When you do a search in GNOME Software it returns any result of any application with AppStream metadata and with a package name it can resolve in any remote repository. This works really well for software you’re installing from the main distribution repos, but less well for some other common cases.
Lets say I want to install Google Chrome so that my 2 year old daughter can ring me on hangouts, and tell me that dinner is ready. Lets search for Chrome on my Fedora Rawhide system.
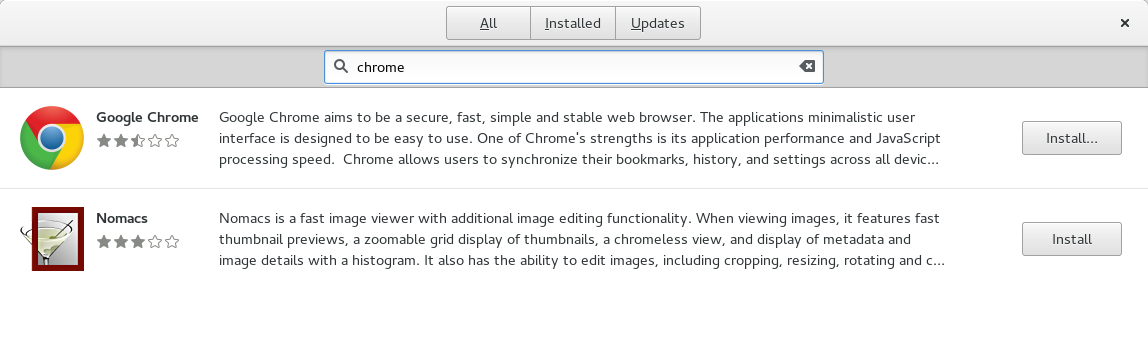
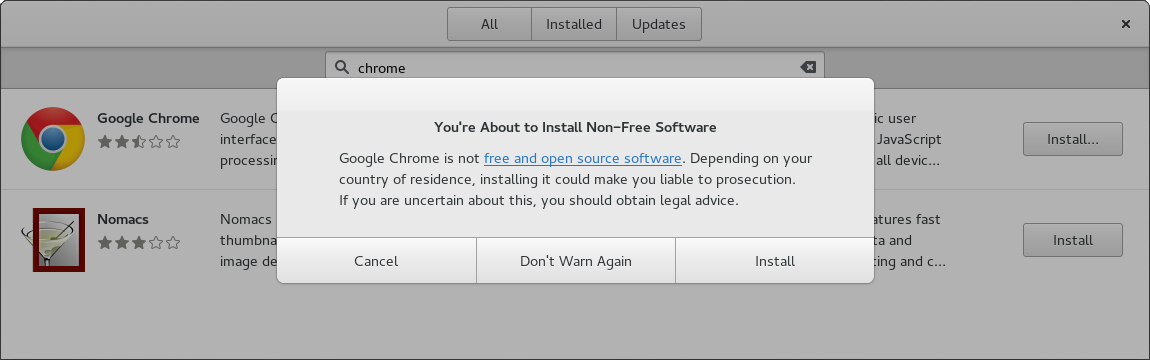
Whoa! Wait, how did you do that? First, this exists in /etc/yum.repos.d/google-chrome.repo — the important line being enabled_metadata=1. This means “download just the metadata even when enabled=0” and means we can get information about what packages are available in repos we are not enabling by default for legal or policy reasons.
[google-chrome] name=google-chrome baseurl=http://dl.google.com/linux/chrome/rpm/stable/x86_64 enabled=0 gpgcheck=1 repo_gpgcheck=1 enabled_metadata=1 gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub
We’ve also got a little XML document with the AppStream metadata (just the long description and keywords) called /usr/share/app-info/xmls/google-chrome.xml which could be included in the usual vendor-supplied fedora-22.xml if that’s what we want to do.
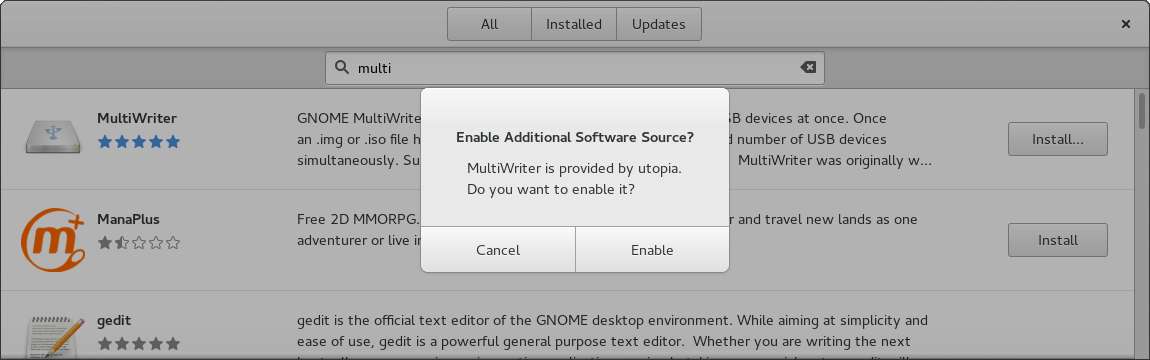
The other awesome feature this unlocks is when we have addon repos that are not enabled by default. For instance, my utopia repo full of super new free software applications could be included in Fedora, and if the user types in the search word we ask if the repo should be enabled. This would solve a lot of use cases if we could ship .repo files for a few popular COPRs of stuff we don’t (yet) ship in Fedora, but are otherwise free and open source software.
All the components to do this are upstream in Fedora 22 (you need a new librepo, libhif, PackageKit, libappstream-glib and gnome-software, phew!) although I’m sure we’ll be tweaking the UI and UX before Fedora 22 is released. Comments welcome.