Keyboard layout for combining diacritics
February 20, 2008
Typically, if you want to type characters with accents, such as á, ë, ś, you need to configure a suitable keyboard layout that includes compose sequences for those characters. The produced characters are what we call as precomposed characters; which were included in the early stages of Unicode. Nowdays, the idea is that you do not need to define á as a distinct character because it can be represented as a and ´, where the latter is a combining diacritic.
When put together a character and a combining diacritic, they fuse together, producing a seemingly single character. á is a precomposed (really one character), while á is letter a and the combining diacritic called acute (two characters). You can type the latter á by
- Type a
- Press Ctrl+Shift+u, then type 301, then press space bar.
Western languages do not really require combining marks, so the existing keyboard layouts do not use them. Other scripts, such as the Congolese keyboard layout (based on Latin) make good use of them.

This is gedit showing off pango and DejaVu fonts (default font in major distributions).
Line 3 is a bit of an extreme, showing a sandwich of combining diacritics.
Line 4 shows the base character a with the combining diacritics from the Unicode range 0x300 to 0x315.
Both lines 3 and 4 were produced easily with a modified keyboard layout, which is show below.
Line 5 is just me being silly. You can have combining diacritics that enclose your base character.
$ cat /usr/share/X11/xkb/symbols/combining
partial alphanumeric_keys alternate_group
xkb_symbols "combining" {
name[Group1] = "Combining diacritics";
key.type[Group1] = "FOUR_LEVEL";
key <AD11> { [ NoSymbol, NoSymbol, 0x1000300, 0x1000301 ] }; // à á
key <AD12> { [ NoSymbol, NoSymbol, 0x1000302, 0x1000303 ] }; // â ã
key <AC10> { [ NoSymbol, NoSymbol, 0x1000304, 0x1000305 ] }; // ā a̅
key <AC11> { [ NoSymbol, NoSymbol, 0x1000306, 0x1000307 ] }; // ă ȧ
key <BKSL> { [ NoSymbol, NoSymbol, 0x1000308, 0x1000309 ] }; // ä ả
key <AB08> { [ NoSymbol, NoSymbol, 0x1000310, 0x1000311 ] }; // a̐ ȃ
key <AB09> { [ NoSymbol, NoSymbol, 0x1000312, 0x1000313 ] }; // a̒ a̓
key <AB10> { [ NoSymbol, NoSymbol, 0x1000314, 0x1000315 ] }; // a̔ a̕
};
$ diff -u /usr/share/X11/xkb/symbols/us.ORIGINAL /usr/share/X11/xkb/symbols/us
--- /usr/share/X11/xkb/symbols/us.ORIGINAL 2008-02-20 11:11:13.000000000 +0000
+++ /usr/share/X11/xkb/symbols/us 2008-02-20 13:02:07.000000000 +0000
@@ -492,3 +492,12 @@
name[Group1]= "U.S. English - Macintosh";
};
+partial alphanumeric_keys modifier_keys
+xkb_symbols "combining_us" {
+
+ include "us"
+ include "combining"
+
+ key.type[Group1] = "FOUR_LEVEL";
+ name[Group1] = "U.S. English - Combining";
+};
$ diff -u /usr/share/X11/xkb/rules/xorg.xml.ORIGINAL /usr/share/X11/xkb/rules/xorg.xml
--- /usr/share/X11/xkb/rules/xorg.xml.ORIGINAL 2008-02-20 11:27:00.000000000 +0000
+++ /usr/share/X11/xkb/rules/xorg.xml 2008-02-20 11:27:48.000000000 +0000
@@ -3643,6 +3643,12 @@
<description xml:lang="zh_TW">Macintosh</description>
</configItem>
</variant>
+ <variant>
+ <configItem>
+ <name>combining_us</name>
+ <description>Combining</description>
+ </configItem>
+ </variant>
</variantList>
</layout>
<layout>
$ _
Then, you select this keyboard layout (U.S. English) and variant (Combining) in the Keyboard Indicator applet.
Unlike dead keys, with combining diacritics you first type the base character (such as a) and then any combining diacritics.
