Towards a GNOME CLI translation management tool
April 8, 2009
In Designing a command-line translation tool for GNOME, I described how a CLI translation management tool would be used to ease the work of a translator with commit access. The discussion was continued with Leonardo‘s post Parsing damned-lies’ releases.xml.in in the command line.
The stage we are now is that we have a tool (not official GNOME tool, but rather at beta testing phase!) that can manage the repositories for us, so that the checking out and committing can be fairly automated. The source is available at http://github.com/simos/intltool-manage-vcs/.
We show two working examples.
Let’s say we want to update the documentation for gcalctool. We run
$ ./intltool-manage-vcs --language el --release gnome-2-26 \ --username simos --module gcalctool --transtype doc --init Release : gnome-2-26 Language : el Category: admin-tools Category: dev-tools Category: dev-platform Category: desktop Module: gcalctool, Branch: gnome-2-26 Download completed successfully.
$ _
In the PO/ subdirectory there is a PO file for gcalctool. We update it using our favourite translation tool, and then
$ ./intltool-manage-vcs --language Greek --commit Sending el/el.po Transmitting file data . Committed revision 2475.
$ _
Let’s see another example. We want to update the gnome-games documentation. These are several individual PO files, for each of the games.
$ ./intltool-manage-vcs --language el --release gnome-2-26 \ --username simos --module gnome-games --transtype doc --init Release : gnome-2-26 Language : el Category: admin-tools Category: dev-tools Category: dev-platform Category: desktop Module: gnome-games, Branch: gnome-2-26 Download completed successfully. $ _
There are several files,
$ ls PO
aisleriot.gnome-2-26.el.po gnibbles.gnome-2-26.el.po
gnotravex.gnome-2-26.el.po README
blackjack.gnome-2-26.el.po gnobots2.gnome-2-26.el.po
gnotski.gnome-2-26.el.po same-gnome.gnome-2-26.el.po
glchess.gnome-2-26.el.po gnome-sudoku.gnome-2-26.el.po
gtali.gnome-2-26.el.po START
glines.gnome-2-26.el.po gnometris.gnome-2-26.el.po
iagno.gnome-2-26.el.po gnect.gnome-2-26.el.po
gnomine.gnome-2-26.el.po mahjongg.gnome-2-26.el.po
$ _
We enter the PO/ subdirectory and we update those files we wish. We can also run scripts on the PO files. For example, all these documentation files contain the same fragment of the FDL license, so we can translate the license once, and then merge automatically to all translations.
Finally,
$ ./intltool-manage-vcs --language Greek --commit Sending el/el.po Transmitting file data . Committed revision 9014. Sending el/el.po Transmitting file data . Committed revision 9015. Sending el/el.po Transmitting file data . Committed revision 9016. $ _
In the above example, we updated the documentation of three of the games.
Here are tips when using this tool
- There is a –dry-run option that is useful when experimenting or trying for the first time.
- You can filter which group of a release to download, based on category. Existing categories are desktop, admin-tools, dev-tools, dev-platform. Also, on translation type, either documentation or UI (if you do not specify, we get both). On module, by providing the module name.
And the current limitations
- We currently only support SVN. This will change once the repositories move to git.gnome.org, in about two weeks time.
- You need to have at least an initial translation (currently, the script does not svn add files). To be fixed once we move to git.
- We do not currently update ChangeLog files. That’s why gnome-games is so cool for these experiments. Due to the git move, we would not need to mess with ChangeLog files.
- We are dependent on the http://l10n.gnome.org/languages/el/gnome-2-26/xml URLs (replace el with your language). These URLs expose the release modules information in a nice XML file. Previously, the information used to exist in an XML file in the repository of damned-lies. Now, the information lies in the mysql database of damned-lies+vertimus, and is exposed through the above type of URL.
- Due to the previous point, we commit to branch or trunk, depending on what is available in the latest release (gnome-2-26). That means, my translation fixes in gnome-games have not made it to trunk (HEAD). This is something that can be fixed with a workaround. It would be actually cool to use this tool to commit to both gnome-2-xx and master at the same time.
- We currently do not deal with figures.
Considering that damned-lies+vertimus will be having commit functionality soon, I think that having more than one option for easy commiting translations is good.
