Hi all, hope you’ve spent a pleasant holiday season.
As promised, here is another post describing what new tricks we’ve been teaching EDS (Evolution Data Server) this year at Openismus.
Before I go through all the details, a little context is in order. Last year Mathias created a nifty benchmark tool for EDS allowing us to track performance improvements and regressions of the Evolution Data Server across releases and branches. Mathias, with his prior experience and knowledge of EDS was able to make some educated guesses on where we could save some milliseconds, all in the interest of providing an EDS that is stable/reliable in terms of performance and also useful in a variety of platforms and scenarios (not only as the backend of the Evolution Mail client on Desktops).
We’ve come a long way on this, so first let me describe the major changes that we’ve made and then I’ll move on to show you the results.
Removing Berkeley DB
Historically, Evolution’s local addressbook used Berkeley DB to store VCards for all contacts. Over time some optimizations were made, originally an in-memory “summary” was maintained holding some of the contact data in order to speed up queries to the addressbook. This was eventually replaced with an SQLite implementation of the quick search “summary” data. In the end that left us with a two step query for fetching contacts from the addressbook; an initial query to the SQLite to find any UID which match the query terms and then another query to the BDB fetching the actual VCard data for that contact.
Removing the BDB implementation and storing all contact data in the SQLite instead naturally makes queries faster, not to mention there is considerably less flash wear as we only have one DB persisting contact data now instead of two. Additionally we’ve also observed that the old BDB code fails (crashes, even) with an out of memory condition in some cases such as deleting more than 6400 contacts at once, this is all handled much cleaner using SQLite exclusively.
This has landed in EDS’s git master a couple of months ago and should be available in the next release.
Configurable Summary Fields
Summary Fields in EDS refer to the VCard fields for a given addressbook which should be elected for fast results. They are stored separately in an SQLite table so that contacts can be queried without parsing the complete contact VCard data for every contact.
This list has always been hard coded and tailored to the needs of the Evolution Mail client (the list basically consisted of the contact name fields plus a hand full of email fields which Evolution is accustomed to using). This would of course be appropriate for an email client but falls short for applications that have different needs such as hand phones, which require extremely fast results for queries by phone number.
So we’ve now introduced a set of APIs which allow configuration of the summary fields of a given addressbook at addressbook creation time. This allows us to choose which fields are stored in the summary and which of those fields should be indexed for extra fast retrieval.
As a side effect of this, we now also support multi valued VCard attributes to be stored in the summary (i.e. list of emails or list of addresses).
This has also landed in EDS master some time ago and will be available in the next EDS stable release.
Direct Read Access
One of the more intrusive changes is the Direct Read Access mode. Mathias foresaw that we would gain significant performance simply by delivering query results directly to the client instead of squishing them into the socket and pushing them arduously through the D-Bus byte by byte (or probably 8192 bytes at a time…). I have to admit that I was a little sceptical about this change but after benchmarking the direct read access approach I was able to notice a serious performance gain.
Our fastest queries using the previously described configurable summary fields return in roughly 4-7 milliseconds.
The same queries in Direct Read Access mode are quite consistently 0.2 or 0.3 milliseconds.
In other words; for the simplest queries where the EDS server can fetch the results very fast, we waste the grand majority of our time serializing/deserializing VCard data and tinkering on the D-Bus socket.
This has not yet landed in EDS master, so I’ll keep you posted 😉
How fast can I get my contacts ?
In conclusion, let’s go over the results of our benchmarks and compare.
First a few details regarding the results we’re looking at:
- EDS 3.6 – This is stable EDS 3.6.2 without any of the above modifications, it’s important to note that this version still uses Berkeley DB as well as SQLite to store contacts. Furthermore, the stock 3.6.2 does not take advantage of SQLite indexes.
- Custom – Built from our EDS 3.6 based work branch (called ‘openismus-work’) this build has Berkeley DB removed and configures the summary with a custom summary configuration.
- Custom DRA – Built from our EDS 3.6 based work branch; this build additionally enables Direct Read Access, using the same configuration for summary fields as the ‘Custom’ build uses.