Our sample layout variant puts the diacritics in the physical keys for [];’#,./. For example,
- a + AltGr+[ : à
- a + AltGr+Shift+[ : á
- a + AltGr+[ + AltGr+’ : ằ
If your language has needs that can be solved with combining diacritics, this is how they are solved.
It is quite important to create keyboard layouts for all languages, and actually make good use of them.
Typing squiggles and dots in GNOME and GTK+ applications
February 3, 2008
Garrett asks how to type squiggles and dots in GNOME; that is, how to type characters such as á à ä ã â ą ȩ ę ő ǰ ǩ ǒ ġ ṅ ȯ ṁ ė.
There are several ways, and one can choose depending on how frequently they need to type them or how much time they need to invest learning.
① One option is to start the Character Map (Applications/Accessories/Character Map), pick the character, copy and paste it. This is good for rare characters and weird situations such as
┏━━━━━━━━━━━━━━━━━━━━━━━┓
⟁⟁⟁⟁♥♀★★▶◀☆♀░░░▒▒▒▓▓▓▙▚▛▙▙▙▞
The Unicode standard, apart from defining characters for languages, it also defines symbols, dingbats and all sort of things. If your distribution is based on the DejaVu fonts (such as Ubuntu), then you are probably covered for many of these symbols. If you do not have a suitable font, or you use Windows, you will be wondering what the hell I am talking about.
② Another option is to use the Character Palette applet which shows an applet on the panel with a configurable small repertoire of characters such as áàéíñó½©ث€. You select one of the characters with the mouse, and wherever you middle-click, this character is typed. This is an improvement over ①, and good when you want to type often rare characters. It is not convenient to type characters found normally on a keyboard layout.
③ To type characters normally found in a specific language(s), it is good to setup a suitable keyboard layout. For this, it is good to add the Keyboard Indicator applet; right click on the panel, click Add to panel… and choose the Keyboard Indicator from the Utilities section. The US English keyboard layout (Default variant) does not provide any interesting characters apart from those shown printed on the keys of a US Keyboard.
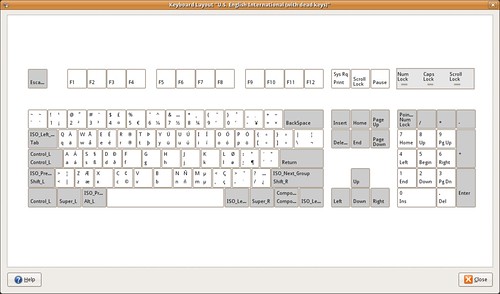
The US English International (with dead keys) variant might be a better option,
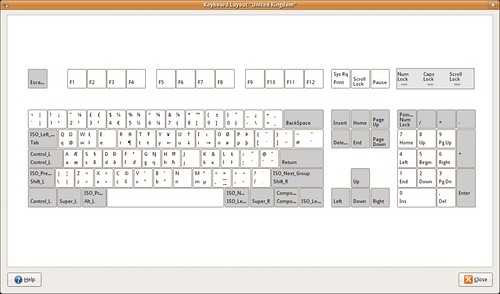
Or the United Kingdom layout.
You can get a similar image for your layout when you right-click on the Keyboard Indicator applet, then click Show Current Layout.
Each key in the images contain up to four letters. Starting from bottom-left and going clock-wise, these are the keys produced when
ⓐ you press the key
ⓑ you press the key with Shift (or Caps Lock)
ⓒ you press the key with AltGr and Shift (or Caps Lock)
ⓓ you press the key with AltGr
For example, with the UK keyboard layout, the key G produces g, G, Ŋ, ŋ.
If AltGr + Shift + letter does not work for you, see the FDO Bug #2871 Different results for shift-altgr and altgr-shift.
Using the appropriate keyboard layout is the way to go when writing text that require squiggles. You can either choose a layout with dead keys (meaning that some keys lose their normal functionality), or you can pick a layout that still allows you to have dead keys but are available when you press AltGr + key. For example, in the UK Keyboard layout – Default variant, AltGr + ; + a produces á, or AltGr+Shift+]+e produces ē.

The OLPC uses those four level for the keyboard layout. You can see the all the variations printed on the keyboard. Click on the image, choose Large size for the details.
④ Another option to produce more characters on the keyboard is to enable the compose key, and use compose sequences. A compose sequence looks similar to what we described above (i.e. AltGr+Shift+]+e to ē) but the idea is that we use it for characters we want to be available across different keyboard layouts that you may have enabled.