Timezones, clock applet and marketing dangers
March 23, 2008
It is great to receive feedback from users that try out the development versions of distributions (such as Ubuntu and Fedora). Usually, these are small bugs that can easily get fixed. However, there is this bug that looks potent to lead to political dissatisfaction and bad publicity to GNOME.
The clock applet (gnome-panel) now shows the timezones of cities that one selects. You click on the Edit button, you select the city (it comes from Locations.xml – libgweather, which has the coordinates of each city entry), and the applet makes a guess of what is your timezone (each timezone comes with longitude information).
So, if a city is far away from the capital city of your country (and closer to the capital city of a neighboring country), then the applet often proposes the wrong timezone. Considering that in some (=many) cases there is some animosity between neighboring countries, this makes users unhappy.
Launchpad bug report: Bug #185190, Clock applet chooses wrong timezone for many cities (eg Pittsburgh, Beijing)
GNOME Bugzilla bug report: Bug 519823 – Cities associated with wrong timezone
Updated (8Apr2008): The bug has been fixed upstream (thanks Dan!) and most likely makes it in GNOME 2.22.1, which means Ubuntu 8.04 and other distributions will get the update as well. Some countries with regions that have more than one timezone may want to check that the correct timezone is selected for each region.
Designing a command-line translation tool for GNOME
March 3, 2008
One messy task with GNOME translations is the whole workflow of getting the PO files, translating/updating/fixing them, and then uploading them back. One would need to use command line, and several different commands to accomplish this.
KDE and KBabel has a nice feature that allows you to easily grab all translation files, work on them, then commit through SVN. All through the GUI! It helps a bit here that the translation files for a specific language are located under a single directory.
The current workflow in GNOME translations typically consists of
- Getting the PO file from the L10n server (for example, GNOME 2.22 Greek) (also possible to use intltool-update within po/)
- Translate using KBabel, POEdit, GTranslator, vim, emacs, etc.
- svn co the package making sure you have the correct branch. One may limit to the po/ directory.
- Put the updated file in po/
- Update the ChangeLog (either with emacs, or with that Perl script)
- Commit the translation.
- (If you committed on a branch, also commit on HEAD)
Tools such as Transifex (used currently in Fedora) take away altogether the use of command line tools, and one works here through a web-based interface. Apparently, Transifex is having a command-line tool in the TODO list.
What I would like to see in GNOME translations, is a tool that one can use to
- Grab all or a section of the PO files from GNOME 2.22. Put them in a local folder.
- Use the tools of my preference (translation tools, scripts, etc) to update those translations I need to update.
- Commit those translation files that changed (using my SVN account), automatically add ChangeLog entries, also commit to HEAD if required.
I would prefer to have a command-line tool for this, for now, though it would be great if GUI tools would get the same functionality at some point. For a command line tool, the workflow would look like
The workflow would be something like
$ ssh-add Enter passphrase for /home/simos/.ssh/id_rsa: Identity added: /home/simos/.ssh/id_dsa (/home/simos/.ssh/id_dsa)
$ tsfx --project=gnome-2.22 --language=el --collection=gnome-desktop --user=simos --action=checkout
Reading from http://svn.gnome.org/svn/damned-lies/trunk/releases.xml.in... done.
Getting alacarte (HEAD)... done.
Getting bug-buddy (branch: xyz)... done.
...
Completed in 4:11s.
$ _
Now we translate any of the files we downloaded, and we push back upstream (of course, only those files that were changed).
$ tsfx --action=commit
Found local repository, Project: gnome-2.22, Language: el, Collection: gnome-desktop, User: simos
Reading local files...
Found 6 changed files.
Uploading alacarte (HEAD)... done.
Uploading bug-buddy (branch:xyz, HEAD)... done.
...
Completed uploading translation files to gnome-2.22, language el.
$ _
Typing squiggles and dots in GNOME and GTK+ applications
February 3, 2008
Garrett asks how to type squiggles and dots in GNOME; that is, how to type characters such as á à ä ã â ą ȩ ę ő ǰ ǩ ǒ ġ ṅ ȯ ṁ ė.
There are several ways, and one can choose depending on how frequently they need to type them or how much time they need to invest learning.
