Why is Git for some only the one perfect DVCS and no discussion is possible? From Git is the only DVCS caring about performance incl outdated benchmarks, to the ‘all DVCS’ systems are hard’ and lastly ‘switching VCS systems is easy’. Regarding the latter, who is going to do the conversion? I am fully willing to do Bazaar (perhaps Mercurial.. I’d first would have to investigate that). But Git? Even a ‘am I capable?’ would dismiss me from doing that. Anyway, from following the stuff before the CVS->SVN switch, to fixing loads of things afterwards, switching a VCS system not at all as easy as some make it out to be. Just the under estimation makes me worry.
When I see something which is broken, I cannot just leave it without trying to fix it (aside from lacking time and if I am able to, but ‘able’ is pretty easy with root access). From DNS stuff, to LDAP, accounts process (Mango), SVN repos creation, etc. Although I’d really love if more GNOME sysadmins would be active… anyway, if Git is considered to be the only option and the attitude regarding the ease of switching stays the same, I do not want to have the ability to fix whatever was forgotten or broken.
Month: June 2008
-
Git git git
-
Bzr vs SVN
I wanted to rewrite Mango in Python for a while now, but couldn’t determine which framework to use. Mostly as these frameworks either do way too much or just not enough. Shaunm (and some others in #gnome-hackers) was so nice to convince me that Django was a really good framework. This as I hate frameworks. I want to ignore most of it. My basic needs were CSRF protection (not that I cannot do it myself, but I want to ensure they’ve thought about security), session, something like fastcgi/scgi (the Mango Python stuff needs to run under a different user) and templates etc should be optional.
For the rewrite I’ve decided to use the Bzr mirror. This while still publishing the branch on svn.gnome.org and having the ability to merge both ways (from trunk to django and django to trunk.. at one point). The initial setup for the tools I needed took some time, hopefully this will be resolved soon. This as Mandriva doesn’t have a bzr-svn package yet. I started off with bzr-svn.
Installing bzr-svn is pretty easy (only needed to push to svn.gnome.org, pulling can be done via bzr-mirror):
mkdir -p ~/.bazaar/plugins/ cd ~/.bazaar/plugins bzr branch http://people.samba.org/bzr/jelmer/bzr-svn/bzr.dev/ svn
