Hi again.
This is a follow up on my recent post on features and improvements to the Evolution Data Server that we’ve been working on at Openismus. Note that the previous post explains what we’ve done in greater detail, some of this post might not make sense without reading the aforementioned post.
As I was asked to write a more complete report on how each of our patch sets effect memory consumption in EDS, I went ahead and ran some further comparisons. As usual, Mathias’ benchmarks saved the day (while the original benchmark suite only generates memory consumption comparisons for a single run of contacts, I was easily able to produce charts for each individual run and compare them separately).
Actually I had postponed this post since I was hoping to update our final patch set for Direct Read Access apis before reporting my findings. It seems however that currently EDS master is in a period of transition and so I’ll postpone the new patch submissions until some temporary regressions in EDS are fixed (the code which does work with EDS master is however available on the branch).
Memory Usage Report
In order to get a grasp of the impacts on memory consumption that each patch set incurs, I’ve added two additional benchmarks to our normal set of benchmarks.
No BDB
This is a custom build of EDS gnome-3-6 branch with the removal of the BDB usage in the local file backend.
At this point there is no extra table in the SQLite to handle multi-valued vCard attributes, it’s simply a comparison of storing the vCard data in the BDB vs SQLite only.
Custom Light
This is a special run of our regular openismus-work branch, but with only the “Full Name” configured and indexed in the summary.
So this benchmark is a light-weight summary with considerably less columns (and one less table) used in the SQLite.
I ran this variation in the suspicion that SQLite might require significantly more memory with the additional multi-value table created to handle multi-valued attributes such as E_CONTACT_TEL.
Benchmark Results
Note that the RSS and VMS memory snapshots are taken by way of observing the /proc/$pid/status file for both the EDS server process and client benchmark process directly after stopping the clock for each benchmark in the suite. So a given value in the charts presented below is based on the “VmRSS” value of the server process added to the “VmRSS” value of the client process.
First, let’s show the results, or at least some of them, to put our deductions into context:

… Skipping a few results here in the interest of avoiding clutter … lets jump directly to 400 contacts …
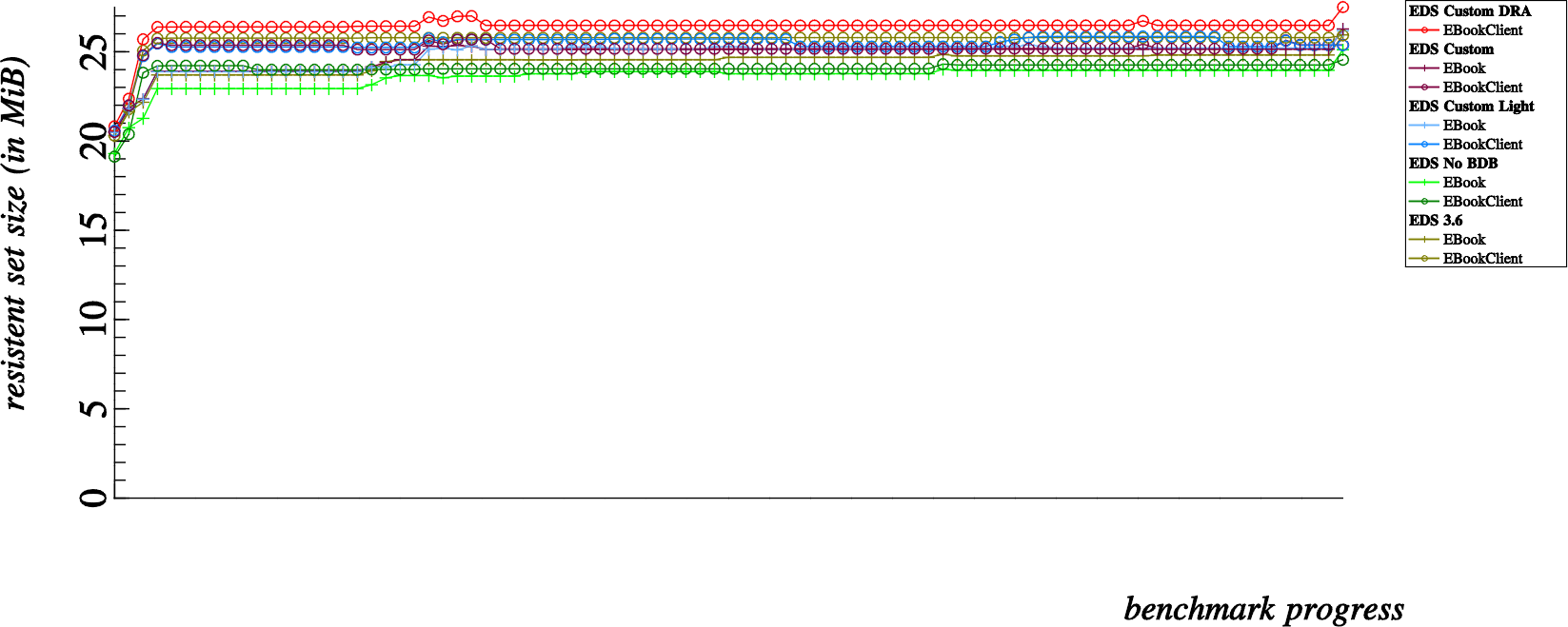