① One option is to start the Character Map (Applications/Accessories/Character Map), pick the character, copy and paste it. This is good for rare characters and weird situations such as
┏━━━━━━━━━━━━━━━━━━━━━━━┓
⟁⟁⟁⟁♥♀★★▶◀☆♀░░░▒▒▒▓▓▓▙▚▛▙▙▙▞
The Unicode standard, apart from defining characters for languages, it also defines symbols, dingbats and all sort of things. If your distribution is based on the DejaVu fonts (such as Ubuntu), then you are probably covered for many of these symbols. If you do not have a suitable font, or you use Windows, you will be wondering what the hell I am talking about.
② Another option is to use the Character Palette applet which shows an applet on the panel with a configurable small repertoire of characters such as áàéíñó½©ث€. You select one of the characters with the mouse, and wherever you middle-click, this character is typed. This is an improvement over ①, and good when you want to type often rare characters. It is not convenient to type characters found normally on a keyboard layout.
③ To type characters normally found in a specific language(s), it is good to setup a suitable keyboard layout. For this, it is good to add the Keyboard Indicator applet; right click on the panel, click Add to panel… and choose the Keyboard Indicator from the Utilities section. The US English keyboard layout (Default variant) does not provide any interesting characters apart from those shown printed on the keys of a US Keyboard.
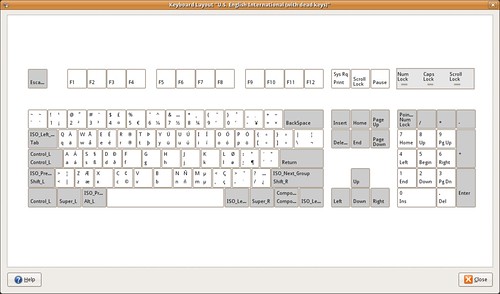
The US English International (with dead keys) variant might be a better option,
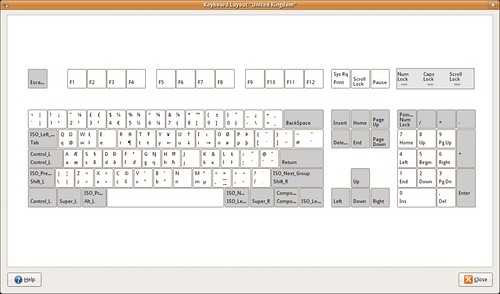
Or the United Kingdom layout.
You can get a similar image for your layout when you right-click on the Keyboard Indicator applet, then click Show Current Layout.
Each key in the images contain up to four letters. Starting from bottom-left and going clock-wise, these are the keys produced when
ⓐ you press the key
ⓑ you press the key with Shift (or Caps Lock)
ⓒ you press the key with AltGr and Shift (or Caps Lock)
ⓓ you press the key with AltGr
For example, with the UK keyboard layout, the key G produces g, G, Ŋ, ŋ.
If AltGr + Shift + letter does not work for you, see the FDO Bug #2871 Different results for shift-altgr and altgr-shift.
Using the appropriate keyboard layout is the way to go when writing text that require squiggles. You can either choose a layout with dead keys (meaning that some keys lose their normal functionality), or you can pick a layout that still allows you to have dead keys but are available when you press AltGr + key. For example, in the UK Keyboard layout – Default variant, AltGr + ; + a produces á, or AltGr+Shift+]+e produces ē.

The OLPC uses those four level for the keyboard layout. You can see the all the variations printed on the keyboard. Click on the image, choose Large size for the details.
④ Another option to produce more characters on the keyboard is to enable the compose key, and use compose sequences. A compose sequence looks similar to what we described above (i.e. AltGr+Shift+]+e to ē) but the idea is that we use it for characters we want to be available across different keyboard layouts that you may have enabled.

The compose key is very powerful functionality, thus it is not enabled by default, and lays hidden in the Layout Options tab. I prefer to set it to Menu, but every person has their own preference.
For example,
- Compose key + – + a produces ã,
- Compose key + < + c produces č
- Compose key + 1 + s produces ¹ (Superscript on 1. Try to replace 1 with 2.)
- Compose key + + + – procudes ±
Currently, GTK+ provides 640 such compose sequences involving the Compose key, and hopefully soon it will increase to over 3000.
The Compose key is known as Multi_key in the source code (Xorg, GTK+, etc).