However, that plugin wants the right Subversion version and 1.5 wasn’t packaged for Mandriva Cooker yet. Compiling Subversion failed initially, as it somehow wanted to link to the installed subversion libraries (this while I did not have the 1.4 svn devel package installed). After I figured that out, there was another issue as the Subversion API changed with 1.5. The workaround for now is to remove the assertion on line 944 in subversion/libsvn_ra/ra_loader.c (or wait for the new bzr-svn plugin).
After getting the tools working, the rest is a bit magical. I followed the GNOME Bazaar instructions and branched Mango trunk locally in a django branch. A
bzr push svn+ssh://svn.gnome.org/mango/trunkwould be enough to push it back to GNOME (you need to specify the push URL once). However, I wanted a branch in SVN. Thepushcommand currently (?) will not create new branches, but there is asvn-pushwhich does.The command I used to create the new ‘upstream’ branch was:
$ bzr svn-push svn+ssh://svn.gnome.org/svn/mango/branches/django
The result from svn-commits-list:
Author: ovitters Date: Sat Jun 21 17:58:09 2008 New Revision: 205 URL: http://svn.gnome.org/viewvc/mango?rev=205&view=rev Log: Try and port the mess to Python using the Django framework. * .bzrignore: Ignore the django directory. * mango/manage.py: Standard Django script to manage the Django project. * mango/models.py: Describes the Database (needs a bit of work). * mango/settings.py: Django settings and the config.xml file. * mango/urls.py: Maps URLs to functions which will be called. * mango/views.py: Handles turning an http request into an http response (application/xml). Added: branches/django/ (props changed) - copied from r204, /trunk/ branches/django/.bzrignore branches/django/mango/ branches/django/mango/manage.py (contents, props changed) branches/django/mango/models.py branches/django/mango/settings.py branches/django/mango/urls.py branches/django/mango/views.py Modified: branches/django/ChangeLog
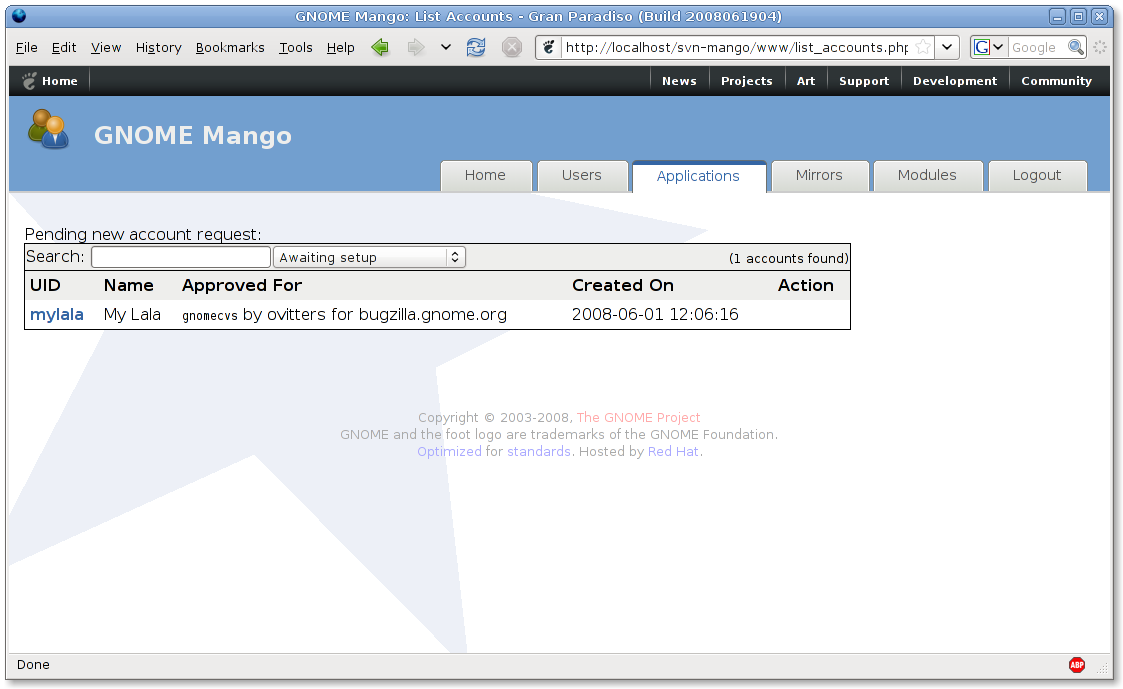
From above email it is clear it copied (branched) the trunk and not just put new files into that Django branch. The resulting test Django installation works pretty similar as the current PHP Mango version:
Oh, and some way too early screenshots:
Current trunk (PHP)
Django branch
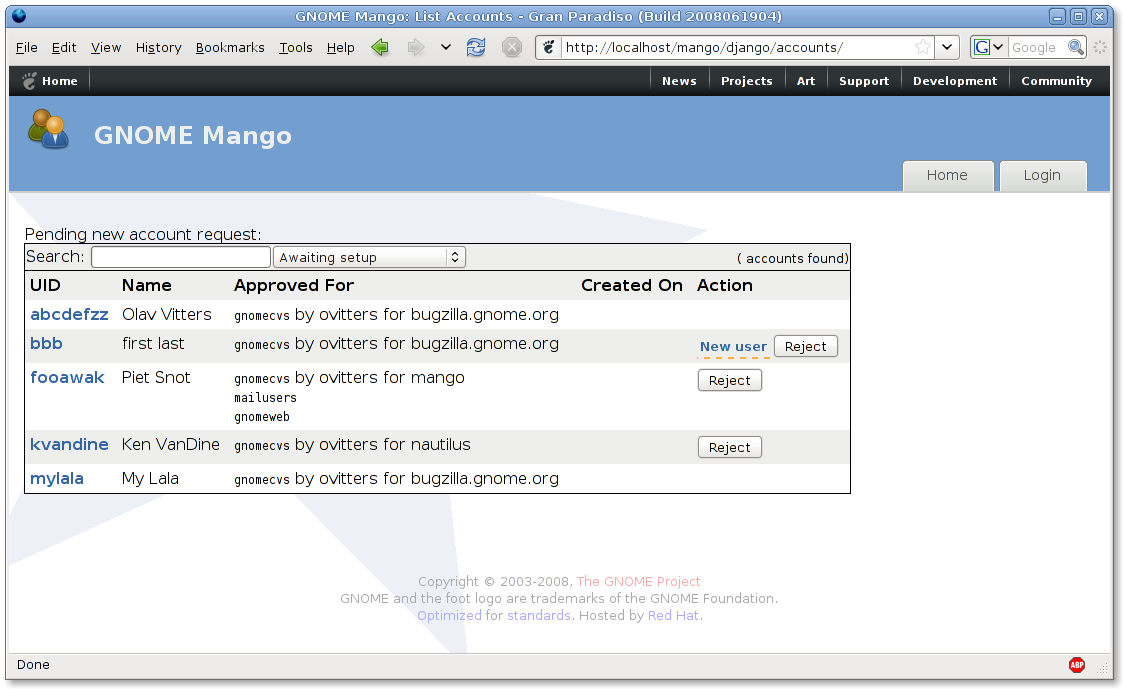
It seems nice, but that is just because I am sharing the XSLT templates. It doesn’t do anything useful yet. For instance, you can clearly see the missing ‘tabs’ and that it doesn’t filter the account requests. A Django LDAP model would also be nice (has a really nice abstraction for models), but was designed with database in mind unfortunately.
-
Subversion 1.5
SUbversion 1.5.0 has been released. I plan to upgrade svn.gnome.org when 1.5.1 is released. See the announcement for full 1.5 details. Things I like are:
