format is not only more efficient, it is also split by architecture meaning each user only downloads a subset of the total summary. Additionally there is a delta-based incremental update method for updating from a previous version.
Here are some data for the latest Flathub summary:
- Original summary: 6,6M (1.8M compressed)
- New (x86-64) summary: 2.7M (554k compressed)
- Delta from previous summary: 20k
So, if you’re able to use the delta, then it needs 100 times less network bandwidth compared to the original (compressed) summary and will be much faster.
Also, this means we can finally start looking at supporting other architectures in Flathub, as doing so will not inconvenience users of the major architectures.
To the future and beyond!
I guess going forwards this will allow doing private flathub mirror with all applications for selected architectures.
One of the big long term problems to long term scaling is lack of formal mirror support.
.flatpakref only has spaces for single URLs from what what I can tell. This means if primary site is down the .flatpakref is useless to install the application.
Same with declaring repo in flatpak you cannot define a primary URL and Secondary URL for a repository this would have usage for internal business flatpak usage so internal repo is safe from single server failure or could have a usage with a business with multi offices to use the closest server.
Personally think working out how to support mirrors next major step of scale up.
You could always mirror whatever subset you want, this is primarily about how efficient accessing it is.
Anyway, the ostree repo format is quite complicated with the file interdependences it has, so I kind of doubt a traditional mirroring system could work. You’ll always get some files out-of-sync resulting in some refs being broken.
However, its not like we’re living in the stone-age. The flathub main repo is served via two (disk-)cache:ing frontends which in turn are fronted by a world-wide cacheing CDN (fastly), so its not like there is a single point of failure.
–Anyway, the ostree repo format is quite complicated with the file interdependences it has, so I kind of doubt a traditional mirroring system could work. You’ll always get some files out-of-sync resulting in some refs being broken.–
This is true that you cannot use a pure traditional mirror system.
https://ostreedev.github.io/ostree/repository-management/#mirroring-repositories
Ostree has it own mirroring solutions. This does bring ostree atomic nature to the process and some limitations.
Thing to be aware of is ostree mirror methods results in mirror as it mirroring from upstream going needing to go off-line to its downstream clients. This is why you would like as a business want a primary and secondary mirror for your internal mirror. So the primary mirror can go off line while it syncs with flathub or equal with the client using secondary mirror and once primary is updated the secondary mirror can go offline and sync up possible from the primary.
See the fun problem think you are operating inside a business network without a CDN. You want client machines to update to the most current in your mirror as soon as possible. The single URI for repository address makes this harder.
This is the thing if flatpakref for repositories could support more than 1 URI and auto step though those URI if one happens to be offline that allows you to use the ostree mirror solutions that cut off clients because client can be use a different server/URI while one is updating.
Its really adds a fun problem that Ostree has limitations on how its can mirror. With the big one while mirroring no clients can be using it. Allowing client program to have more than 1 URI for repository allows the client to auto change if one of those URI is down and allows the servers hosting the repos to go off line for maintenance or to mirror upstream.
The fun problem with all this is dealing with the case that client has sync from newer repository and now has found a older repository and it must not screw self over. If ostree is designed right it should not be idiot in this case.