The Compose key compose sequences offer the ability to define smart mnemonics on how to produce characters. It is much easier to type ComposeKey + 1 + s rather than remembering the codepoint value of ¹ (1 superscript). As with many things open-source, there are too many options, and with the Compose key there is the issue of which shall we pick as a sensible default, and how to make it prominent for those who might want to use it.
It appears to me that there should be more effort to promote the functionality that is provided with the standard keyboard layouts (choose a better keyboard layout, produce characters provided in the third and fourth levels, etc). In this respect, Compose key compose sequences should complement after the main discussion on keyboard layouts take place.
⑤ There is a last issue on switching keyboard layouts to cover in a separate post.
Improving input method support in GTK+-based apps
January 30, 2008
When a bug report gets long with many comments, it gets more difficult for someone to get the full picture of what is going on. I’ll attempt to summarise here what’s being said in Bug 321896, Synch gdkkeysyms.h / gtkimcontextsimple.c with X.org 6.9/7.0.
GTK+-based applications use by default the GTK+ Input Method in order to let users type in different languages. Some scripts are very complex (such as SE Asian scripts) and in this case SCIM is used, replacing the GTK+ Input Method. One can even disable GTK+ IM altogether and use the basic X Input Method (XIM) which is provided by the Xorg server, by setting GTK_IM_MODULE to xim. However, the majority of the users have GTK+ IM enabled.
Between GTK+ IM and XIM, the keyboard layouts are being managed by the xkeyboard-config project and Sergey Udaltsov. A keyboard layout is simply a mapping of keyboard keys to Unicode characters, but you can also have compose sequences for some characters using what we call dead keys. When you press a dead key nothing appears on screen but when you press a letter immediately afterwards, you can get an á. This functionality is common to add accents, and there is a big table for these compose sequences (1.3MB) and what Unicode characters they produce.
If you change your keyboard layout (System/Preferences/Keyboard/Layout) to something like U.S. English International (with dead keys), then the ‘ key on your keyboard becomes dead_acute, and the compose sequence
<dead_acute> <a> : "á" U00E1 # LATIN SMALL LETTER A WITH ACUTE
works when you press ‘ and then a.
There is an issue with compose sequences and input methods; XIM maintains the official upstream version of the compose sequences, and projects such as GTK+ and SCIM carry their own copies of that table.
The issue with GTK+ regarding the compose sequences is that it has a very old version compared to what is available upstream. This is what Bug 321896 is about.
The bug would be have been resolved much much earlier if it wasn’t for the insistence of the GTK+ maintainers to cut the fat and reduce the size of the table (~6000 entries) with clever optimisations.
Tor suggested a clever optimisation; a good number of compose sequences (which looks like <dead_acute> <a> : “á”) resemble the decomposed form (a la Unicode) of those characters. Thus, we can let the user type what she wants, and we can try Unicode normalisation to see if the sequence is composed to a single Unicode character. Lets demonstrate in Python,
$ python
>>> import unicodedata
>>> sequence=[65, 0x301] # That's 'a' and acute
>>> result = unicodedata.normalize('NFC',"".join(map(unichr, sequence)))
>>> result
u'\xc1'
>>> print len(result)
1
>>> print result
Á
That long line above takes the array, applies the unichr() function on each member so that they become Unicode characters and then joins them in a single string. Finally, it normalises the (decomposed) string to a single character. The fact that the resulting string has length 1 (single character) is key to this optimisation. Over 1000 compose sequences can be removed from the compose table through this optimisation. This includes a big chunk of the Latin Unicode blocks, about a few dozens of Cyrillic characters, all of modern Greek and Greek polytonic, some Indic languages (are they actually used?) and other misc sequences.
Matthias laid out the requirements for the optimisation of the remaining compose sequences; ① it has to be static const so a single copy is shared all over the place, ② the first column (out of six) is repeated too often, thus use subtables, and ③ each row ends with a varying number of zeroes, so cut on those zeroes as well. This also required the automatic generation of the optimised table using a script.
The work has not finished yet, and requires testing of the patch. The high priority testing is that keyboard layouts do not get any regressions (that is, compose sequences with dead keys must continue to work along with any new sequences).
With an updated compose table in GTK+, one can write things like ⒼⓃⓄⓂⒺ and all variations of accents on characters, in an easier way.
I’ld like to thank Matthias and Tor for their support in this work. And Jeff for adding this blog to Planet GNOME!