- Merge tracking
There are still a few known issues with this. This is why I want to wait until 1.5.1. - Sparse checkouts
- Relative URLs in svn:externals
Allows stuff like/svn/someotherproject/trunk. Avoids thehttpvssvn+ssh. - Memory leak fixed
There was a memory leak which caused problems for bzr-svn and others.
SVN dump+reload script?
I still have to dump/reload all GNOME repositories for the server to use the SVN 1.4 repos format. I’d appreciate if someone has a smart script for this to minimize any downtime (by doing the dump+reload in two stages, first stage dump+reload, 2nd stage disables permissions, dumps+reloads any commits done during the 1st stage, then moves over the 1.4 SVN in place, lastly enabling access again.. this per repository). - Merge tracking
-
Pre-commit hooks
Regarding:
This was more annoying, since there is some script there in s.g.o’s guts that rejects any commit if the repo has an executable.
This is a simplification. Executable files are allowed. There is a pre-commit hook to disallow executable .po files, but that check is only done for .po files added/changed by the commit. It does not check for other .po files. If you see otherwise, please contact svnmaster@gnome.org. Normally developers shouldn’t hit this check btw (only when you’re changing the .po file).
-
Getting stuff into GNOME
Just wanted to respond via the planet on one thing:
It is getting increasingly hard to get new stuff into Gnome, and when someone approaches with something that is slightly controversial huge flamewars erupt. Consider Tracker and Empathy on the desktop-devel list and the recent “incident” on the gtk-devel list.
Ignoring Tracker (too long ago and I’d rather see that standard used instead of deciding between Tracker/Beagle), I don’t think the other examples are good. For one, the gtk-devel list was not regarding getting new stuff into GNOME. Further, the flamewar started because the person was clearly trolling (I had to resort to moderating!). The idea itself did not cause the flamewar.
Empathy has a few issues (not using gnome-keyring and the license). This doesn’t support your statement. If those are fixed, I’d give a +1 during the r-t meeting. From the last time we discussed Empathy, I felt these two items was the only reason Empathy wasn’t accepted.Every release cycle we accept a few things into GNOME. We do ask for a certain quality, e.g. making releases on time and responding to the incoming bugs. Sometimes a proposed module only made one release on time. We do look at future possibilities of a certain module (good enough and shows promise is what I look for), but the basics shouldn’t be ignored.
