Entries Tagged 'General' ↓
January 27th, 2021 — Audio, General
The main goal of liquidsfz is to implement a library that supports playing .sfz files and is easy to integrate into other projects. We also provide a JACK client and a LV2 plugin.
A new release of liquidsfz is now available (under LGPL2.1+):
This release adds support for LFOs (both SFZ1 and SFZ2 style). Typical use cases for LFOs are vibrato and tremolo, and the set of opcodes we now support should be enough for many .sfz files which need these features.
To further improve compatibility with existing .sfz files, the preprocessor (#include/#define handling) was improved and support for curve sections and the related opcodes was added.
The full list of changes is in the NEWS files.
January 7th, 2021 — Audio, General
The main goal of liquidsfz is to implement a library that supports playing .sfz files and is easy to integrate into other projects. We also provide a JACK client and a LV2 plugin.
A new release of liquidsfz is now available (under LGPL2.1+):
This release adds SFZ style filters, which means fil_type, cutoff, resonance and a lot of other new opcodes are now supported. All SFZ1 filter types are implemented, and a few SFZ2 filter types (lpf_4p, lpf_6p, hpf_4p, hpf_6p), as well as a filter envelope.
The other bigger change is that the LV2 plugin now reports the supported controllers, the names of the controllers, the names of key switches and the names of the keys to the host using a midnam file. For Ardour6 for instance this means that the names of the keys are shown, as well as the names of the supported controllers, which makes sfzs with exported CCs a lot more usable.
The hydrogen loader also passes this information, so for instance you will see that note 36 is called “Kick” in the loaded hydrogen drumkit.
The full list of changes is in the NEWS files.
October 19th, 2020 — Audio, General
The main goal of liquidsfz is to implement a library that supports playing .sfz files and is easy to integrate into other projects. We also provide a JACK client and a LV2 plugin.
A new release of liquidsfz is now available (under LGPL2.1+):
New opcodes, offset / offset_random / offset_ccN / offset_onccN were added, in order to be able to properly support more .sfz files.
Hydrogen drumkits can now be loaded transparently by loading the drumkit.xml file. We try to map hydrogen features to sfz features. For many drumkits liquidsfz should replay the drumkit identically like hydrogen would. But not all hydrogen features are mapped (for instance hydrogens randomized sample selection is not, so drumkits that use it don’t sound entierly correct). Fortunately most drumkits either sound great or at least usable even without all features hydrogen itself has.
The liquidsfz JACK client is now interactive, so users can type commands like noteon 0 60 127 which would create a note on event for note 60. I use this very heavily for debugging, since using a full DAW like Ardour is quite slow compared to typing a few commands or making a script which can be executed using source somefile as liquidsfz command.
I’d like to summarize everything else as: many small improvements have been made, a few of them requested from the community. This includes better API documentation and a few API additions, a global sample cache to optimize memory usage in some situations, support for shared libraries and lots of other fixes, which should make everything a little bit better for many users.
The full list of changes is in the NEWS files.
September 24th, 2020 — Audio, General
A new version, SpectMorph 0.5.2 is available at www.spectmorph.org.
SpectMorph (LV2/VST plugin, JACK) is able to morph between samples of musical instruments. A standard set of instruments is shipped with SpectMorph, and an instrument editor is available to create user defined instruments from user samples.
With this release, the SpectMorph LFO can be synchronized with the song tempo. This allows morphing frequency to be specified as note length (for instance quarter notes). As a related new feature, the playback speed of samples (user defined instruments) can be controlled using automation/LFOs, so it is possible to time-stretch a sample as needed to be synchronized to the song tempo. To see how to use the new possibilities, I recommend these tutorials:
A full list of all changes can be found here.
And finally here is a new piece of music made with SpectMorph:
April 18th, 2020 — Audio, General
In 2018, a company I was working for asked me to develop an open source solution for audio watermarking. At that point, we didn’t even find a single open source software that would be close to being usable in production.
