Compatibility has always been a complex problems in the Linux world. With the advent of containers/sandboxing it has become even more complicated. Containers help solve compatibility problems, but there are still remaining issues. Especially on the Linux desktop where things are highly interconnected. In fact, containers even create some problems that we didn’t use to have.
Today I’ll take a look at the issues in more details and give some ideas on how to best think of compatibility in this post-container world, focusing on desktop use with technologies like flatpak and snap.
Forward and backwards compatibility
First, lets take a look at what we mean by compatibility. Generally we’re considering changing some part of the system that interacts with other parts (for example command-line arguments, a library, a service or even a file format). We say the change is compatible if the complete system still works as intended after the change.
Most of the time when compatibility is mentioned it refers to backwards compatibility. This means that a change is done such that all old code keeps working. However, after the update other things may start to rely on the new version and there is no guarantee that these new versions will work without the change. A simple example of a backwards compatible change is a file format change, where the new app can read the old files, but the old app may not necessarily read the new files.
However, there is also a another concept called forward compatibility. This is a property of the design rather than any particular change. If something is designed to be forward compatible that means any later change to it will not cause earlier versions to stop working. For example, a file format is designed to be forward compatible if it guarantees a file produced by a new app is still readable by an older app (possibly somewhat degraded due to the lack of new features).
The two concepts are complementary in the sense that if something is forward compatible you can “upgrade” to older versions and that change will be backwards compatible.
API compatibility
API stands for Application Programming Interface and it defines how a program interfaces with some other code. When we talk about API compatibility we mean at the programming level. In other words, a change is API compatible if the some other source code can be recompiled against your changed code and it still builds and works.
Since the source code is very abstract and flexible this means quite a lot of changes are API compatible. For example, the memory layout of a structure is not defined at the source code level, so that can change and still be API compatible.
API compatibility is mostly interesting to programmers, or people building programs from source. What affects regular users instead is ABI compatibility.
ABI compatibility
ABI means Application Binary Interface, and it describes how binaries compiled from source are compatible. Once the source code is compiled a lot more details are made explicit, such as the layout of memory. This means that a lot of changes that are API compatible are not ABI compatible.
For example, changing the layout of a (public) structure is API compatible, but not ABI compatible as the old layout is encoded in the compiled code. However, with sufficient care by the programmer there are still a lot of changes that can be made that are ABI backward compatible. The most common example is adding new functions.
Symbol versioning
One thing that often gets mentioned when talking about ABI compatibility is symbol versioning. This is a feature of the ELF executable format that allows the creation of multiple versions of a function in the binary with the same name. Code built against older versions of the library calls the old function, and code built against the new version will call the new function. This is a way to extend what is possible to change and still be backwards ABI compatible.
For example, using this it may be possible to change the layout of a structure, but keep a copy of the previous structure too. Then you have two functions that each work on its own particular layout, meaning the change is still ABI compatible.
Symbol versioning is powerful, but it is not a solution for all problems. It is mostly useful for small changes. For example, the above change is workable if only one function uses the structure. However, if the modified structure is passed to many functions then all those functions need to be duplicated, and that quickly becomes unmanageable.
Additionally, symbol versioning silently introduces problems with forward compatibility. Even if an application doesn’t rely on the feature that was introduced in the new version of the library a simple rebuild will pick up a dependency of the new version, making it unnecessarily incompatible with older versions. This is why Linux applications must be built against the oldest version of glibc they want to support running against rather than against the latest.
ABI domains
When discussing ABI compatibility there is normally an implicit context that is assumed to be fixed. For example, we naturally assume both builds are for the same CPU architecture.
For any particular system there are a lot of details that affect
this context, such as:
- Supported CPU features
- Kernel system call ABI
- Function calling conventions
- Compiler/Linker version
- System compiler flags
- ABI of all dependent modules (such as e.g. glibc or libjpeg versions)
I call any fixed combination of these an ABI domain.
Historically the ABI domain has not been very important in the context of a particular installation, as it is the responsibility of the distribution to ensure that all these properties stay compatible over time. However, the fact that ABI domains differ is one of the primary causes of incompatibility between different distributions (or between different versions of the same distribution).