The compose key is very powerful functionality, thus it is not enabled by default, and lays hidden in the Layout Options tab. I prefer to set it to Menu, but every person has their own preference.
For example,
- Compose key + – + a produces ã,
- Compose key + < + c produces č
- Compose key + 1 + s produces ¹ (Superscript on 1. Try to replace 1 with 2.)
- Compose key + + + – procudes ±
Currently, GTK+ provides 640 such compose sequences involving the Compose key, and hopefully soon it will increase to over 3000.
The Compose key is known as Multi_key in the source code (Xorg, GTK+, etc).
The Compose key compose sequences offer the ability to define smart mnemonics on how to produce characters. It is much easier to type ComposeKey + 1 + s rather than remembering the codepoint value of ¹ (1 superscript). As with many things open-source, there are too many options, and with the Compose key there is the issue of which shall we pick as a sensible default, and how to make it prominent for those who might want to use it.
It appears to me that there should be more effort to promote the functionality that is provided with the standard keyboard layouts (choose a better keyboard layout, produce characters provided in the third and fourth levels, etc). In this respect, Compose key compose sequences should complement after the main discussion on keyboard layouts take place.
⑤ There is a last issue on switching keyboard layouts to cover in a separate post.
Improving input method support in GTK+-based apps
January 30, 2008
When a bug report gets long with many comments, it gets more difficult for someone to get the full picture of what is going on. I’ll attempt to summarise here what’s being said in Bug 321896, Synch gdkkeysyms.h / gtkimcontextsimple.c with X.org 6.9/7.0.
GTK+-based applications use by default the GTK+ Input Method in order to let users type in different languages. Some scripts are very complex (such as SE Asian scripts) and in this case SCIM is used, replacing the GTK+ Input Method. One can even disable GTK+ IM altogether and use the basic X Input Method (XIM) which is provided by the Xorg server, by setting GTK_IM_MODULE to xim. However, the majority of the users have GTK+ IM enabled.
Between GTK+ IM and XIM, the keyboard layouts are being managed by the xkeyboard-config project and Sergey Udaltsov. A keyboard layout is simply a mapping of keyboard keys to Unicode characters, but you can also have compose sequences for some characters using what we call dead keys. When you press a dead key nothing appears on screen but when you press a letter immediately afterwards, you can get an á. This functionality is common to add accents, and there is a big table for these compose sequences (1.3MB) and what Unicode characters they produce.
If you change your keyboard layout (System/Preferences/Keyboard/Layout) to something like U.S. English International (with dead keys), then the ‘ key on your keyboard becomes dead_acute, and the compose sequence
<dead_acute> <a> : "á" U00E1 # LATIN SMALL LETTER A WITH ACUTE
works when you press ‘ and then a.
There is an issue with compose sequences and input methods; XIM maintains the official upstream version of the compose sequences, and projects such as GTK+ and SCIM carry their own copies of that table.
The issue with GTK+ regarding the compose sequences is that it has a very old version compared to what is available upstream. This is what Bug 321896 is about.
The bug would be have been resolved much much earlier if it wasn’t for the insistence of the GTK+ maintainers to cut the fat and reduce the size of the table (~6000 entries) with clever optimisations.
Tor suggested a clever optimisation; a good number of compose sequences (which looks like <dead_acute> <a> : “á”) resemble the decomposed form (a la Unicode) of those characters. Thus, we can let the user type what she wants, and we can try Unicode normalisation to see if the sequence is composed to a single Unicode character. Lets demonstrate in Python,
$ python
>>> import unicodedata
>>> sequence=[65, 0x301] # That's 'a' and acute
>>> result = unicodedata.normalize('NFC',"".join(map(unichr, sequence)))
>>> result
u'\xc1'
>>> print len(result)
1
>>> print result
Á
That long line above takes the array, applies the unichr() function on each member so that they become Unicode characters and then joins them in a single string. Finally, it normalises the (decomposed) string to a single character. The fact that the resulting string has length 1 (single character) is key to this optimisation. Over 1000 compose sequences can be removed from the compose table through this optimisation. This includes a big chunk of the Latin Unicode blocks, about a few dozens of Cyrillic characters, all of modern Greek and Greek polytonic, some Indic languages (are they actually used?) and other misc sequences.
