everything in this post is just talking about ideal concepts of user interaction. technical aspects are not discussed here since they’re actually very easy.
very fortunately, gnome has adopted an auto-apply interaction for all of its preferences dialogs. the familiar dialog style that everyone knows and loves:
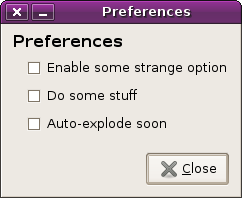
(standard instant-apply preferences dialog)
one of the nicest things about this dialog type is that showing and hiding the dialog has no side-effects. they’re sort of like spatial nautilus windows in a way — something that is conceptually always there, but usually not shown.
unfortunately, instant-apply isn’t for everyone and everything. for example, when settings in gdm change it may result in x servers being started or stopped — you really don’t want this type of thing going on as you click around with checkboxes. for some things we need to have a delayed apply.
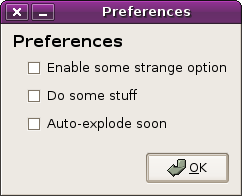
(delayed-apply preferences dialog)
with this sort of dialog, your changes are made all at once when you close the dialog (via the “ok” button).
of course, if we haven’t actually made the changes yet, there must be the ability to revert them. this ability to revert isn’t present in instant-apply (as we know it) but users want it for delayed-apply. the way of doing this for ages, of course, has been the “cancel” button.
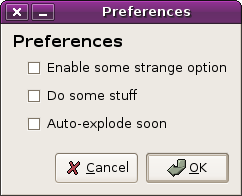
(delayed-apply preferences dialog with cancel button)
and some people seem to think that maybe you want to apply the settings without closing the dialog box. that’s easy enough to do, right?
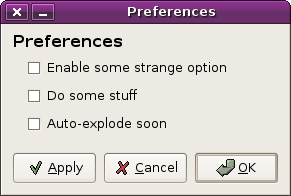
(delayed-apply preferences dialog with cancel and apply)
so now our three buttons do:
- apply changes
- undo changes, close the dialog
- apply changes, close the dialog
but what if we wanted to undo the changes without closing the dialog? sometimes you see this.
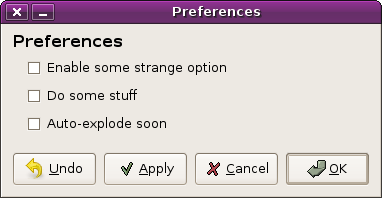
(delayed-apply preferences dialog with cancel, apply, undo)
wow. that’s a lot of buttons. but now our user can do both applies and undos without closing the dialog. nice.
- apply changes
- undo changes, close the dialog
- apply changes, close the dialog
- undo changes
there’s always this sort of implicit assumption, though, that closing the dialog will either apply or destroy your in-progress settings. your “working set” of changes are, for technical reasons, tied to the dialog box. what if the dialog crashed or your computer lost power and you were in the middle of making a rather large set of changes? could we have crash recovery that brought you back to the changes that you were in the middle of when the dialog next opened again?
and if we have crash recovery able to remember the changes that you were working on, why not have this as a normal feature of the dialog? in essence, why not add an option for “close the dialog” that neither applies or undoes your changes?
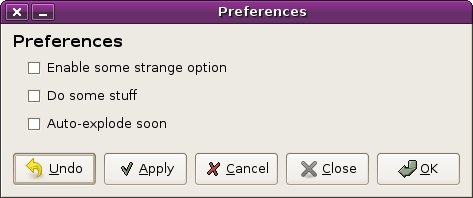
(delayed-apply preferences dialog with pain)
ouch.
but now we have actually gotten somewhere. we support everything that the user could possibly want to do:
- apply changes
- undo changes, close the dialog
- apply changes, close the dialog
- undo changes
- close the dialog (and don’t mess with my working set)
the dialog is absolutely painful, though, in terms of the number of buttons it has. it’s a little bit redundant, too; two of the buttons (“ok” and “cancel”) are now combined actions that can be performed with the other buttons.
what about this?
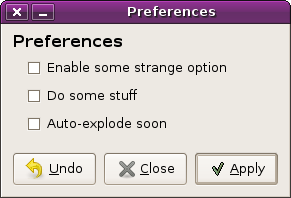
(dialog with apply, close, undo)
here is a neat idea for a delayed-apply dialog. if you make some changes and “close” it, you can come back to your working set of changes later. you can “undo” your working set to be the same as the live (applied) version, and you can “apply” it.
with this sort of model it even makes sense to do things like open a preferences dialog, click “apply”, then click “close” without doing anything else.
the downside is that “ok” and “cancel” are gone. people are familiar with these buttons and they probably like them. they might be annoyed by the fact that they have to press “apply” and then “close” instead of just “ok”.
people might also be confused by the fact that their working set of preferences stick around after closing a dialog and bringing it back.
with the instant-apply preference dialog we have right now in gnome, life is great. your mental model is that a preference dialog box is a thing that can be shown or hidden without these actions having any implicit side effects.
this is something that i want for delayed-apply dialogs too.
is it worth it or is it just too confusing?