For the early adopters of the original ColorHug I’ve been offering a service where I send all the newer parts out to people so they can retrofit their device to the latest design. This included an updated LiveCD, the large velcro elasticated strap and the custom cut foam pad that replaced the old foam feet. In the last two years I’ve sent out over 300 free upgrades, but this has reduced to a dribble recently as later ColorHug1’s and all ColorHug2 had all the improvements and extra bits included by default. I’m going to stop this offer soon as I need to make things simpler so I can introduce a new thing (+? :) next year. If you do need a HugStrap and gasket still, please fill in the form before the 4th January. Thanks, and Merry Christmas to all.
Logitech Unifying Hardware Required
Does anyone have a spare Logitech Unifying dongle I can borrow? I specifically need the newer Texas Instruments version, rather than the older Nordic version.

You can tell if it’s the version I need by looking at the etching on the metal USB plug, if it says U0008 above the CE marking then it’s the one I’m looking for. I’m based in London, UK if that matters. Thanks!
Linux communities, we need your help!
There are a lot of Linux communities all over the globe filled with really nice people who just want to help others. Typically these people either can’t (or don’t feel comfortable) coding, and I’d love to harness some of that potential by adding a huge number of new application reviews to the ODRS. At the moment we have about 1100 reviews, mostly covering the more popular applications, and also mostly written in English.
What I would love is for a few groups of people to come together for their next LUG/outreach/InstallFest and sit down together somewhere cozy and write a few reviews. Bonus points if you use a less-well-known application, and even more points if you can write in a language other than English. Submitting a review is easy; just open up GNOME Software, find the application, and click ‘Write a Review‘ at the bottom of the page.
Application reviews help new users what to install, and the star ratings you give means we can return useful search results full of great applications. Please write an email, ask about helping the ODRS, and perhaps you can help a lot of new users next time you meet with your Linuxy friends.
Thanks!
Last batch of ColorHugALS
I’ve got 9 more ColorHugALS devices in stock and then when they are sold they will be no more for sale. With all the supplier costs going recently up my “sell at cost price” has turned into “make a small loss on each one” which isn’t sustainable. It’s all OpenHardware, both hardware design and the firmware itself so if someone wanted to start building them for sale they would be doing it with my blessing. Of course, I’m happy to continue supporting the existing sold devices into the distant future.

In part the original goal is fixed, the kernel and userspace support for the new SensorHID protocol works great and ambient light functionality works out of the box for more people on more hardware. I’m slightly disappointed more people didn’t get involved in making the ambient lighting algorithms more smart, but I guess it’s quite a niche area of development.
Plus, in the Apple product development sense, killing off one device lets me start selling something else OpenHardware in the future. :)
Searching in GNOME Software
I’ve spent a few days profiling GNOME Software on ARM, mostly for curiosity but also to help our friends at Endless. I’ve merged a few patches that make the existing --profile code more useful to profile start up speed. Already there have been some big gains, over 200ms of startup time and 12Mb of RSS, but there’s plenty more that we want to fix to make GNOME Software run really nicely on resource constrained devices.
One of the biggest delays is constructing the search token cache at startup. This is where we look at all the fields of the .desktop files, the AppData files and the AppStream files and split them in a UTF8-sane way into search tokens, adding them into a big hash table after stemming them. We do it with 4 threads by default as it’s trivially parallelizable. With the search cache, when we search we just ask all the applications in the store “do you have this search term” and if so it gets added to the search results and ordered according to how good the match is. This takes 225ms on my super-fast Intel laptop (and much longer on ARM), and this happens automatically the very first time you search for anything in GNOME Software.
At the moment we add (for each locale, including fallbacks) the package name, the app ID, the app name, app single line description, the app keywords and the application long description. The latter is the multi-paragraph long description that’s typically prose. We use 90% of the time spent loading the token cache just splitting and adding the words in the description. As the description is prose, we have to ignore quite a few words e.g. “and”, “the”, “is” and “can” are some of the most frequent, useless words. Just the nature of the text itself (long non-technical prose) it doesn’t actually add many useful keywords to the search cache, and the ones that is does add are treated with such low priority other more important matches are ordered before them.