-
SVN.gnome.org back up
Note that the distribution upgrade of svn.gnome.org has been completed. AFAICS everything is working. If you have issues, please ping me (bkor) or another person with ops in #sysadmin (irc.gnome.org).
PS: I do expect loads of commits now 🙂
-
Using moderated messages to train the bayes classifier
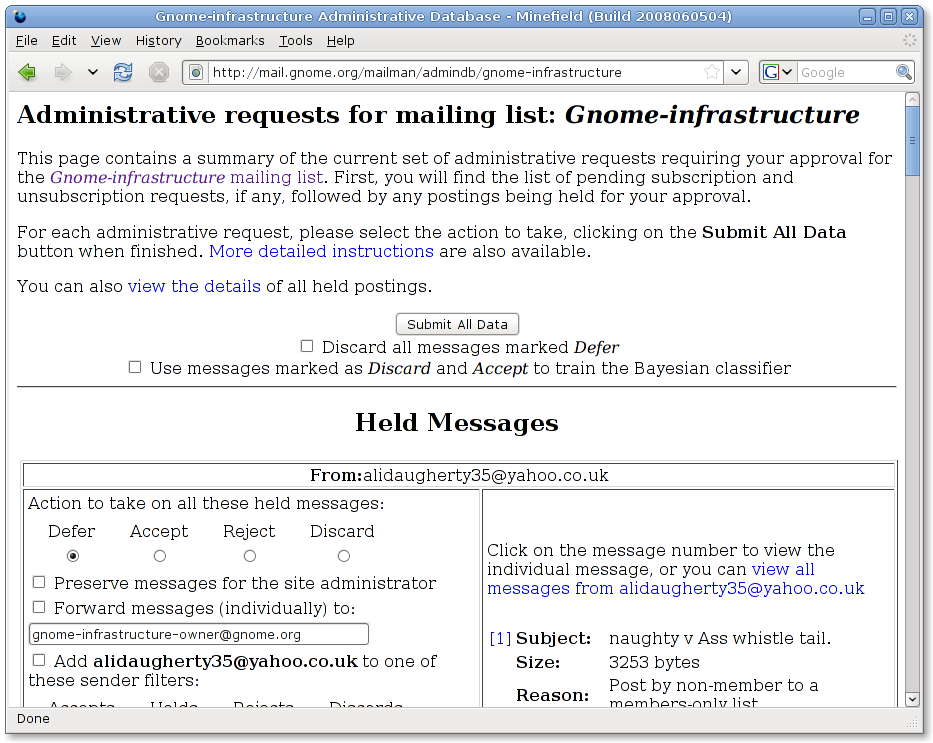
This week I took a look at the moderation queue of a GNOME mailing list. There were loads of messages in it. There is a moderation team who looks at these queues and cleans it up, by discarding the spam and accepting the valid messages. The moderation queue of the mailing list I looked at had lots of similar spam messages over various days. To avoid newer type of spam messages, every day/hour (forgot how often) the Spamassassin rules are updated. These rules includes the ones from Sare. There is a big anti-spam gap in this as the new rules might not catch the things the moderators have classified as spam/ham.
To make the process more intelligent, I’ve added a patch to Mailman to allow moderators to use the discarded/accepted messages to train the Bayes classifier used by Spamassassin. The way it works is hackish, but very simple to implement. I’ve added a patch to our Mailman package which forwards all discarded and accepted messages to a special user. This user has a ~/.procmailrc file to divide these messages in two maildir folders. A script runs via cron to train sa-learn on the spam and ham folders. Sa-learn understands directories, avoiding the need to start sa-learn per spam/ham message.
Hopefully this will result in less spam messages for the moderators to classify.
A screenshot of the new functionality:
-
New mailman version
I’ve upgraded the Mailman version on mail.gnome.org to 2.1.10. In this version I redid the post-only patch. Basically, if the default action for new subscribers is to moderate them (done on e.g. metacity-devel-list), then members subscribed to post-only won’t be automatically accepted. In 2.1.10 Mailman supports something like post-only by default (see NEWS). I found it easier to patch this logic in than to change existing lists and to ensure new lists would get the post-only setting as well.