Matthias laid out the requirements for the optimisation of the remaining compose sequences; ① it has to be static const so a single copy is shared all over the place, ② the first column (out of six) is repeated too often, thus use subtables, and ③ each row ends with a varying number of zeroes, so cut on those zeroes as well. This also required the automatic generation of the optimised table using a script.
The work has not finished yet, and requires testing of the patch. The high priority testing is that keyboard layouts do not get any regressions (that is, compose sequences with dead keys must continue to work along with any new sequences).
With an updated compose table in GTK+, one can write things like ⒼⓃⓄⓂⒺ and all variations of accents on characters, in an easier way.
I’ld like to thank Matthias and Tor for their support in this work. And Jeff for adding this blog to Planet GNOME!
Localisation issues in home directory folders (xdg-user-dirs)
November 11, 2007
In new distributions such as Ubuntu 7.10 there is now support for folder names of personal data in your local language. What this means is that ~/Desktop can now be called ~/Επιφάνεια εργασίας. You also get a few more default folders, including ~/Music, ~/Documents, ~/Pictures and so on.
This functionality of localised home folders has become available thanks to a new FreeDesktop standard, XDG-USER-DIRS. xdg-user-dirs can be localised, and the current localisations are available at xdg-user-dirs/po.

A potential issue arises when a user logs in with different locales; how does the system switch between the localised versions of the folder names? For GNOME there is a migration tool; as soon as you login into your account with a different locale, the system will prompt whether you wish to switch the names from one language to another. This is available through the xdg-user-dirs-gtk application.
Another issue is with users who use the command line quite often; switching between two languages (for those languages that use a script other than latin) tends to become cumbersome, especially if you have not setup your shell for intelligent completion. In addition, when you connect remotely using SSH, you may not be able to type in the local language at the initial computer which would make work very annoying.
Furthermore, there have been reports with KDE applications not working; if someone can bug report it and post the link it would be great. The impression I got was that some installations of KDE did not read off the filesystem in UTF-8 but in a legacy 8-bit encoding. This requires further investigation.
Moreover, OpenOffice.org requires some integration work to follow the xdg-user-dirs standard; apparently it has its own option as to which folder it will save into any newly created files. I believe this will be resolved in the near future.
Now, if we just installed Ubuntu 7.10 or Fedora 8, and we got, by default, localised subfolders in our home directory (which we may not prefer), what can we do to revert to non-localised folders?
The lazy way is to logout, choose an English locale as the default locale for the system and log in. You will be presented with the xdg-user-dirs-gtk migration tool (shown above) that will give you the option to switch to English folder names for those personal folders.
Clarification: It is implied for this workaround (logout and login thing), you then log out again, set the language to the localised one (i.e. Greek) and log in. This time, when the system asks to rename the personal folders, you simply answer no, and you end up with a localised desktop but personal folders in English. Mission really accomplished.
If you are of the tinkering type, the files to change manually are
$ cat ~/.config/user-dirs.locale
el_GR
$
and
$ cat ~/.config/user-dirs.dirs
# This file is written by xdg-user-dirs-update
# If you want to change or add directories, just edit the line you’re
# interested in. All local changes will be retained on the next run
# Format is XDG_xxx_DIR=”$HOME/yyy”, where yyy is a shell-escaped
# homedir-relative path, or XDG_xxx_DIR=”/yyy”, where /yyy is an
# absolute path. No other format is supported.
#
XDG_DESKTOP_DIR=”$HOME/Επιφάνεια εργασίας”
XDG_DOWNLOAD_DIR=”$HOME/Επιφάνεια εργασίας”
XDG_TEMPLATES_DIR=”$HOME/Πρότυπα”
XDG_PUBLICSHARE_DIR=”$HOME/δημόσιο”
XDG_DOCUMENTS_DIR=”$HOME/Έγγραφα”
XDG_MUSIC_DIR=”$HOME/Μουσική”
XDG_PICTURES_DIR=”$HOME/Εικόνες”
XDG_VIDEOS_DIR=”$HOME/Βίντεο”
Personally I believe that having localised names appear under the home folder is good for the majority of users, as they will be able to match what is shown in Locations with the actual names on the filesystem.
