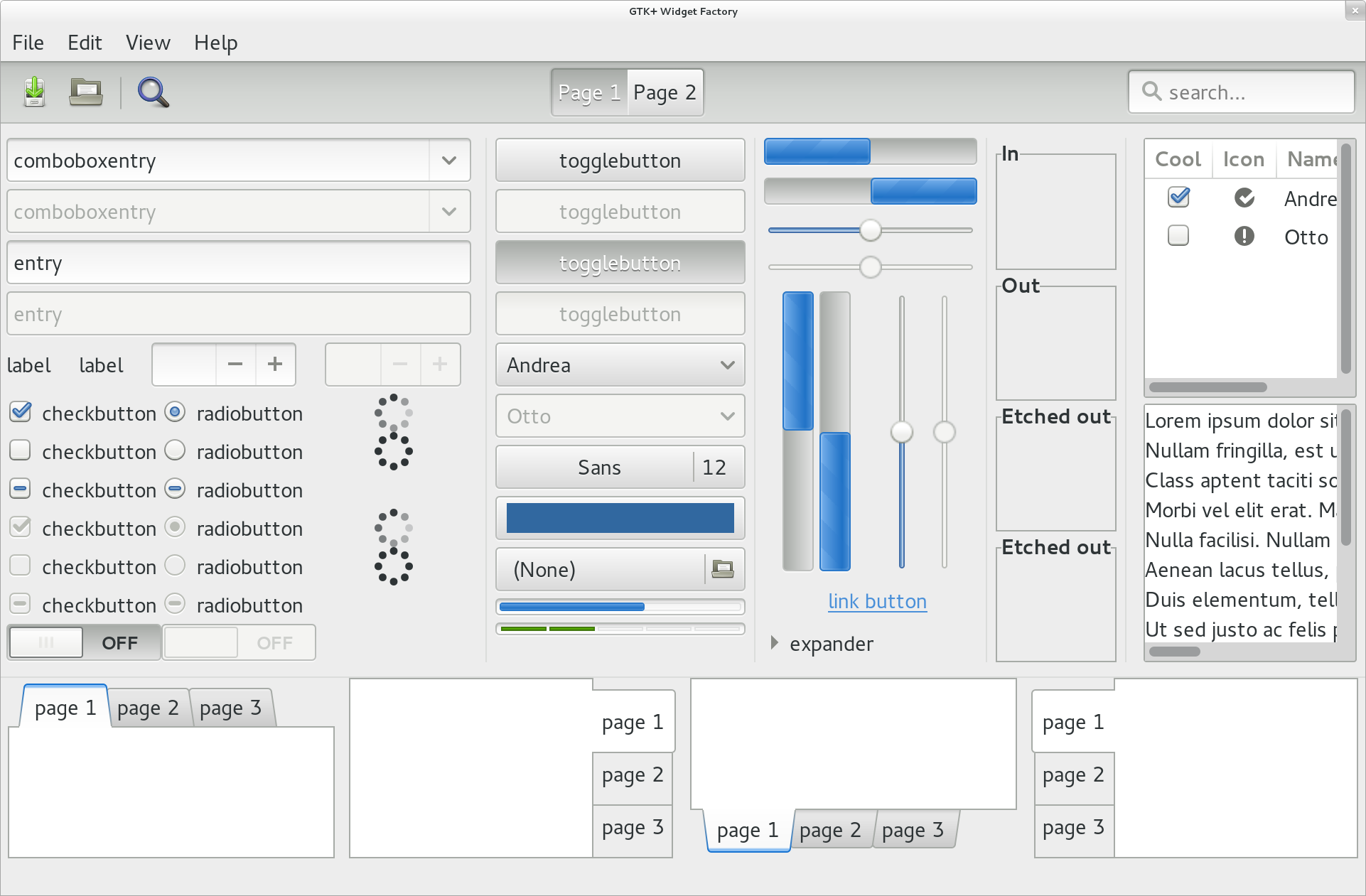
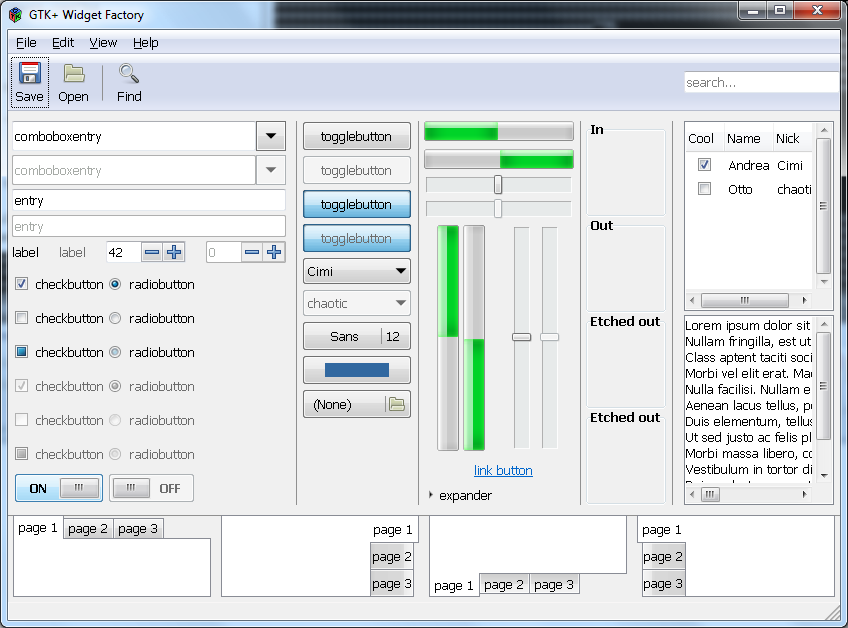
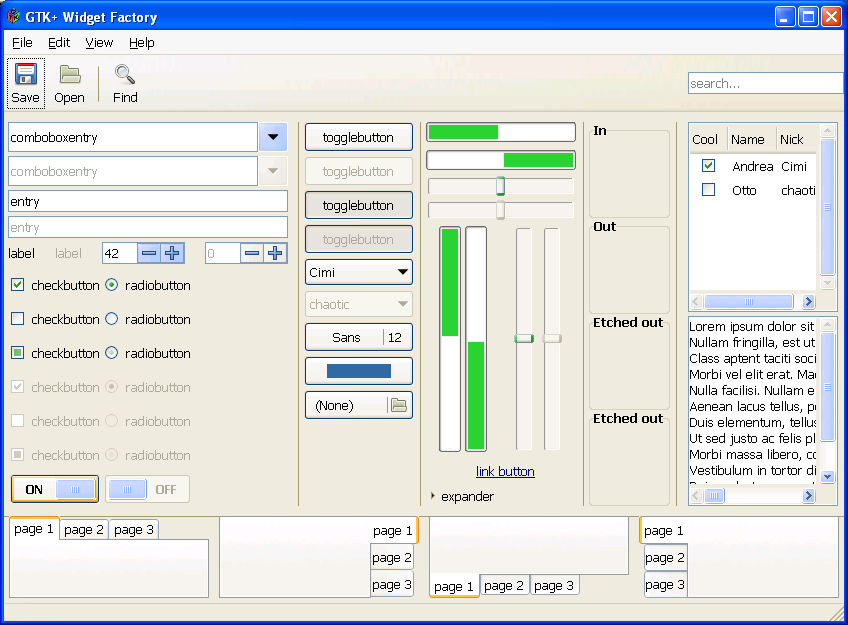
I’ve been doing some experiments recently with ways to build docker images. As a test bed for this I’m building an image with the Gtk+ Broadway backend, and some apps. This will both be useful (have a simple way to show off Broadway) as well as being a complex real-world use case.
I have two goals for the image. First of all, building of custom code has to be repeatable and controlled, Secondly, the produced image should be clean and have a minimal size. In particular, we don’t want any of the build dependencies or intermediate results in any layer in the final docker image.
The approach I’m using involves using a build Dockerfile, which installs all the build tools and the development dependencies. Inside this container I build a set of rpms. Then another Dockerfile creates a runtime image which just installs the necessary runtime rpms from the rpms built in the first container..
However, there is a complication to this. The runtime image is created using a Dockerfile, but there is no way for a Dockerfile to access the files produced from the build container, as volumes don’t work during docker build. We could extract the rpms from the container and use ADD in the dockerfile to insert the files into the container before installing them, but this would create an extra layer in the runtime image that contained the rpms, making it unnecessarily large.
To solve this I made the build container construct a yum repository of all the built rpms, and then when starts lighttp, exporting it. So, by doing:
docker build -t broadway-repo docker run -d -p 9999:80 broadway-repo
I get a yum repository server at port 9999 that can be used by the
second container. Ideally we would want to use
docker links to get access to the build container, but unfortunately links don’t work with docker build. Instead we use a hack in the Makefile to
generate a yum repo file with the host ip address and add that to the
container.
