In a world where so many open source projects never get to version 1.0, I’ve just announced colord 1.0.0. See the archives for the release announcement and the FAQ for details about the new numbering scheme.
Year: 2013
Auto-EDID Results [updated]
A couple of weeks ago I asked people to run a command which uploaded all their auto-EDID display profiles to me. This was a massive success with 1858 profiles being added to a large dataset. These were scanned by the cd-find-broken tool, and results plotted on my G+ page. As there’s been so much new data I’m updating the graphs:
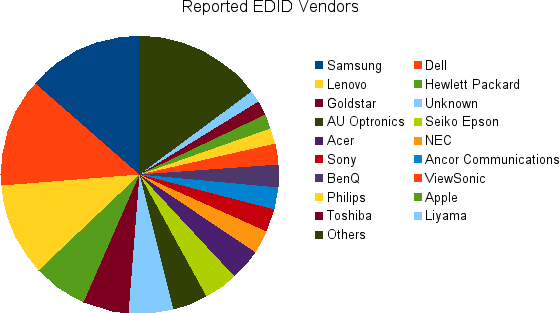
I’m actually using this data to make sure we show something sane in the client UIs. Some interesting vendors are not included, e.g.:
- “System manufacturer”,3
- “To Be Filled By O.E.M.”,4
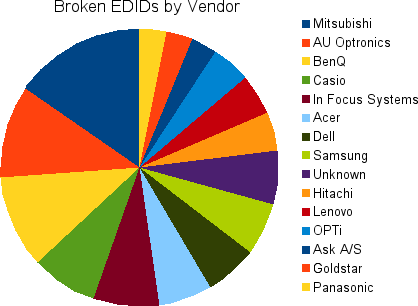
This is a chart of vendors Doing It Wrong™ by including random data (or implausible data) as the display primaries.
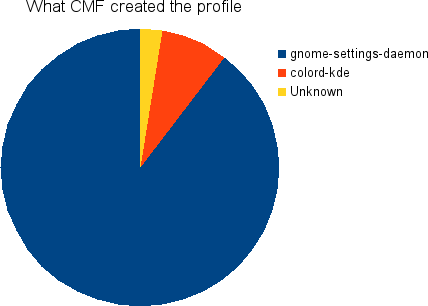
This shows what program created the Auto-EDID ICC profile. Unknown is probably a mixture of oyranos and also early versions of gnome-setting-daemon which didn’t set the extra metadata.
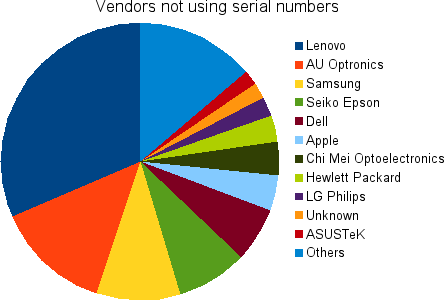
Last graph I promise. This shows a chart of all the vendors who do not populate the serial number in the EDID blob. I’ll explain why this is bad.
When we construct the device ID for colord, we use the vendor{-model}{-serial} as part of the key. This allows you to use different ICC profiles even if you’ve got two “identical” external panels attached. Without the serial number, “lenovo-foo” looks the same as “lenovo-foo” and colord treats them as if they were the same panel. This sucks if the panels were not bought at the same time and have identical backlight burn time. Ohh, and we can’t use the connection name (e.g. DVI-1) as it would suck if you had to reassign all your profiles if you moved the connector to DVI-2…
This isn’t always a disaster: Laptops. We only need the make and model to ensure this is unique on the system as you can’t typically have two internal panels installed. This explains the Lenovo, Samsung, Dell and Apple entries I think, so don’t get out the pitchforks just yet. Unfortunately there’s nothing in the ICC profile that says “this is a laptop” so we can’t be more selective and hence this graph isn’t super useful. But, even on laptops, vendors should really be doing something semi-sane with the serial number, even if it’s just the batch number.
A new 0.1.34 colord was released this week. Thanks again to everyone that uploaded profiles.
Auto-EDID Profiles Results
First, thanks for everyone that contributed ICC profiles. I’ve received over 800 uploads in a little under 24 hours, so I’m very grateful.