There will be cases that software has to be updated and bugs fixed (such as in backup tools). As we proceed with more advanced internationalisation/localisation support in Linux, it is desirable to follow forward, and fix problematic software.
However, if enough popular support arises with clear arguments (am referring to Greek-speaking users and a current discussion) for default folder names in the English languages, we could follow the popular demand.
Also see the relevant blog post New Dirs in Gutsy: Documents, Music, Pictures, Blah, Blah by Moving to Freedom.
Greek OLPC localisation status
August 5, 2007
The Greek OLPC localisation effort is ongoing and here is a report of the current status.
For discussions, reading discussion archives and commenting, please see the Greek OLPC Discussion Group.
We are localising two components, the UI (User Interface) and applications of the OLPC, and the main website at http://www.laptop.org/
The UI is currently being translated at the OLPC Wiki, at OLPC_Greece/Translation. At this page you can see the currently available packages, what is pending and which is the page that you also can help translate.
At this stage we need people with skills in music terminology to help out with the localisation of TamTam. In addition, there are more translations that need review and comments before they are sent upstream.
Moreover, if you find a typo and a better suggestion for a term in the submitted translations, feel free to tell us at the Greek OLPC Discussion Group.
The other project we are working on is the localisation of the Greek version of www.laptop.org. The pages are not 100% translated yet, so if you want to finish the difficult parts, see the Web translation page of laptop.org.
The translators that helped up to now have done an amazing job.
During GUADEC, Tomas Frydrych gave a talk on exmap-console, a cut-down version of exmap that can work well on mobile devices.
During the presentation, Tomas showed how to use the tool to find the culprits in memory (ab)use on the GNOME desktop. One issue that came up was that the MO files taking up space though the desktop showed English. Why would the MO translation files loaded in memory be so big in size?
gtk20.mo : VM 61440 B, M 61440 B, S 61440 B atk10.mo : VM 8192 B, M 8192 B, S 8192 B libgnome-2.0.mo : VM 28672 B, M 24576 B, S 24576 B glib20.mo : VM 20480 B, M 16384 B, S 16384 B gtk20-properties.mo : VM 128 KB, M 116 KB, S 116 KB launchpad-integration.mo : VM 4096 B, M 4096 B, S 4096 B
A translation file looks like
msgid “File”
msgstr “”
When translated to Greek it is
msgid “File”
msgstr “Αρχείο”
In the English UK translation it would be
msgid “File”
msgstr “File”
This actually is not necessary because if you leave those messags untranslated, the system will use the original messages that are embedded in the executable file.
However, for the purposes of the English UK, English Canadian, etc teams, it makes sense to copy the same messages in the translated field because it would be an indication that the message was examined by the translation. Any new messages would appear as untranslated and the same process would continue.
Now, the problem is that the gettext tools are not smart enough when they compile such translation files; they replicate without need those messages occupying space in the generated MO file.
Apart from the English variants, this issue is also present in other languages when the message looks like
msgid “GConf”
msgstr “GConf”
Here, it does not make much sense to translate the message in the locale language. However, the generated MO file contains now more than 10 bytes (5+5) , plus some space for the index.
Therefore, what’s the solution for this issue?
