About ApacheCon
This was my first real conference since worldwide panic spread a few years ago, and it is hard to overstate how exciting it was to be in New Orleans and meet real people again, especially since this was an opportunity to meet the Apache contributor base for the first time.
The conference took place at the Sheraton hotel on Canal street, where we had access to a discounted rate for rooms, a large room where everyone could attend the keynotes with a coffee/snack area outside where booths were also located, and on the 8th floor we had 6 small conference rooms for the various tracks.
The talks I attended were refreshingly outside of my comfort zone, such as big data workflow scheduling with DolphinScheduler, a talk about Apache Toree which is a Jupyter Kernel for Scala / Apache Spark (a framework for data analysis and visualization) and my personal favorite was a talk about the SDAP (Science Data Analytics Platform) which is a platform built to support Earth Science use cases, this talk explored some of the implementation details and use cases of an engine which can be used to search efficiently through Earth related data (collected from satellites and various sensors) which can be freely obtained from NASA. In case you’re wondering, unfortunately actually leveraging this data requires that you download and house the (immense) data which you intend to analyze, either in the elastic cloud or on-premise clusters.
In the evenings, the foundation prepared a speakers reception on Tuesday evening and then a general attendee reception on Wednesday evening, and the Gradle folks also organized a bonus event, this provided a nice balance for socializing with new people with the opportunity to explore the music scene in New Orleans.

Overall this felt very much like a GUADEC inasmuch as it is a small(ish) tightly knit community, leaving us with much quality time for networking and bonding with new fellow hackers.
BuildStream talk
On Tuesday I gave my BuildStream presentation, which was an introduction to BuildStream, along with a problem statement about working with build systems like Maven which love to download dependencies from the internet at build time. This bore some fruit as I was able to discuss the problem at length with people more familiar with java/mvn later on over dinner.
But… all of that is not the point of this blog post.
The point is that directly after my talk, Sander (a long time contributor and stakeholder) and I scurried off into a corner and finally pounded out a piece of code we had been envisioning for years.
BuildStream / Bazel vision
Good integration with Bazel has always been an important goal for us especially since we got involved with the remote execution space and as such are using the same remote execution APIs (or REAPI).
While BuildStream generally excels in build correctness and robustness, Bazel is the state of the art in build optimization. Bazel achieves this by maximizing parallelism of discrete compilation units, coupled with caching the results of these fine grained compilation units. Of course this requires that a project adopt/support Bazel as a build system, similar to how a project may support being built with cmake or autotools.
Our perspective has been that, and I hope I’m being fair:
- Bazel requires significant configuration and setup, from the perspective of one who just wants to download a project and build it for the first time.
- Bazel will build against your system toolchain by default, but provides some features for executing build actions inside containers, which is slow due to spawning separate containers for each action, and is still considered an experimental feature.
- BuildStream should be able to provide a safe harness for running Bazel without too much worries about configuration of build environments as well as provide strict control of what dependencies (toolchain) Bazel can see.
- A marriage of both tools in this manner should provide a powerful and reliable setup for organizations which are concerned with:
- Building large mono repos with Bazel
- Building the base toolchain/runtime and operating system on which their large Bazel built code bases are intended to be built with and run
While running Bazel inside BuildStream has always been possible and does ensure determinism of all build inputs (including Bazel itself), this has never been attractive since Bazel would not have access to remote execution features and more importantly it would not have access to the CAS where all of the discrete compilation units are cached.
And this is the crux of the issue; in order to have a performant solution for running Bazel in BuildStream, we need to have the option for tools in the sandbox to have access to some services, such as the CAS service and remote execution services.
And so this leads me to our proof of concept.
BuildStream / recc proof of concept
At the conference we initially tried this with Bazel, but I was unable to successfully configure Bazel to enable remote caching, so we went for an equivalent test using the Remote Execution Caching Compiler (recc). Recc is essentially like ccache, but uses the CAS service for caching compilation results.
After some initial brainstorming, some hacking, and some advice from Jürg, we were able to come up with this one line patch all in a matter of hours.
As visualized in the following approximate diagram, the patch for now simply unconditionally exposes a unix domain socket at a well known location in the build environment, allowing tooling in the sandbox to have access to the CAS service.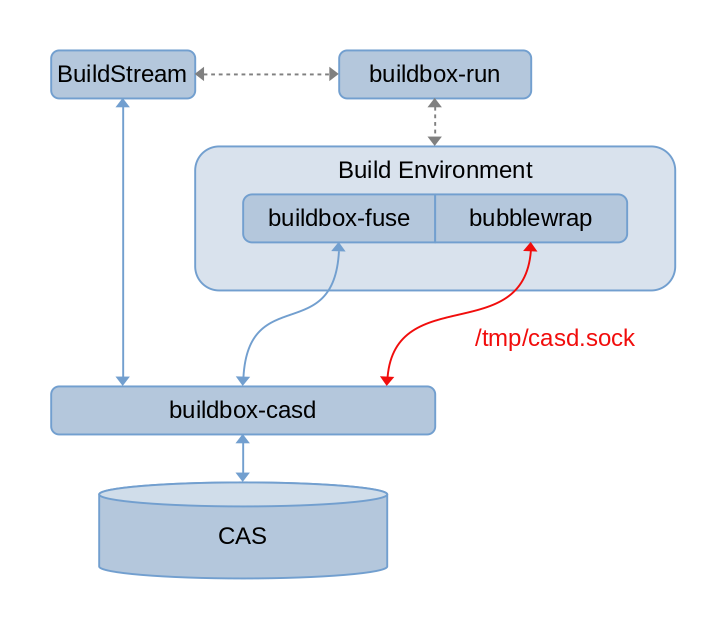
Asides from the simple patch, we generated the buildstream-recc-demo repository to showcase recc in action. The configuration for this in the sandbox is dead simple, as evidenced by the example.bst, building the example simply results in running the following command twice:
recc g++ -I. -c -o hello-time.o hello-time.cc
One can observe evidence that this is working by observing the buildstream logs of the element, and indeed the second compile (or subsequent compiles) results in the expected cache hit.
By itself, using recc in this context to build large source bases like WebKit should provide significant performance benefits, especially if the cache results can be pushed to a central / shared CAS and shared with peers.
Next steps
In order to bring this proof of concept to fruition, we’ll have to consider topics such as:
- How to achieve the same thing in a remote execution context
- Possibly this needs to be a feature for a remote worker to implement, and as such at first, BuildStream would probably only support the BuildGrid remote execution service implementation for this feature
- Consider the logistics of sharing cached data with peers using remote CAS services
- Currently this demo gives access to the local CAS service
- Consider possible side effects when multiple different projects are using the same CAS, and whether we need to delegate any trust to the tools we run in our sandboxes:
- Do tools like recc or bazel consider the entire build environment digest when composing the actions used to index build results / cache hits ?
- If not, could these tools be extended to be informed of a digest which uniquely identifies the build environment ?
- Could BuildStream or BuildBox act as a middle man in this transaction, such that we could automatically augment the actions used to index cached data to include a unique digest of the build environment ?
The overarching story here is of course more work than our one line patch, but put in perspective it is not an immense amount of work. We’re hoping that our proof of concept is enough to rekindle the interest required to actually push us over the line here.
In closing
To summarize, I think it was a great to meet with a completely different community at ApacheCon and I would recommend it to anyone involved in FLOSS to diversify the projects and conferences they are involved in, as a learning experience, and also because in a sense, we are all working towards very similar common goods.
Thanks to Codethink for sponsoring the BuildStream project’s presence at the conference, with the 2.0 release very close on the horizon it should be an exciting time for the project.
![]()