As a result, today I am making the source code of “audiowmark” publically available under GNU GPL3 or later. It has many features, it is robust, fast, secure and of course we believe that the watermark is not audible for most users.
More infos, source code and audio demos are available on the audiowmark web page.
February 13th, 2020 — Audio, General
A new version, SpectMorph 0.5.1 is available at www.spectmorph.org. SpectMorph is a VST/LV2/JACK synthesis engine which is based on the idea of analyzing audio samples and combining them using morphing.
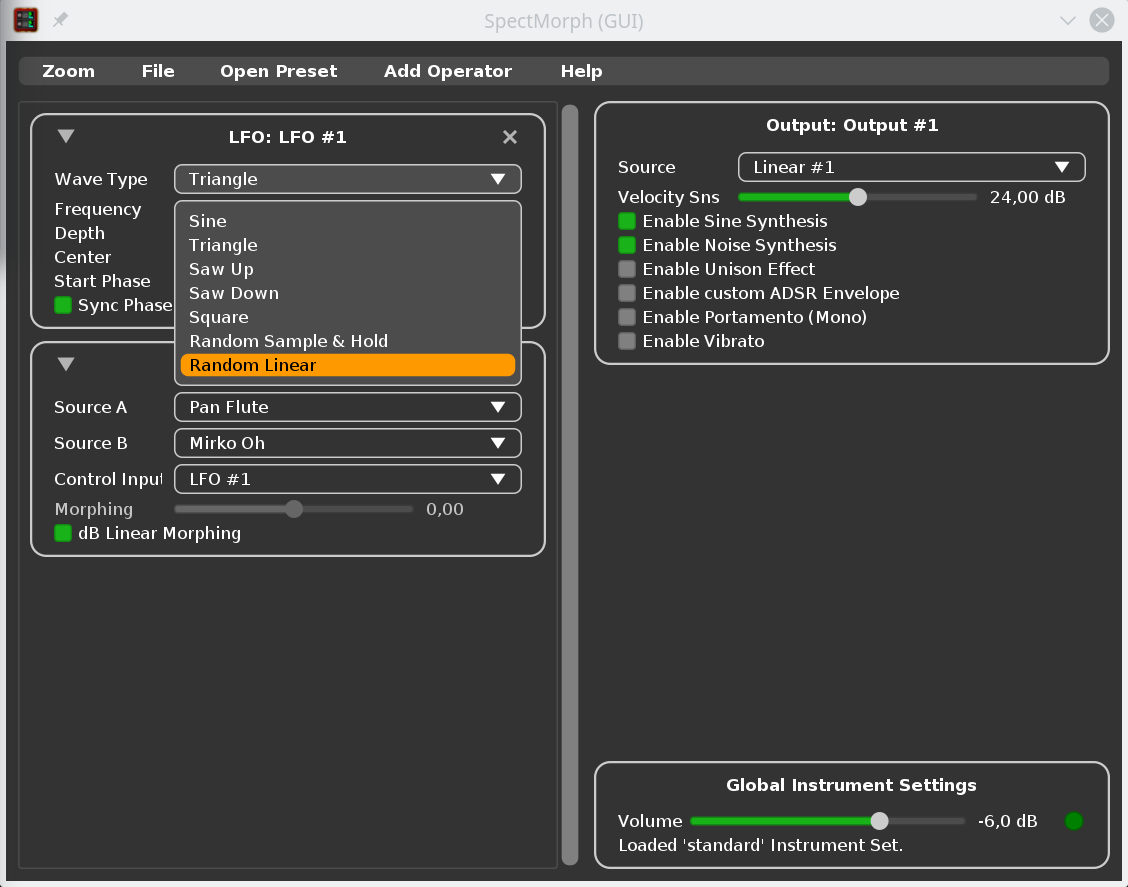
As you can see in the screenshot, there are a few new LFO wave forms available (saw, square and random).