One solution is to add to msgattrib the option to preprocess a PO file and remove those unneeded copies. Here is a patch,
— src.ORIGINAL/msgattrib.c 2007-07-18 17:17:08.000000000 +0100
+++ src/msgattrib.c 2007-07-23 01:20:35.000000000 +0100
@@ -61,7 +61,8 @@
REMOVE_FUZZY = 1 << 2,
REMOVE_NONFUZZY = 1 << 3,
REMOVE_OBSOLETE = 1 << 4,
– REMOVE_NONOBSOLETE = 1 << 5
+ REMOVE_NONOBSOLETE = 1 << 5,
+ REMOVE_COPIED = 1 << 6
};
static int to_remove;
@@ -90,6 +91,7 @@
{ “help”, no_argument, NULL, ‘h’ },
{ “ignore-file”, required_argument, NULL, CHAR_MAX + 15 },
{ “indent”, no_argument, NULL, ‘i’ },
+ { “no-copied”, no_argument, NULL, CHAR_MAX + 19 },
{ “no-escape”, no_argument, NULL, ‘e’ },
{ “no-fuzzy”, no_argument, NULL, CHAR_MAX + 3 },
{ “no-location”, no_argument, &line_comment, 0 },
@@ -314,6 +316,10 @@
to_change |= REMOVE_PREV;
break;
+ case CHAR_MAX + 19: /* –no-copied */
+ to_remove |= REMOVE_COPIED;
+ break;
+
default:
usage (EXIT_FAILURE);
/* NOTREACHED */
@@ -436,6 +442,8 @@
–no-obsolete remove obsolete #~ messages\n”));
printf (_(“\
–only-obsolete keep obsolete #~ messages\n”));
+ printf (_(“\
+ –no-copied remove copied messages\n”));
printf (“\n”);
printf (_(“\
Attribute manipulation:\n”));
@@ -536,6 +544,21 @@
: to_remove & REMOVE_NONOBSOLETE))
return false;
+ if (to_remove & REMOVE_COPIED)
+ {
+ if (!strcmp(mp->msgid, mp->msgstr) && strlen(mp->msgstr)+1 >= mp->msgstr_len)
+ {
+ return false;
+ }
+ else if ( strlen(mp->msgstr)+1 < mp->msgstr_len )
+ {
+ if ( !strcmp(mp->msgstr + strlen(mp->msgstr)+1, mp->msgid_plural) )
+ {
+ return false;
+ }
+ }
+ }
+
return true;
}
However, if we only change msgattrib, we would need to adapt the build system for all packages.
Apparently, it would make sense to change the default behaviour of msgfmt, the program that compiles PO files into MO files.
An e-mail was sent to the email address for the development team of gettext regarding the issue. The development team does not appear to have a Bugzilla to record these issues. If you know of an alternative contact point, please notify me.
Update #1 (23Jul07): As an indication of the file size savings, the en_GB locale on Ubuntu in the installation CD occupies about 424KB where in practice it should have been 48KB.
A full installation of Ubuntu with some basic KDE packages (only for the basic libraries, i.e. KBabel – (ls k* | wc -l = 499)) occupies about 26MB of space just for the translation files. When optimising in the MO files, the translation files occupy only 7MB. This is quite important because when someone installs for example the en_CA locale, all en_?? locales are added.
The reason why the reduction is more has to do with the message types that KDE uses. For example,
msgid “”
“_: Unknown State\n”
“Unknown”
msgstr “Unknown”
I cannot see a portable way to code the gettext-tools so that they understand that the above message can be easily omitted. For the above reduction to 7MB, KDE applications (k*) occupy 3.6MB. The non-KDE applications include GNOME, XFCE and GNU traditional tools. The biggest culprits in KDE are kstars (386KB) and kgeography (345KB).
Update #2 (23Jul07): (Thanks Deniz for the comment below on gweather!) The po-locations translations (gnome-applets/gweather) of all languages are combined together to generate a big XML file that can be found at usr/share/gnome-applets/gweather/Locations.xml (~15MB).
This file is not kept in memory while the gweather applet is running.
However, the file is parsed when the user opens the properties dialog to change the location.
I would say that the main problem here is the file size (15.8MB) that can be easily reduced when stripping copied messages. This file is included in any Linux distribution, whatever the locale.
The po-locations directory currently occupies 107MB and when copied messages are eliminated it occupies 78MB (a difference of 30MB). The generated XML file is in any case smaller (15.8MB without optimisation) because it does not include repeatedly the msgid lines for each language.
I regenerated the Locations.xml file with the optimised PO files and the resulting file is 7.6MB. This is a good reduction in file space and also in packaging size.
Update #3 (25Jul07): Posted a patch for gettext-tools/msgattrib.c. Sent an e-mail to the kde-i18n-doc mailing list and got good response and a valid argument for the proposed changes. Specifically, there is a case when one gives custom values to the LANGUAGE variable. This happens when someone uses the LANGUAGE variable with a value such as “es:fr” which means show me messages in Spanish and if something is untranslated show me in French. If a message has msgid==msgstr for Spanish but not for French, then it would show in French if we go along with the proposed optimisation.