TLDR:
Total profiles scanned: 800 Profiles with invalid or unlikely primaries: 45 EDIDs are valid 94.4% of the time
This resulted in the following commit to colord:
commit 87be4ed4411ca90b00509a42e64db3aa7d6dba5c Author: Richard Hughes <richard@hughsie.com> Date: Wed Apr 24 21:47:14 2013 +0100 Do not automatically add EDID profiles with warnings to devices
I’ll explain a little about what these numbers and the commit means. The EDID reports three primaries, i.e. what real world XYZ color red, green and blue map to. It also tells us the whitepoint of the display. From basic color science we know that
- If R=G=B, we should be displaying a black/gray/white color without significant amounts of red green and blue showing
- The reported gamut of colors should not be bigger on real hardware than theoretical archive spaces like ProPhotoRGB.
- If R=G=B=100%, then we should have a good approximation of D50 white
- The temperature of the display should not be too cold (>3000K) or too warm (<10000K).
There are actually 11 checks colord now does on RGB profiles, similar to the checks done above. If any of the 11 checks fail, the automatically generated profile is not used. The user can still add it manually if they want and then of course it will be used for the monitor, but we don’t break things by default for 5.6% of users.
If anyone is interested, the results were generated by this program, and the raw results are available here. My personal take-home messages you can take from this file are:
- Sometimes blue and green are the wrong way around (Samsung SyncMaster)
- Vendors need to use something other than random binary data (AU Optronics)
- If you don’t know what a whitepoint is, don’t try and guess (Sharp and Lenovo YT07)
- Projectors generally don’t really know/care what values to use (OPTi PK301 and In Focus Systems)
There’ll be a new colord release with this feature released in the next couple of weeks.
Auto-EDID ICC Profiles
A favour, my geeky friends:
gnome-settings-daemon and colord-kde create an ICC profile based on the color information found in the EDID blob. Sometimes the EDID data returns junk, and so the profile is also junk. This can do weird things to color managed applications. I’m trying to find a heuristic for when to automatically suppress the profile creation for bad EDIDs, such as the red primary being where blue belongs and that kind of thing. To do this, I need data. If you could run this command, I’d be very grateful.
for f in $HOME/.local/share/icc/edid-* ; do curl -i -F upload=@$f http://www.hughski.com/profile-store.php done