On Windows and macOS, from the beginning there was no need for users to compile anything. You could just download SpectMorph, install it and use it. On Linux, we provide packages for Ubuntu and there are also distribution packages for Arch Linux. But this means that as a user, if you use a different linux distribution, you had to build SpectMorph from source. Which may be too difficult for the average user.
This release improves the situation: there are now Generic 64bit Linux binaries available, which provide the VST/LV2 plugin (statically linked). So these binaries should run on just about any linux. Note that this is a new feature, so please let me know if the generic binaries don’t work for you.
This release also contains a few fixes and the detailed list of changes can be found here.
Finally let me recommend two youtube videos (if you haven’t watched these yet):
July 22nd, 2019 — Audio, General
A new version of SpectMorph, my audio morphing software, is now available on www.spectmorph.org. SpectMorph is a VST/LV2/JACK synthesis engine which is based on the idea of analyzing audio samples and combining them using morphing.
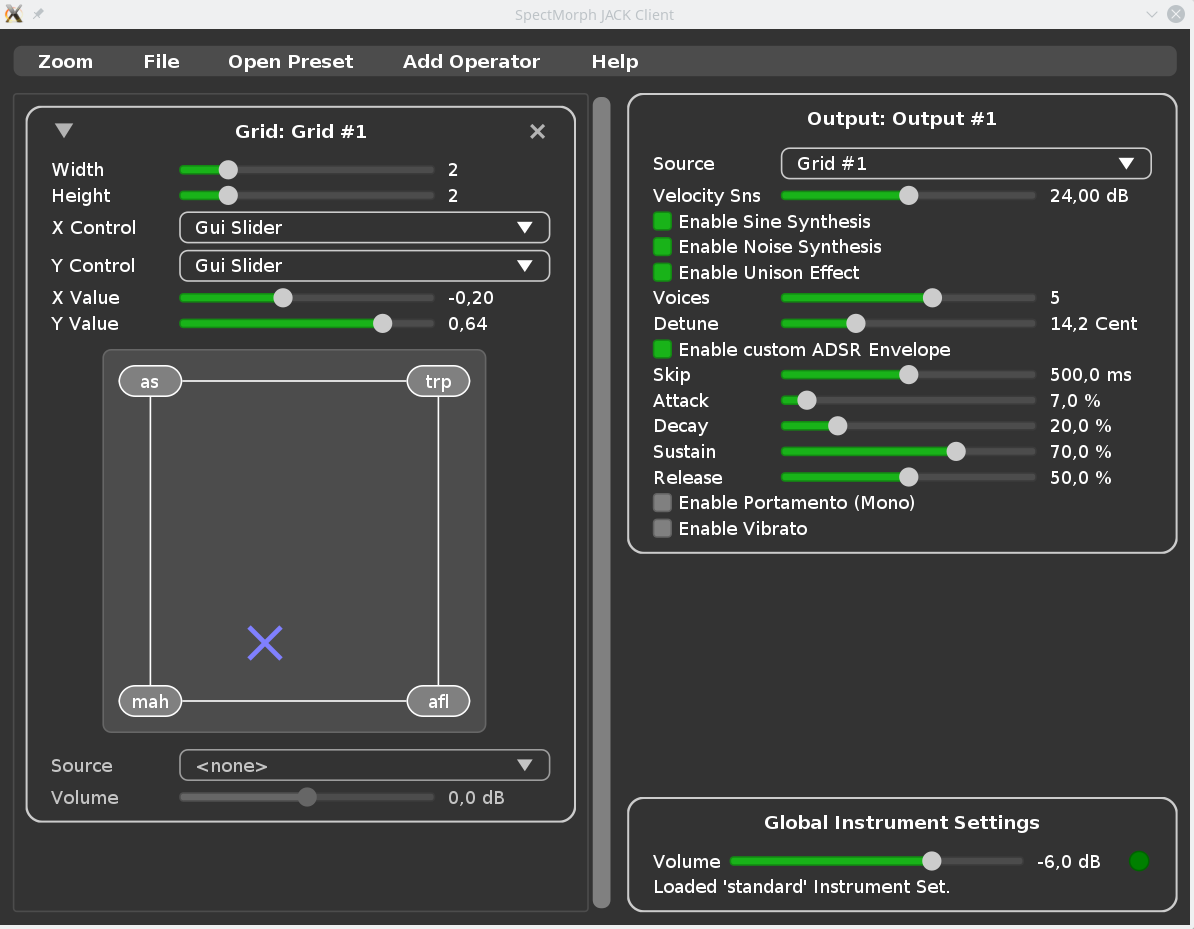
SpectMorph could always create sounds by morphing between the musical instruments bundled with SpectMorph. With this release, a new graphical instrument editor was added, which allows loading custom samples. So SpectMorph users can now create user defined instruments and morph between them.
