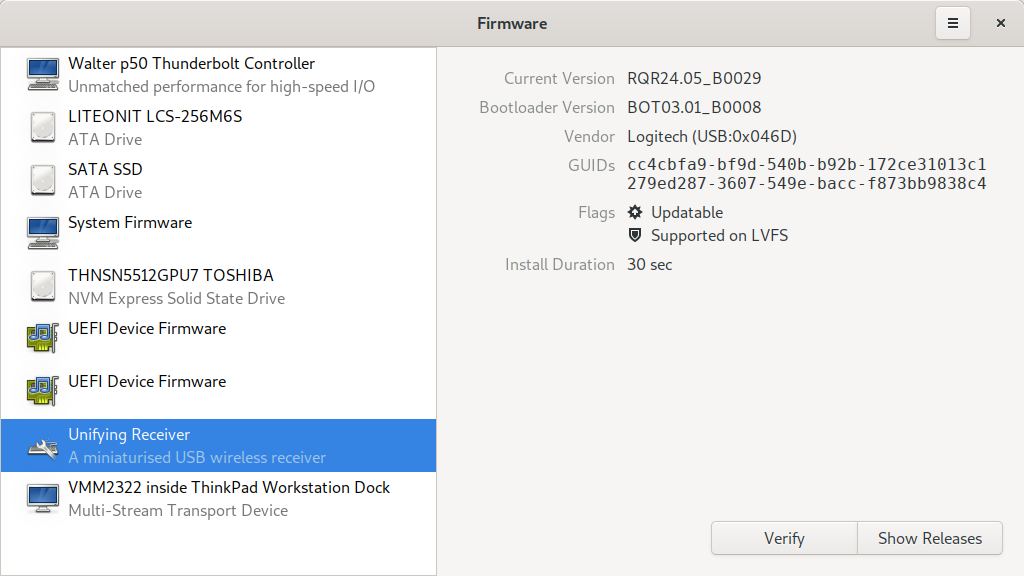
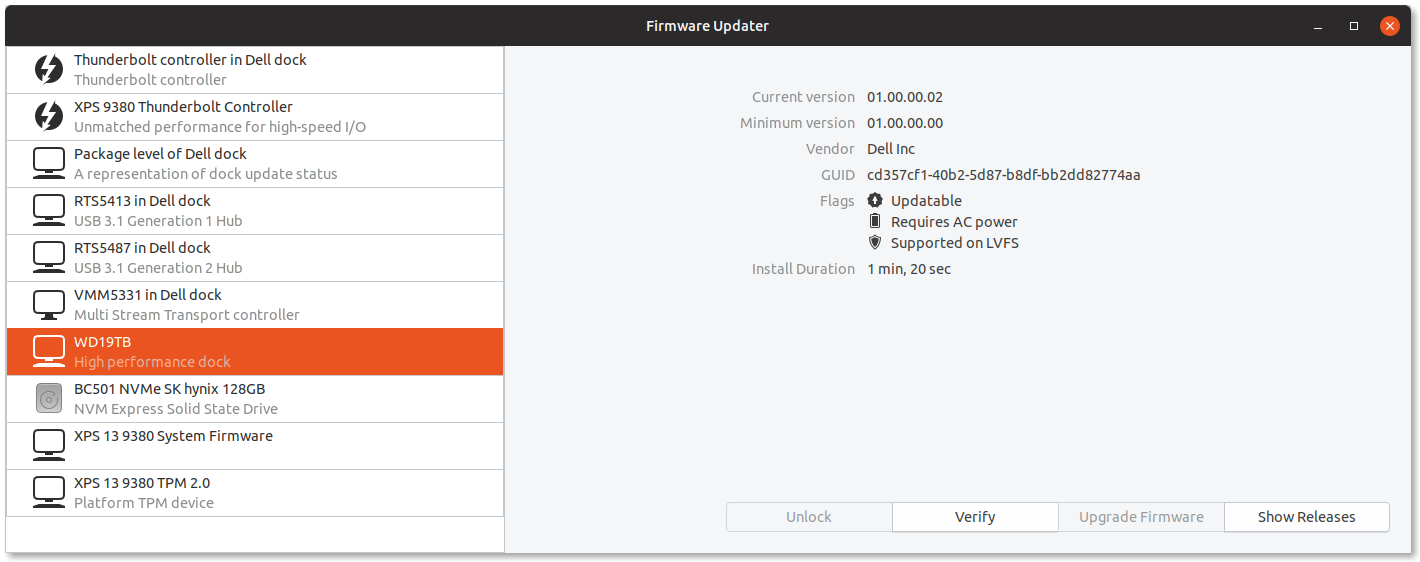
In my slightly infamous email to fedora-devel I stated that I would turn off the snapd support in the gnome-software package for Fedora 31. A lot of people agreed with the technical reasons, but failed to understand the bigger picture and asked me to explain myself.