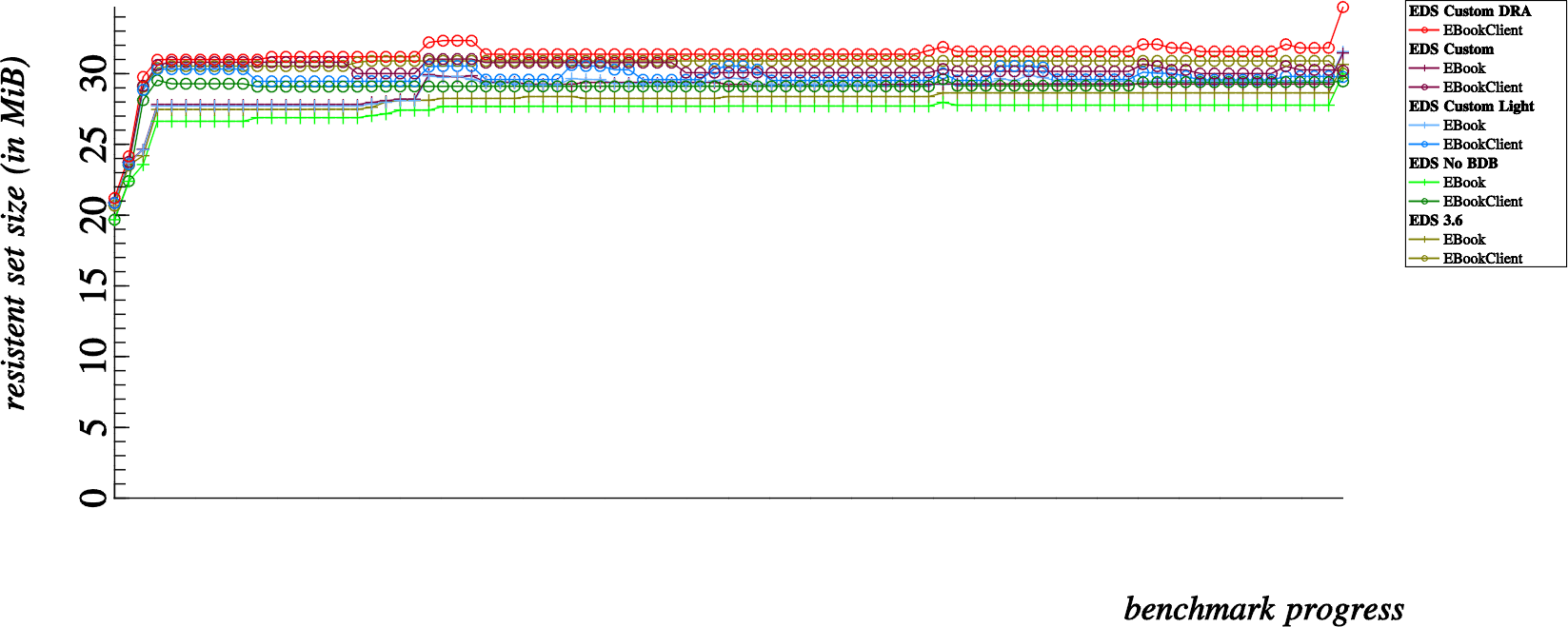

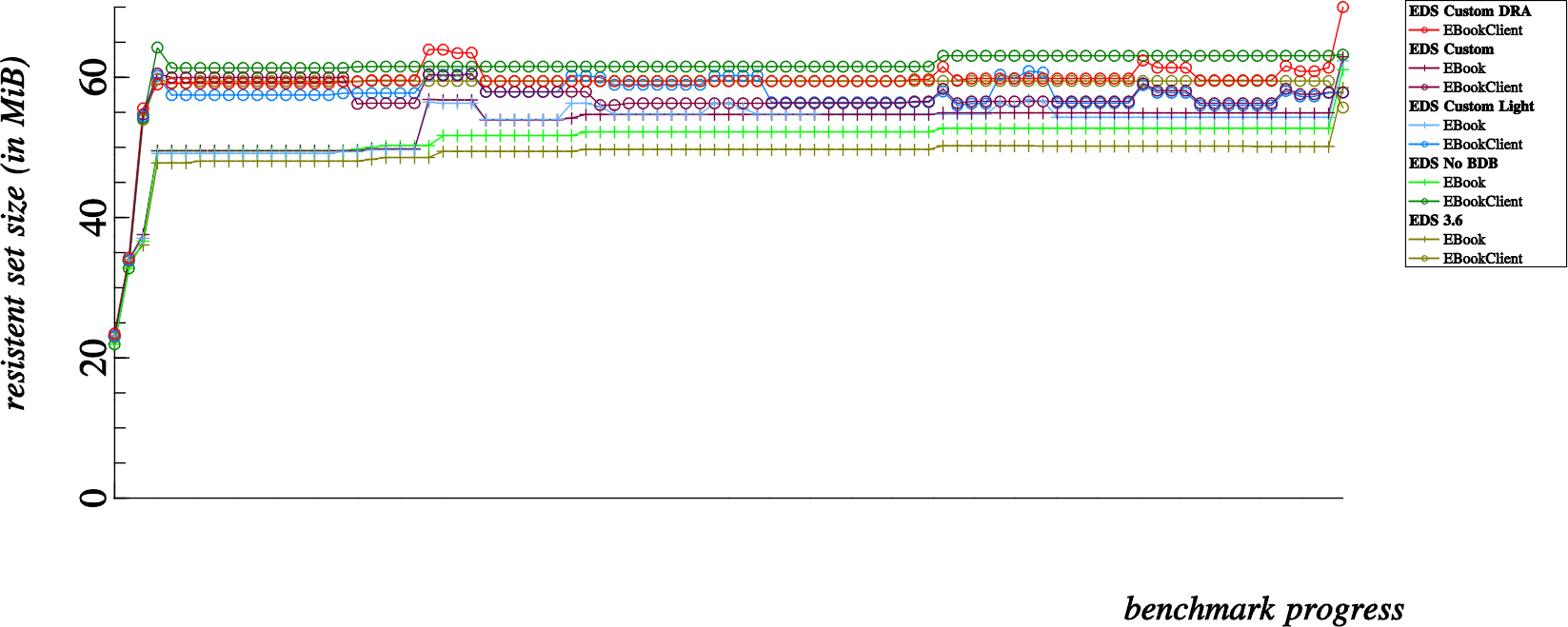
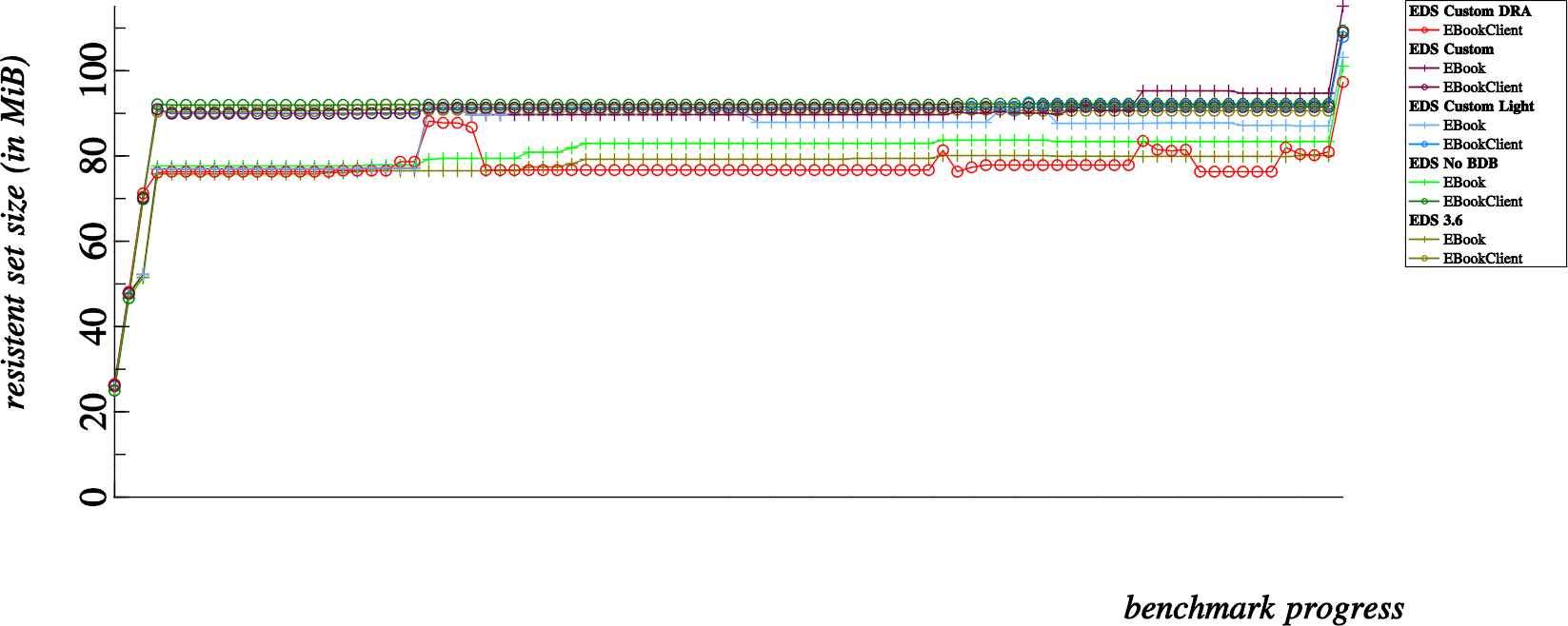
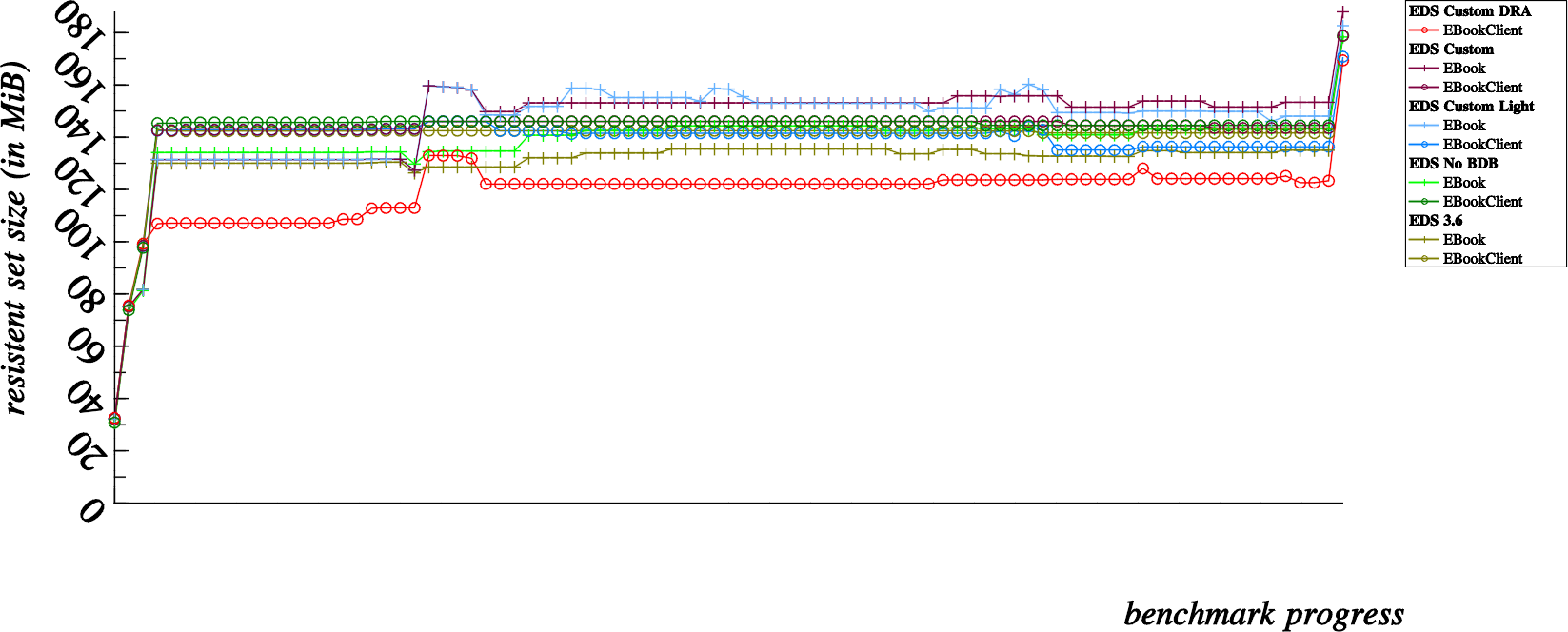
And now, some of the conclusions I came to while observing the results
BDB Removal
When compared to the unmodified EDS 3.6 branch, we can observe that the BDB removal reduces memory consumption for most reasonably sized address books. Up until we run the benchmark for 3,200 contacts, memory consumption is less without BDB… with 3,200 contacts and higher, memory consumption is increased by removing the BDB.
Without an in depth understanding of SQLite internals, I think we can deduce that the SQLite starts to require more memory to handle databases with >= 3,200 rows
Custom Light
This benchmark basically disproved my suspicion.
While using exactly the same code-base as the “EDS Custom” and “EDS Custom DRA” benchmarks; Using more indexes and tables in the SQLite does not seem to incur much of a difference in terms of memory consumption.
While the output is certainly different, as specially with large addressbooks, I don’t see much of a noticeable pattern here.
EDS Custom
This benchmark is basically the openismus-work branch with fully customized indexes for better performance in telephone number lookups.