Here is the Dockerfile used for the build container. There are are some interesting things to notice in it:
- Instead of starting by adding all the source files we add them one by one as needed. This allows us to use the caching that docker build does, so that if you change something at the end of the Dockerfile docker will reuse the previously built images all the way up to the first line that has changed.
- We try do do multiple commands in each RUN invocation, chaining them together with &&. This way we can avoid the current limit of 127 layers in a docker image.
- At the end we use createrepo to create the repository and set the default command to run lighttp on the repository at port 80.
- We rebuild all packages in the Gtk+ stack, so there are no X11 dependencies in the final image. Additionally, we strip a bunch of dependencies and use some other tricks to make the rpms themselves a bit smaller.
Here is the Dockerfile for the runtime container. It installs the required rpms, creates a user and sets up an init script and a super-simple panel/launcher app written in javascript. We also use a simple init as pid 1 in the container so that process that die are reaped.
Here is a screenshot of the final results:
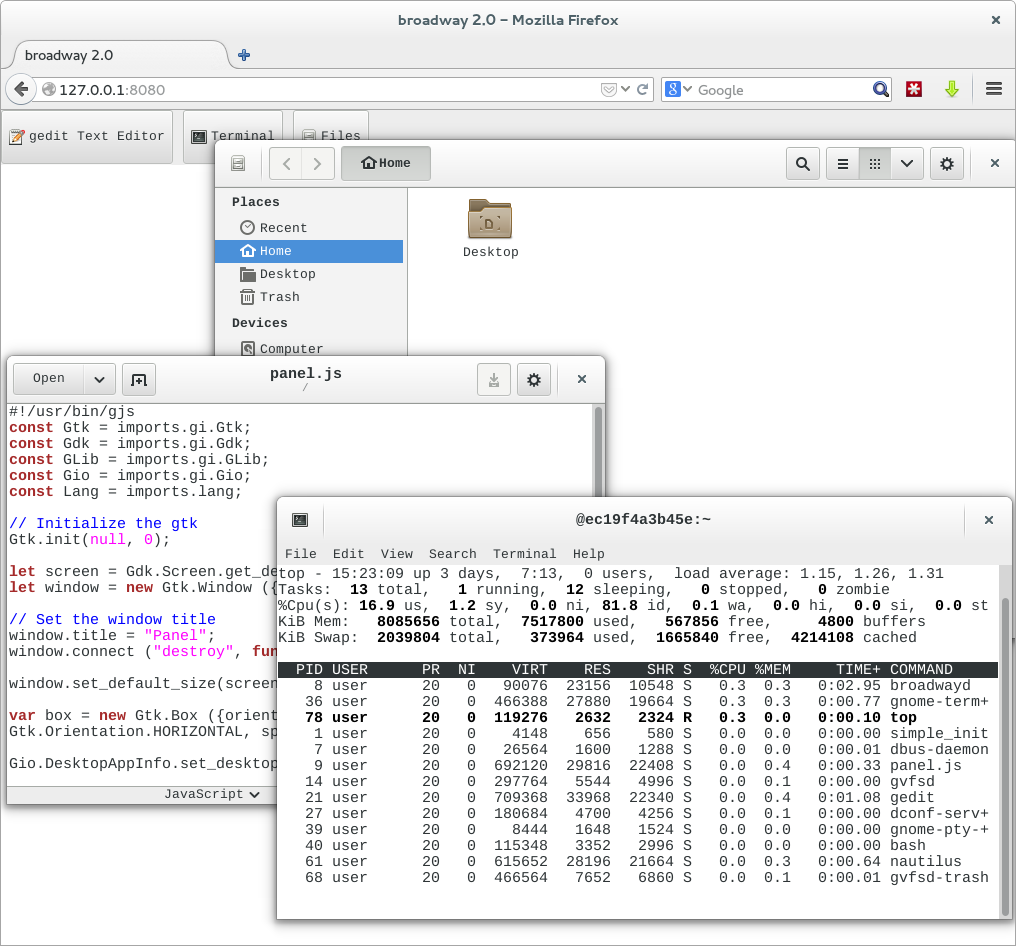
You can try it yourself by running “docker run -d -p 8080:8080 alexl/broadway” and loading http://127.0.0.1:8080 in a browser.