I wanted to tell a little, fictional, story:
In 2012 the ISO institute started working on a cross-vendor petrol reference vehicle to reduce the amount of R&D different companies had to do to build and sell a modern, and safe, saloon car.
Almost immediately, Mercedes joins ISO, and starts selling the ISO car. Fiat joins in 2013, Peugeot in 2014 and General Motors finally joins in 2015 and adds support for Diesel engines. BMW, who had been trying to maintain the previous chassis they designed on their own (sold as “BMW Kar Koncept”), finally adopts the ISO car also in 2015. BMW versions of the ISO car use BMW-specific transmission oil as it doesn’t trust oil from the ISO consortium.
Mercedes looks to the future, and adds high-voltage battery support to the ISO reference car also in 2015, adding the required additional wiring and regenerative braking support. All the other members of the consortium can use their own high voltage batteries, or use the reference battery. The battery can be charged with electricity from any provider.
In 2016 BMW stops marketing the “ISO Car” like all the other vendors, and instead starts calling it “BMW Car” instead. At about the same time BMW adds support for hydrogen engines to the reference vehicle. All the other vendors can ship the ISO car with a Hydrogen engine, but all the hydrogen must be purchased from a BMW-certified dealer. If any vendor other than BMW uses the hydrogen engines, they can’t use the BMW-specific heat shield which protects the fuel tank from exploding in the event on a collision.
In 2017 Mercedes adds traction control and power steering to the ISO reference car. It is enabled almost immediately and used by nearly all the vendors with no royalties and many customer lives are saved.
In 2018 BMW decides that actually producing vendor-specific oil for it’s cars is quite a lot of extra work, and tells all customers existing transmission oil has to be thrown away, but now all customers can get free oil from the ISO consortium. The ISO consortium distributes a lot more oil, but also has to deal with a lot more customer queries about transmission failures.
In 2019 BMW builds a special cut-down ISO car, but physically removes all the petrol and electric functionality from the frame. It is rebranded as “Kar by BMW”. It then sends a private note to the chair of the ISO consortium that it’s not going to be using ISO car in 2020, and that it’s designing a completely new “Kar” that only supports hydrogen engines and does not have traction control or seatbelts. The explanation given was that BMW wanted a vehicle that was tailored specifically for hydrogen engines. Any BMW customers using petrol or electricity in their car must switch to hydrogen by 2020.
The BMW engineers that used to work on ISO Car have been shifted to work on Kar, although have committed to also work on Car if it’s not too much extra work. BMW still want to be officially part of the consortium and to be able to sell the ISO Car as an extra vehicle to the customer that provides all the engine types (as some customers don’t like hydrogen engines), but doesn’t want to be seen to support anything other than a hydrogen-based future. It’s also unclear whether the extra vehicle sold to customers would be the “ISO Car” or the “BMW Car”.
One ISO consortium member asks whether they should remove hydrogen engine support from the ISO car as they feel BMW is not playing fair. Another consortium member thinks that the extra functionality could just be disabled by default and any unused functionality should certainly be removed. All members of the consortium feel like BMW has pushed them too far. Mercedes stop selling the hydrogen ISO Car model stating it’s not safe without the heat shield, and because BMW isn’t going to be supporting the ISO Car in 2020.