GUADEC Day #2
July 16, 2007
(see http://www.guadec.org/schedule/warmup)
At the first presentation, Quim Gil talked about GNOME marketing, what have been done, what is the goal of marketing. He showed a focused mind on important marketing tasks; it is easy to get carried away and not be effective, a mistake that happens in several projects.
The next session was by Tomas Frydrych (Open Hand – I have their sticker on my laptop!) on memory use in GNOME applications. Many people complain that XYZ is bloated. However, this does not convey what exactly happens; pretty useless. In addition, the common tools that show memory use do not show the proper picture because of the memory management techniques. That is, due to shared libraries, the total memory occupied by an application appears very big. A tool examined is exmap. This tool uses a kernel module that shows memory use of applications by reading in /proc. It takes a snapshot of memory use; it’s not real-time info. It comes with a GTK+ front-end (gexmap) that requires a big screen (oops, PDAs). However, it is not suitable for internet tablets and other low-spec devices. Therefore, they came up with exmap-console which addresses the shortcommings. It has a console interface based on the readline library.
Here are the rest of my notes. Hope they make sense to you.
. exmap –interactive
. ?: help
. Head: quite useful (dynamic allocation)
. Mapped:
. Sole use: memory that app is using on its own (rss?)
. “sort vm”
. “print” or “p”
. “add nautilus”
. “clear”
. “detail file” (what executables/libs loaded and how much consume)
. “detail none”Sole use
. valgrind, to analyse Sole Use memory?
. “detail ????”Lots of small libraries: overhead
Looking ahead
. Pagemap: by Matt Macall
. http://projects.o-hand.com/exmap-console/Python
. Sole use: ~18MB ;-(
Tomas was apparently running Ubuntu with the English UK locale. The English UK translation team is doing an amazing job at the translation stats. Actually, most messages are copied, however with a script one can pick up words such as organization and change to organisation. The problem here is that, for example, the GAIM mo file is 215KB (?), however for the British English translation the actual changes should be less than 2-3KB. Messages that are missing from a translation mean that the original US English messages will be used. I’ll have to find how to use msgfilter to make messages untranslated if msgid == msgstr. Where is Danilo?
After lunch time (did not go for lunch), I went to the Accerciser session. Pretty cool tool, something I have been look for. Accerciser uses the accessibility framework of GNOME in order to inspect the windows of running applications and see into the properties. A good use is to identify if elements such as text boxes come with description labels; they are important to be there for accessibility purposes (screen reader), as a person that depends on software to read (text to speech) the contents of windows.
The next session was GNOME accessibility for blind people. Jan Buchal gave an excellent presentation.
My notes,
. is from Chech republic, is blind himself. has been using computers for 20+ years
. from user perspective
. users, regular and irregular 😉
. software
. firefox 3.0beta – ok for accessibility other versions no
. gaim messenger ok
. openoffice.org ok but did not try
. orca screenreader ^^^ works ok.
. generally ready for prime time
. ubuntu guy for accessibility was there
. made joke about not having/needing display slides ;-]
. synthesizer: festival, espeak, etc – can choose
. availability of voices
. javascript: not good for accessibility
. links/w3m: just fine!
. firefox3 makes accessibility now possible.
. web designer education, things like title=””, alt=”” for images.
. OOo, not installed but should work, ooo-gnome
. “braillcom” company name
. “speech dispatcher”
. logical events
. have short sound event instead of “button”, “input form”
. another special sound for emacs prompt, etc.
. uses emacs
. have all events spoken, such as application crashing.
. problems of accessibility
. not money main factor, but still exists.
. standard developers do not use accessibility functions
. “accessor” talk, can help
. small developer group on accessiblity, may not cooperate well
. non-regular users (such as blind musician)
. musicians
. project “singing computer”
. gtk, did not have good infrastructure
. used lilypond (music typesetter, good but not simple to use)
. singing mode in festival
. use emacs with special mode to write music scores (?)
. write music score and have the computer sing it (this is not “caruso”)
. gnome interface for lilypond would be interesting
. chemistry for blind
. gtk+
. considering it
. must also work, unfortunately, on windows
. gtk+ for windows, not so good for accessibility
. conclusion: free accessibility
. need users so that applications can be improved
. have festival synthesizer, not perfect but usable
. many languages, hindi, finnish, afrikaans
. endinburgh project, to reimplement festival better
. proprietary software is a disadvantage
. q: how do you learn to use new software?