Here is a screencast which demonstrates how to do it.
Besides this big change, the releases contains a few smaller improvements. A detailed list of changes is available here.
Finally, here is some new music made with SpectMorph:
August 30th, 2018 — Audio, General
A new version of SpectMorph, my audio morphing software, is now available on www.spectmorph.org. Besides Linux and Windows, it now also runs on macOS (>= 10.9).
In order to simplify the installation under Linux, the required instrument data for SpectMorph no longer needs to be downloaded seperately. Instead, the source tarball and Ubuntu packages include the instrument data (the other platforms already do this by default, too).
We added recordings of Claudia – a female opera singer – as new instrument (“Claudia Ah”, “Claudia Oh”, “Claudia Ih”). A few improvements to the instrument building tools were made along the way. To get good results from Claudia’s recordings, we had to add an algorithm that systematically reduces vibrato automatically.
As always, a few minor problems were fixed, for instance the VST plugin automation now works properly with Cubase. A detailed list of changes is available here.
The video for my presentation at Linux Audio Conf 2018 about how SpectMorph implements morphing is now available.
Finally, a new piece of music created by Sven and me with SpectMorph has been completed: Clicking.
August 21st, 2018 — Audio, General
Beast 0.12 is available from the Beast Homepage. Beast is an Free and Open Source Linux DAW for composing music with the integrated modular synthesis environment. A detailed list of changes is available in the Release Notes.
From the announce mail on the BEAST List:
This release removes the Rapicorn dependency as well as the runtime dependency on CPython. To achieve that, a number of utilities from Rapicorn has to be integrated, which has made the code base a fair bit larger:
651 files changed, 75581 insertions(+), 44596 deletions(-)
Most notably, this is the first release that installs the new ebeast UI. Tracks, piano rolls and dB meters are already displayed, but not much beyond that as it’s still in pre-alpha stage. However it’s a good showcase for our future UI direction, you can start it and take a quick look with:
$prefix/beast-0-12/bin/ebeast
April 10th, 2018 — Audio, General
A new version of SpectMorph, my audio morphing software is now available on www.spectmorph.org.
One main feature is that besides providing VST, LV2, JACK and BEAST support on Linux, this version is the first version that also provides a VST plugin for (64-bit) Windows.
To make the VST plugin portable to Windows, the plugin UI now uses the pugl library (with GL + Cairo) instead of Qt5. This should also allow supporting macOS in the future.
Since the whole plugin UI was reimplemented, a new design is used, and many small improvements were made; the UI is also ready for high(er) DPI displays, everything can be scaled using a global zoom factor. Below is a screenshot of the new UI:
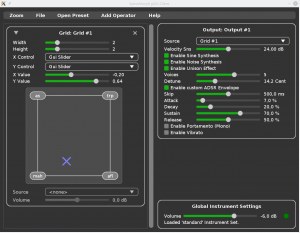
Other changes are:
- A new non-linear mapping from midi velocities to volumes was implemented
- New instrument: French Horn
- Improved tools for building custom instruments
- LPC/LSF support removed