This uploads the auto-EDID profile to my webserver. There is no way I can trace this data back to any particular user, and no identifiable data is stored in the profile other than the MD5 of the EDID blob. I’ll be sharing the processed data when I’ve got enough uploads. If you think that your EDID profile is wrong then I’d really appreciate you also emailing me with the “Location:” output from CURL, although this is completely optional. Thanks!
Translated Color Profiles
In GNOME 3.10 we’ll have translated ICC profiles thanks to all the translators. This should make Alexandre Prokoudine happy indeed.
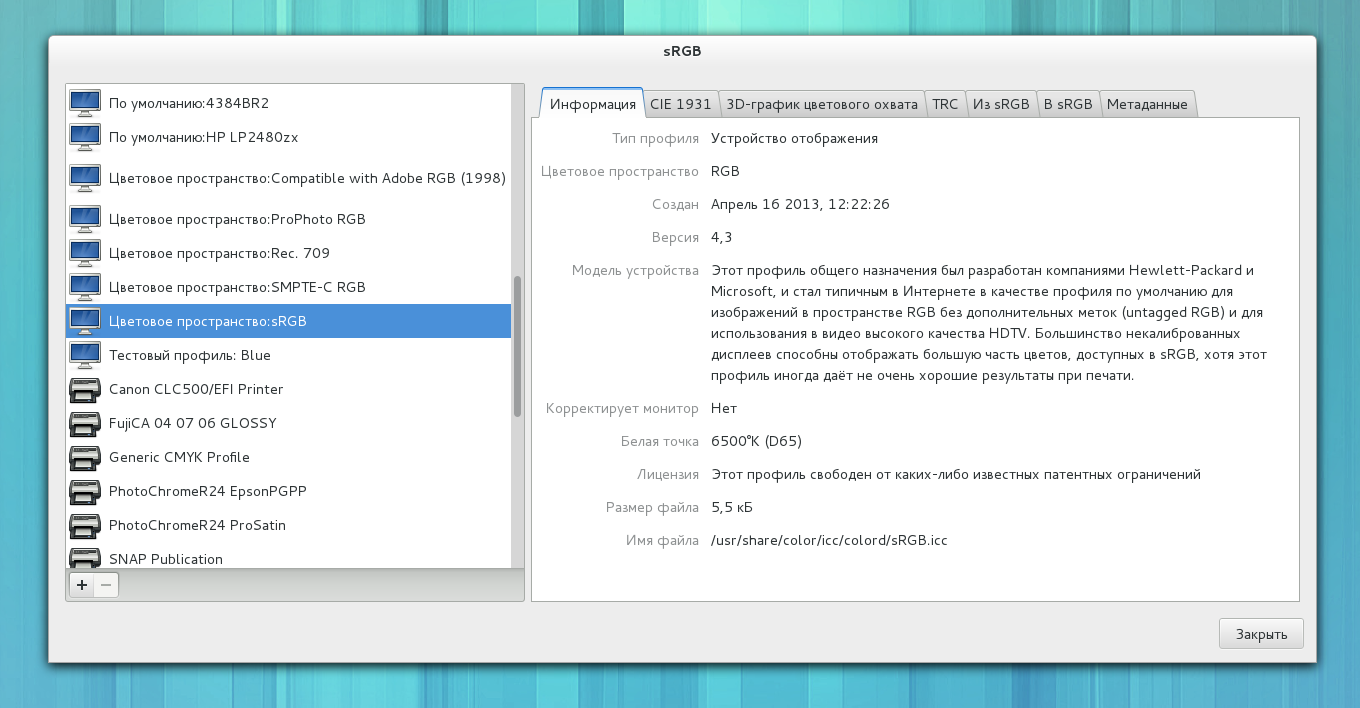
For applications, libcolord provides a CdIcc GObject if you don’t feel like dealing with wchar_t‘s and ‘mluc‘ objects yourself. Applications that deal with ICC profiles and want to get the localized versions of the description should probably look at this example code in C or in Python.
Comments, as always, welcome.
GNOME Software overall plan
I’ve been asked by a few people now to outline my plans for improving software installation in GNOME. I’ve started to prototype a new app called ‘GNOME Software’. It exists in gnome git and currently uses PackageKit to manage packages. It’s alpha quality, but basically matches the mockups done by the awesome guys in #gnome-design. It’s designed to be an application management application. GNOME PackageKit lives on for people that know what a package is and want a pointy-clicky GUI, so I’m not interested in showing low level details for power users.
Of course, packages are so 2012. It’s 2013, and people want to play with redistributable things like listaller and glick2 static blobs. People want to play with updating an OS image like ostree and that’s all awesome. Packages are pretty useful in some situations, but we don’t want to limit ourselves to being just another package installer. From a end-user point of view, packages are just an implementation detail.
So, I’ve been designing gnome-software to be pluggable. This means you can write an AppStream plugin to provide things like icons and screenshots for not-yet-installed software. You can write a plugin to ask ostree to update itself, and also a plugin to ask PackageKit to update a specific package. The idea is that we just run all the plugins in parallel when the user opens the dialog, and hide all the gutty details about the application update/install/removal itself. If installing packages falls out of favour we drop the PackageKit plugin, and instead write a plugin for ${distribution_system_of_the_year}.
I’ve done a quick technical outline below:
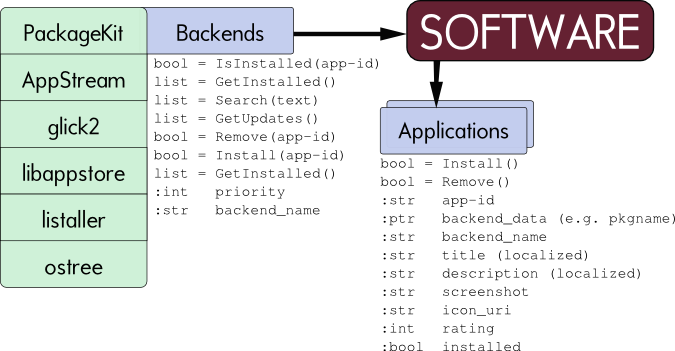
There are a few sticky issues I’ve not yet solved, like what happens if inksape is installed locally using Glick2 and also installed as a package. I suppose you’d get two entries in the results, and two things to update. Not sure. Ideas welcome.