My proposal: continue to consume everything else for the search cache, and drop using the description. This means we start way quicker, use less memory, but it does require upstream actually adds some [localized] Keywords=foo;bar;baz in either the desktop file or <keywords> in the AppData file. At the moment most do, especially after I sent ~160 emails to the maintainers that didn’t have any defined keywords in the Fedora 25 Alpha, so I think it’s fairly safe at this point. Comments?
Comments about OARS and CSM age ratings
I’ve had quite a few comments from people stating that using age rating classification values based on American culture is wrong. So far I’ve been using the Common Sense Media research (and various other psychology textbooks) to essentially clean-room implement a content-rating to appropriate age algorithm.
Whilst I do agree that other cultures have different sensitivities (e.g. Smoking in Uganda, references to Nazis in Germany) there doesn’t appear to be much research on the suggested age ratings for different categories for those specific countries. Lots of things are outright banned for sale for various reasons (which the populous may completely ignore), but there doesn’t seem to be many statistics that back up the various anecdotal statements. For instance, are there any US-specific guidelines that say that the age rating for playing a game that involves taking illegal drugs should be 18, rather than the 14 which is inferred from CSM? Or the age rating should be 25+ for any game that features drinking alcohol in Saudi Arabia?
Suggestions (especially references) welcome. Thanks!
GNOME Software and Age Ratings
After all the tarballs for GNOME 3.22 the master branch of gnome-software is now open to new features. Along with the usual cleanups and speedups one new feature I’ve been working on is finally merging the age ratings work.
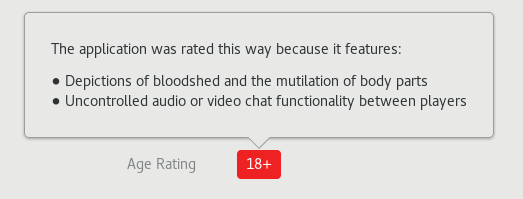
The age ratings are provided by the upstream-supplied OARS metadata in the AppData file (which can be generated easily online) and then an age classification is generated automatically using the advice from the appropriately-named Common Sense Media group. At the moment I’m not doing any country-specific mapping, although something like this will be required to show appropriate ratings when handling topics like alcohol and drugs.
At the moment the only applications with ratings in Fedora 26 will be Steam games, but I’ve also emailed any maintainer that includes an <update_contact> email address in the appdata file that also identifies as a game in the desktop categories. If you ship an application with an AppData and you think you should have an age rating please use the generator and add the extra few lines to your AppData file. At the moment there’s no requirement for the extra data, although that might be something we introduce just for games in the future.
I don’t think many other applications will need the extra application metadata, but if you know of any adult only applications (e.g. in Fedora there’s an application for the sole purpose of downloading p0rn) please let me know and I’ll contact the maintainer and ask what they think about the idea. Comments, as always, welcome. Thanks!
LVFS and ODRS are down
The LVFS firmware server and ODRS reviews server are down because my credit card registered with OpenShift expired. I’ve updated my credit card details, paid the pending invoice and still can’t start any server. I rang customer service who asked me to send an email and have heard nothing back.

I have backups a few days old, but this whole situation is terrible on so many levels.
EDIT: cdaley has got everything back working again, it appears I found a corner case in the code that deals with payments.
Fedora 25 and Additional Software Sources
I was asked to produce a checklist for applications that we want to show up in GNOME Software in Fedora 25. In this post I’ll refer to applications as graphical programs, rather than other system add-on components like drivers and codecs (which the next post will talk about). There is a big checklist, which really is the bare minimum that the distributor has to provide so that the application is listed correctly. If any of these points is causing problems or is confusing, please let me know and I’ll do my best to help.