. a: has been a computer user for 20+ years, is not good candidate to say
. a: if you are dedicated, you can bypass hardles, old lady emacs/festival/lilypond
. brrlcom, not for end-users(?)
. developer problem?
. generally there is lack of documentation; easy to teach what a developer needs to know
. so that the application is accessible
. HIG Human Interface Guidelines, accessible to the developers
. “speakup” project
. Willy, from Sun microsystems, working on accessibility for +20 years, Lead of Orca.
. developers: feel accessibility is a hindrance to development
. in practice the gap is not huge
. get tools (glade) and gtk+ to come with accessibility on by default
. accessibility
. is not only for people with disabilities
. can do amazing things like 3d interfaces something
These summaries are an important example of the rule that during presentation, participants tend to remember only about 8% of the material. In some examples, even less is being recollected.
GUADEC Day #1
July 16, 2007
I am writing this in the morning of the second day (posted at the end of the second day). Just had breakfast and there is a bit of time before making it to the conference venue.
Yesterday Sunday, was the first of the two days of warm-up for the GUADEC conference. At 11am the registration started. I was in front of the queue and got my badge quickly, then picked up the bag with the goodies; three cool t-shirts, a copy of Ubuntu 7.04, Fedora 7 Live, Linux stickers, two Linux pens, a mini Google Code notebook (no, that’s an actual notebook (not that type of notebook, it was just the paper-based thing)).
During registration I met up with Dimitrios Glezos (of Greek Fedora fame) and a bit later with Dimitrios Typaldos. It was the first time I met both of them in person.
Between a choice of two sessions I went to the one on X.org developments (XDamage, xrender, etc extensions and how to use them). Ryan Lortie gave the presentation.
Next was lunch time, and Dimitrios T. recommended a pub for traditional English food and drink. Sayamindu came along.
The next session I went to was the Hildon desktop, which is what we used to call Maemo; GNOME for internet tables such as the Nokia 770 and Nokia 800. There are special technical issues to solve. Lucas Rocha mentioned refactoring issues with the source code. In addition, as far as I understood, there is an issue with the internationalisation support for the platform.
Next, Don Scorgie talked about the GNOME documentation project. Several things can be improved and one of them is the introduction of a simplified XML schema for the needs of GNOME documentation. When compared to DocBook XML, the new GNOME documentation schema has only 6 elements (or do they call them tags?). In addition to this, there is a documentation editor with a special rich-edit widget for this schema. Mallard is a type of duck(?).
I also attended the last 10 minutes of the presentation on project Jackfield (sadly no special significance between Jackfield and what the project is about). Jackfield is apparently a way to run Javascript scripts on the desktop. OS/X is supposed to have it, and there are already scripts available. With Jackfield, you can run those scripts unmodified on Linux. The demos where really impressive.
The final session for the day was a presentation by Richard Rothwell on free software for the socially excluded. No, you do not have to go to Africa for this. His work relates to families in Nottingham, UK. It reminds me the situation and effort in Farkadona, Greece, that was described by Kostas Boukouvalas. I think it would have been helpful if Kostas Boukouvalas could have attended this. Richard is running a 3-year project that provides a number of PCs (in the hundreds?) with Linux to socially excluded families. Even in the UK, funding is hard to come by.
Google Groups: Member Invite Request Approved
July 6, 2007
When creating a Google Group, you have the option of auto-subscribing a list of e-mails. That is, the owner of the email address does not have perform the subscription task. To avoid the apparent spamming opportunity, Google Groups puts a human to review those requests. After you pasted the e-mail addresses, you press Submit and then get a text box where you can write a message to help this person decide.
While filling such a request, I made a gross mistake and I added 140 more email addresses than I should. In the text box I write with capitals, PLEASE CANCEL THIS REQUEST, MISTAKE.
Just now I got a reply, and that requst got approved. On the positive side, the auto-subscription request was thankfully converted to a notification request, so all these people received a request to join the group.
Thank you all for not complaining!
p.s.
My regular blog is offline for a few days so I am using this one for now.