When comparing this one to the unmodified EDS 3.6 benchmark, we can observe that memory consumption is slightly less using the custom EDS code than stock EDS 3.6.
When comparing this to the removal of BDB, we can notice that, as specially for small addressbooks, the base memory requirement of the EDS Custom is significantly higher than with only the BDB removal.
This second point is easily explainable, since removal of BDB alone reduces the overall memory footprint of EDS. The custom EDS benchmarks, without actually leveraging the Direct Read Access mode still links against the EDataBook library. Essentially this replaces the memory footprint overhead incurred by linking to BDB with a different overhead incurred by linking directly with EDataBook.
EDS Custom DRA
This benchmark is particularly interesting.
For smaller addressbooks the Direct Read Access mode indeed costs more resident memory than any other benchmark. This can be attributed at least partly to the penalty of loading an EDataBook into memory on the client side. Consequently, loading the EDataBook also loads the backend module in the client process, meaning we also have a running EBookBackendFile in the client as well as client side linkage and usage of the SQLite library.
However, once we approach addressbooks with 1600 contacts and more, the overall resident memory consumption starts to even out. Direct Read Access mode actually costs significantly less than any other benchmark for addressbooks as large as 6400 contacts and more.
These results are a bit harder to explain. My theory is that since the EDS server process essentially goes to sleep after adding the initial contacts. All queries thereafter require no interaction with the EDS server process.
Some things to consider here are:
- The cost in memory of constantly waking up the EDS process to handle a query
- The cost of server side heap allocations used to deliver the results over D-Bus
- The cost of client side heap allocations used to receive results over D-Bus
Overall Memory Consumption differences
In summary, we can conclude that after all measures taken to improve performance of contact fetches in EDS; the Direct Read Access mode is the single element which makes a tradeoff in terms of memory consumption versus speed.
Without the Direct Read Access patches, memory consumption as well as time to fetch contacts has seen a net improvement. With Direct Read Access enabled we see that for smaller address books an additional memory overhead is required, while with larger addressbooks (larger than 3,200 contacts); overall resident memory usage has seen a significant improvement as well.