So, these things really have to be done:
- Verify that you ship a .desktop file for each built application, and that these keys exist:
Name,Comment,Icon,Categories,KeywordsandExecand thatdesktop-file-validatecorrectly validates the file. - Verify that there is a PNG (with transparent background) or SVG icon is installed in
/usr/share/icons,/usr/share/icons/hicolor/*/apps/*, or/usr/share/${app_name}/icons/*and is at least 64×64 in size. - At least one valid AppData file with the suffix
.appdata.xmlfile must be installed into/usr/share/appdatawith an<id>that matches the name of the .desktop file, e.g.gimp.appdata.xml. Ideally the name of both the desktop file and appdata should be reverse DNS, e.g.com.hughski.ColorHug.desktoprather thancolorhug-client.desktopalthough this isn’t critically important. - Include several 16:9 aspect screenshots in the AppData file along with a compelling translated description made up of multiple paragraphs. Make sure you follow the style guide, which can be tested using
appstream-util validate foo.appdata.xml - Make sure that there are not two applications installed with one package; in this case split up the package so that there are multiple subpackages or mark one of the .desktop files as
NoDisplay=true. Make sure the application-subpackages depend on any-commonsubpackage and deal with upgrades (perhaps using a metapackage) if you’ve shipped the application before. - Make sure your application is visible in the
example.xml.gzfile when runningappstream-builderon the binary rpm(s). - Make sure the AppStream metadata is regenerated when the application is updated in the repo, for more details see an entire blog post on this
- Ensure that
enabled_metadata=1is set in the.repofile. This means that PackageKit will automatically download just the application metadata even when the repository is disabled.
Getting S3 Statistics using S3stat
I’ve been using Amazon S3 as a CDN for the LVFS metadata for a few weeks now. It’s been working really well and we’ve shifted a huge number of files in that time already. One thing that made me very anxious was the bill that I was going to get sent by Amazon, as it’s kinda hard to work out the total when you’re serving cough millions of small files rather than a few large files to a few people. I also needed to keep track of which files were being downloaded for various reasons and the Amazon tools make this needlessly tricky.
I signed up for the free trial of S3stat and so far I’ve been pleasantly surprised. It seems to do a really good job of graphing the spend per day and also allowing me to drill down into any areas that need attention, e.g. looking at the list of 404 codes various people are causing. It was fairly easy to set up, although did take a couple of days to start processing logs (which is all explained in the set up). Amazon really should be providing something similar.
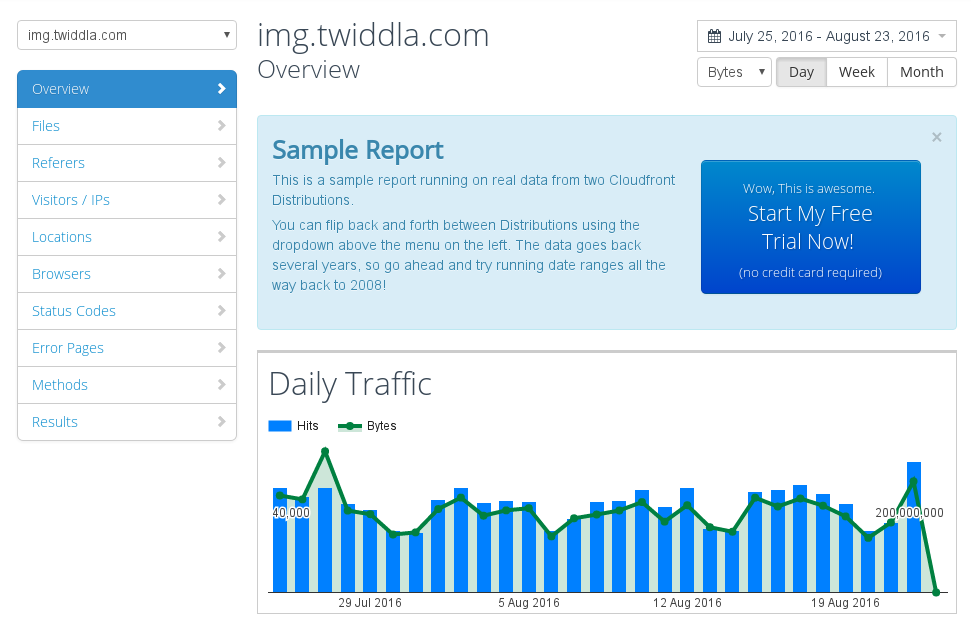
For people providing less than 200,000 hits per day it’s only $10, which seems pretty reasonable. For my use case (bazillions of small files) it rises to a little-harder-to-justify $50/month.
I can’t justify the $50/month for the LVFS, but luckily for me they have a Cheap Bastard Plan (their words, not mine!) which swaps a bit of advertising for a free unlimited license. Sounds like a fair swap, and means it’s available for a lot of projects where $600/yr is better spent elsewhere.