Protocol compatibility
Another type of compatibility is that of communication protocols. Two programs that talk to each other using a networking API (which could be on two different machines, or locally on the same machine) need to use a protocol to understand each other. Changes to this protocol need to be carefully considered to ensure they are compatible.
In the remote case this is pretty obvious, as it is very hard to control what software two different machines use. However, even for local communication between processes care has to be taken. For example, a local service could be using a protocol that has several implementations and they all need to stay compatible.
Sometimes local services are split into a service and a library and the compatibility guarantees are defined by the library rather than the service. Then we can achieve some level of compatibility by ensuring the library and the service are updated in lock-step. For example a distribution could ship them in the same package.
Enter containers
Containers is (among other things) a way to allow having multiple ABI domains on the same machine. This allows running a single build of an application on any distribution. This solves a lot of ABI compatibility issues in one fell swoop.
And there was much rejoicing!
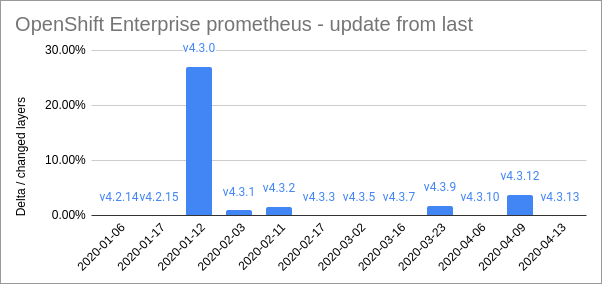
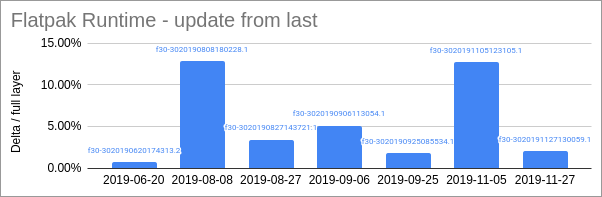
There are still some remnants of ABI compatibility issues left, for example CPU features and kernel system calls still need to be compatible. Additionally it is important to keep the individual ABI domains internally compatible over time. For flatpak this ends up being the responsibility of the maintainers of the runtime wheras for docker it is up to each container image. But, by and large, we can consider ABI compatibility “solved”.
However, the fact that we now run multiple ABI domains on one machine brings up some new issues that we really didn’t need to care much about before, namely protocol compatibility and forward compatibility.
Protocol compatibility in a container world
Server containers are very isolated from each other, relying mainly on the stability of things like DNS/HTTP/SQL. But the desktop world is a lot more interconnected. For example, it relies on X11/Wayland/OpenGL for graphics, PulseAudio for audio, and Cups for printing, etc. Lots of desktop services use DBus to expose commonly used desktop functionality (including portals), and there is a plethora of file formats shared between apps (such as icons, mime-types, themes, etc).
If there is only one ABI domain on the machine then all these local protocols and formats need not consider protocol compatibility at all, because services and clients can be upgraded in lock-step. For example, the evolution-data-server service has an internal versioned DBus API, but client apps just use the library. If the service protocol changes we just update the library and apps continue to work.
However, with multiple ABI domains, we may have different versions of the library, and if the library of one domain doesn’t match the version of the running service then it will break.
So, in a containerized world, any local service running on the desktop needs to consider protocol stability and extensibility much more careful than what we used to do. Fortunately protocols are generally much more limited and flexible than library ABIs, so it’s much easier to make compatible changes, and failures are generally error messages rather than crashes.
Forward compatibility in a container world
Historically forward compatibility has mainly needed to be considered for file formats. For instance, you might share a home directory between different machines and then use and different versions of an app to open a file on the two machines, and you don’t want the newer version to write files the older can’t read.
However, with multiple ABI domains it is going to be much more common that some of the software on the machine update versions faster than others. For example, you might be running a very up-to-date app on an older distribution. In this case it is important that any host services were designed to be forward compatible so that they doesn’t break when talking to the newer clients.
Summary
So, in this new world we need to have new rules. And the rule is this:
Any interface that spans ABI domains (for example between system and app, or between two different apps) should be backwards compatible and try to be forward compatible as much as possible.
Any consumer of such an interface should be aware of the risks involved with version differences and degrade gracefully in case of a mismatch.