For both ‘Custom’ and ‘Custom DRA’, the customized summary is configured as follows:
- Full Name: In the summary and indexed for prefix searches
- Given Name: In the summary and indexed for prefix searches
- Family Name: In the summary and indexed for prefix searches
- Telephone Number: In the summary and indexed for prefix & suffix searches
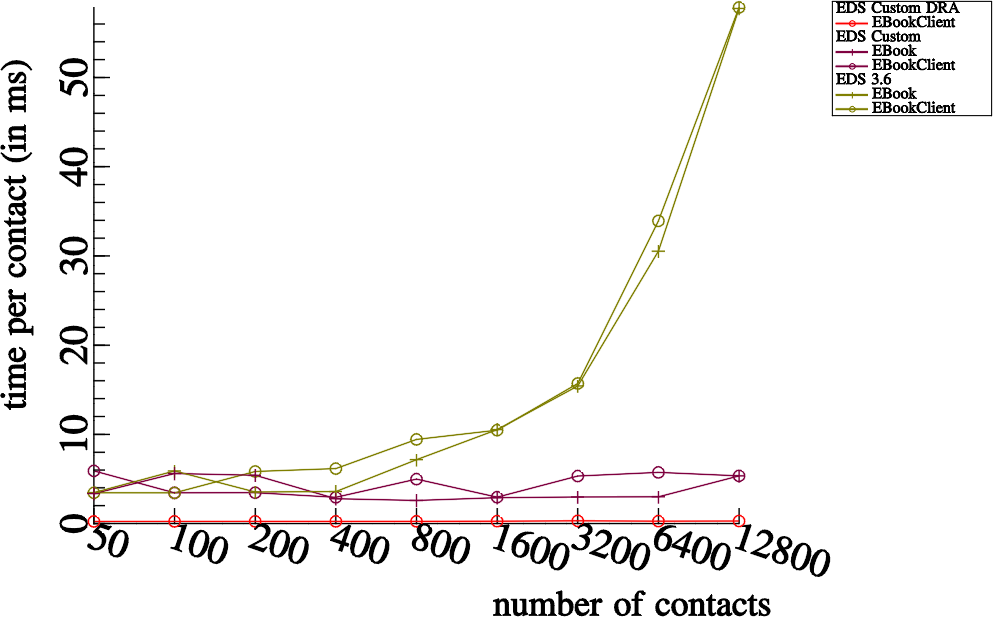
In EDS 3.6 stable, the full name attribute is indeed stored in the SQLite summary. Notice that for small addressbooks (less than 200 contacts) the results are similar to EDS Custom. However with the customized summary fields we’ve also ensured that the SQLite indexes are getting used properly; this is what ensures the performance doesn’t degrade too much with larger addressbooks.
The red (DRA) line is EDS doing the same thing but avoiding the arduous tinkering with D-Bus messaging.
Phone Numbers
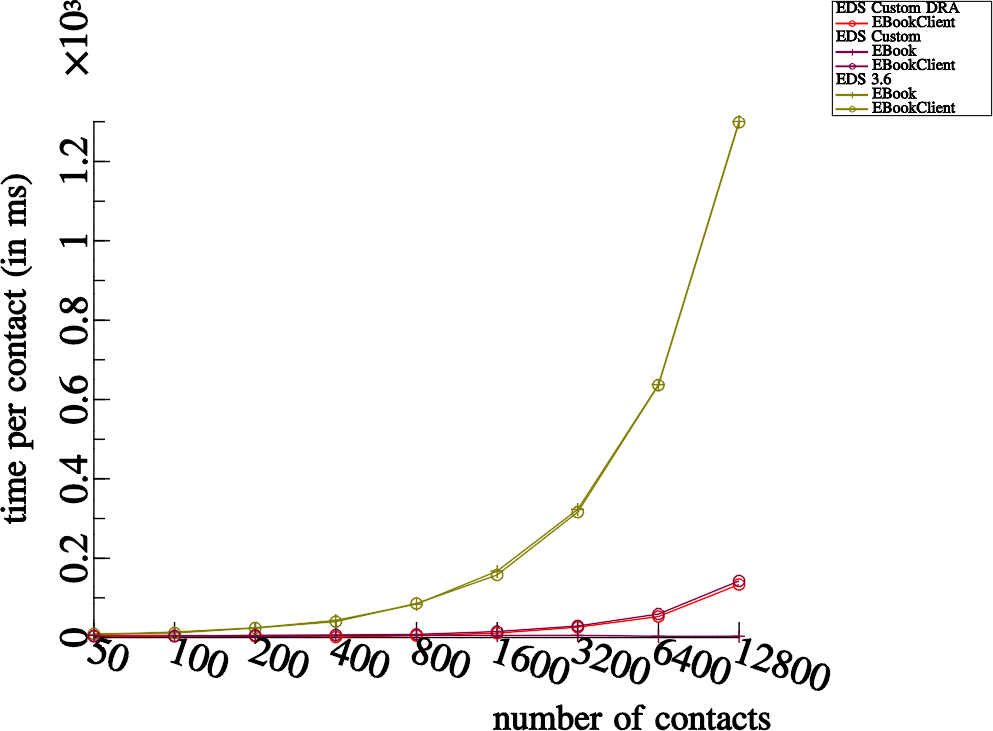
Since we’ve configured EDS to optimize the phone number field of a given contact for prefix & suffix searches, we can now use phone number queries at reliable speed. In other words you can again use EDS on your hand phone to implement your contacts database and kittens wont be sacrificed.