There’s quite a bit of working code in git, but I didn’t want to write too much until I’d had some feedback from the community. Comments, suggestions and flames very welcome. Thanks.
ColorMunki Smile
I’ve just purchased a ColorMunki Smile so I can write a native colord driver for the i1 display class of hardware. I’ll base this on the Argyll CMS driver which is also GPLv2+ and this will mean we can get faster and more reliable readings by not spawning /usr/bin/spotread and trying to screen scrape the output. It also means we can support the newer LED backlights in the client UIs, which the smile supports.
GSL-like math library?
Does anybody know of a GSL-like math library that can do Akima and cubic spline interpolation? It needs to be LGPLv2+ or some variant of BSD. GSL is GPLv3 which is incompatible with the the LGPLv2+ used in libcolord. GPL for a library is such a bad idea it’s not even funny.
GResource and colord startup
A couple of days ago I released colord 0.1.30. This was an otherwise unremarkable release with the normal splattering of a few bugfixes and the occasional small new features.
One such feature is the use of GResource. The new GResource stuff that landed in Glib 2.32 allows you to embed abritary binary data into the actual executable file. This is typically used for embedding small files that are normally loaded at runtime, for instance D-Bus introspection files or small application icons. Embedding that data also lets us strip the blanks from any XML file, and optionally compress the data too. It means we’re not seeking and loading many small files when the binary is run, which reduces by a small amount the amount of I/O that is done, and hence speeds up startup.
So I got thinking. Looking at the cold startup[1] I/O profile of colord, the first thing it does is scan for any files in /usr/share/color/icc for *.icc files. On the default system in Fedora, we only have a few files installed in that directory, and all of them are generated by colord at package build time and shipped in the colord package. We know where they are going to be, and what the contents are. Typically there are ~10 profiles installed, and they are all less than 1kb in size.
Since 0.1.30, at build time the profiles generated by colord (and only those) get included into the binary as resources. This means the colord binary size grows by slightly less than 10k, but means we don’t load 10 small files from the disk at startup. The files are still installed like normal so that applications can reference them as files like before, but if there is an internal mmap’ed copy of the same profile we use that instead. This reduces the amount of I/O that colord does at startup by about half. It speeds the daemon startup by about 35ms on SSD hardware (as seeks are cheap) but on spinning rust drives or LiveCD media it makes an order of magnitude more difference.
[1] cold, as in not in hot-cache. Do ‘echo 3 > /proc/sys/vm/drop_caches’ if you want to see the difference.
Color Calibration Survey Results
A couple of weeks ago I asked people on my blog and a few chosen mailing lists to answer three simple questions:
- What monitor calibration devices do you own?
- Which of these devices have you used in the last 6 months?
- If you were to buy a new calibration device, which would you buy?
I wanted to work out what hardware I should buy for testing with gnome-color-manager and colord for each release. The results are very skewed toward Linux users, but that was kind of the point of the survey.
So, the first set of data, which 203 people answered:

Notable points:
- Nobody owns a Colorimetre HCFR. Not much of a suprise really.
- Spyder4 is new hardware which performs well, but hardly anyone owns one yet.
- 43% of people answering the survey own a ColorHug, which isn’t too much of a suprise since it was posted on the ColorHug Google+ page. Still, pretty awesome for such a new project.
The next graph is very similar to the first, with 191 people responding:

Notable points:
- There are a lot of Spyder2’s sitting in drawers unused.
- Lots of people bought a ColorHug, and don’t use it very often. This isn’t suprising as it’s the least expensive device by a long way.
- i1Pro owners use the device a lot more than people that own other devices. This is also a very expensive device, so again, kinda makes sense.
The last graph is interesting in a number of ways, from 173 users:

- 52% of Linux users would buy a ColorHug. This is the most popular cheap colorimeter option.
- 31% of people would buy a much more expensive photospectrometer rather than a colorimeter.
- 11% of people want to buy hardware considered obsolete by the manufacturer.
- 2 people want to buy a Colorimetre HCFR. Good luck there :)
- 6 people wanted to buy a ColorHug Spectro, even though it wasn’t an option on the survey and doesn’t even exist yet.
Based on the results of this data, I think it’s important for me to buy some Spyder hardware and concentrate on the photospectrometer-type hardware. Thanks to all respondents, your help has been really valuable.