If you see any problems, please email gnome-sysadmin. Note that yesterdays email backlog wasn’t caused by the Mailman upgrade. I waited until it cleared.
-
SSH public keys
A while ago I added some basic SSH public key checking to Mango. This for two reasons:
- Avoid email back and forth in case of copy/paste error
- To ensure the key is long enough
The key length checking was mostly a hack. I did that by checking if the number of bytes was larger than the number of bytes in a test SSH public key. I never actually knew how many bits the key had. The added benefit was that I figured out how the fingerprint is generated. I always wanted to determine the key length, but couldn’t be bothered. Of course, I could’ve used ssh-keygen, but I don’t like to start another process. It doesn’t actually matter to do a full check. This as the person providing the key wants it to work. We’ll probably get a mail when the public key was broken on purpose. Exception being the key length, as we don’t want too short keys (security issue).
Today I figured out how to determine the key length for RSA and DSA public keys. I’ll start with an example public key (wrapped for readability):
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAP8zwqYE675bpnYzui0pLNd2XyoB+ v4RtlK2QJ6+42w3VWREbDfeeUmvenLBzdcffs602WOuWB1DrbhjEv4CbABH/u O89IMlC4h62wel7BfiQqEq6yKW0B+yqQxIsBQPhu8ID0gXrt0uhlPaHkqD1XR WM9ywr5UP1K51cTPRZu8xQVtpCDMgppa/FwZTKY/+l3HXvu01/NAaNGMPOD3y neIturzKi3x4f5Id65V1KD70B5YiCiJxFSevOcPx3yYYy+NQN52EBGLf76a78 1S2MiPcHxhoQtG8EPfAhWN3MmOnEd4iuy2IzHdyAK+LCp5Qtyy3mbKTBKSKQb vrsm8jrjE= olav@bkor.dhs.org
The ssh-rsa is the key type; ssh-rsa for RSA and ssh-dss for DSA. After that there is a space and then the data (easily recognizable as base64 encoded). After the base64 data there is another space followed by a comment (contents doesn’t matter for SSH, you can change it with a text editor). The fingerprint of a key is nothing more than the MD5 hash of the base64 decoded data. The md5 hash of the example public key is 6f8c83c826ee51535a813756ff1bc9b5. The ssh-keygen program shows this with colons.
If you’ve compared a few public SSH keys, you probably noticed that the start of the base64 data is always the same (for the same key type). This is because the data itself again contains the key type (‘ssh-rsa’). The data is encoded using a big endian number (4 bytes) providing the number of bytes of the string that follows. A hex editor will show 00 00 00 07 for the first 4 bytes. After these 4 bytes follows either ‘ssh-rsa’ or ‘ssh-dsa’. The rest of the data is key type specific.
For RSA, the key type is followed by 2 strings encoded using the same method. These strings actually represent ‘bignum’s. However, I don’t care about that. For DSA, 4 strings (bignums) follow after the key type, also encoded using the same method. For RSA you’ll want the 2nd bignum. For DSA the 1st bignum.When you have such a bignum you’re very close to determine the key length. It is mostly just determining the number of bits needed for the bignum. You could do this by determining the number of bytes used by the bignum and multiplying it by 8. However, you have to deduct a few bits. This as the first byte causes the bignum to use more bits than it actually needs. For example, if the following are the first two bytes (shown as binary) out of the total 255 bytes used for the bignum:
00110011 11000010
You’ll note that the first two 0’s aren’t actually needed. So instead of calculating 255*8 (2040), you should subtract it by 2 bits. Resulting in a key length of 2038. This is what ssh-keygen will give you if you try the example public ssh keyfile shown above (make sure to unwrap the lines and remove the spaces in the base64 encoded data). Looking back, it actually is pretty easy.
Oh, and the reason why I want to know the exact key length is to add a check against blacklisted keys. For this I need to know the actual length of a key. I figured above out partly myself, partly by reading python-paramiko source (unfortunately I overlooked the public key reading part) and partly by trying to understand the openssh code. Running ssh-keygen would’ve been loads easier, but IMO nasty (especially when someone has multiple keys) and also not as interesting. Further, if you use Python instead of PHP (blergh!), just use python-paramiko.