The reason why this takes an extremely long time with EDS 3.6 is that the contacts have no quick search information ready at hand, this means we must iterate through all of the contacts in the Berkeley DB and parse the VCards for each, extract all of the phone numbers and compare one by one.
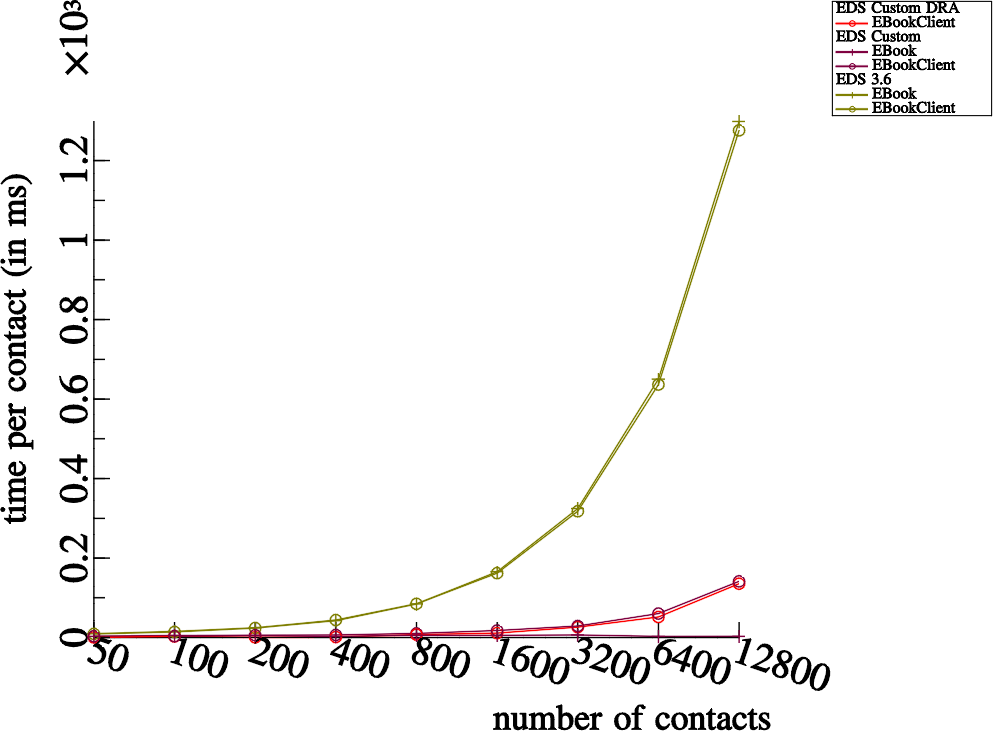
Since we optimized for suffix searches, we get similar results for a suffix search:
Memory Usage
We also have in place some monitoring of memory usage:

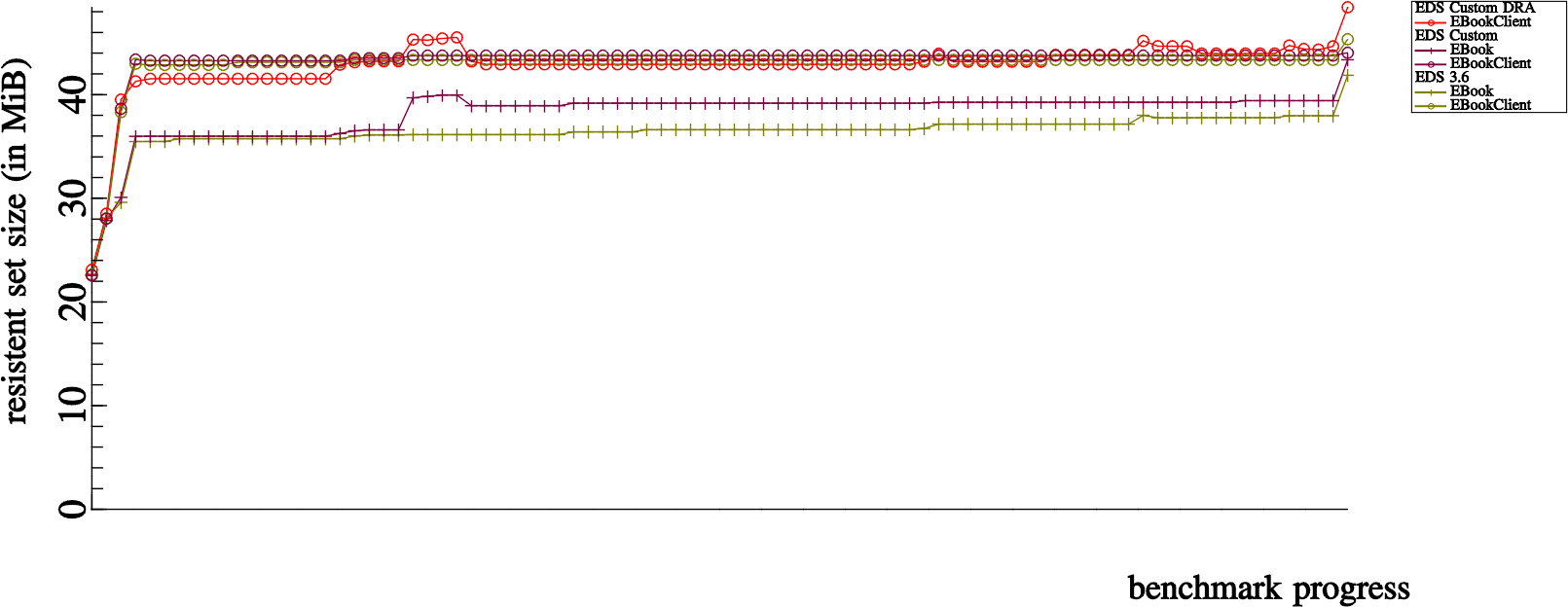
These are basically just memory usage snapshots taken over the course that the benchmarks run.
The “Custom” setup takes slightly more memory to run than EDS 3.6, this is presumably because we maintain more indexes with the SQLite version. Unsurprisingly, the Direct Read Access mode takes significantly more memory; this is because the direct read access mode uses two SQLite connections (one for the server and one for the client to make direct read calls).
This concludes this Tuesday’s episode of “Getting your contacts Right Now!”
Stay Tuned 😉
I dun really get most of that, but those graphs seem to speak for themselves. ^.^
Thanks for finding the time to write this all down! One minor nitpick: the diagrams are too large, could you perhaps just include thumbnails/scale them?
Great stuff Tristan!
It’s interesting to see EDS initial design and performance pitfalls were similar to Tracker’s, and that you’re applying similar solutions :). On < 0.7 there, there was a Tokio Cabinet holding the rowids of another SQLITE database that stored the indexed data. Nowadays Tracker uses sqlite exclusively and libtracker-client will use the direct database connection for readonly queries by default.
Hi!
Will there be a possibility to update from an earlier version using BDB to SQLite only version?
@xurfa: Yes of course, there is a migration routine in place for exactly that 🙂
@Carlos: Quite, I should mention that at least the direct read access technique was inspired directly from Tracker.