August 30th, 2018 — Audio, General
A new version of SpectMorph, my audio morphing software, is now available on www.spectmorph.org. Besides Linux and Windows, it now also runs on macOS (>= 10.9).
In order to simplify the installation under Linux, the required instrument data for SpectMorph no longer needs to be downloaded seperately. Instead, the source tarball and Ubuntu packages include the instrument data (the other platforms already do this by default, too).
We added recordings of Claudia – a female opera singer – as new instrument (“Claudia Ah”, “Claudia Oh”, “Claudia Ih”). A few improvements to the instrument building tools were made along the way. To get good results from Claudia’s recordings, we had to add an algorithm that systematically reduces vibrato automatically.
As always, a few minor problems were fixed, for instance the VST plugin automation now works properly with Cubase. A detailed list of changes is available here.
The video for my presentation at Linux Audio Conf 2018 about how SpectMorph implements morphing is now available.
Finally, a new piece of music created by Sven and me with SpectMorph has been completed: Clicking.
August 21st, 2018 — Audio, General
Beast 0.12 is available from the Beast Homepage. Beast is an Free and Open Source Linux DAW for composing music with the integrated modular synthesis environment. A detailed list of changes is available in the Release Notes.
From the announce mail on the BEAST List:
This release removes the Rapicorn dependency as well as the runtime dependency on CPython. To achieve that, a number of utilities from Rapicorn has to be integrated, which has made the code base a fair bit larger:
651 files changed, 75581 insertions(+), 44596 deletions(-)
Most notably, this is the first release that installs the new ebeast UI. Tracks, piano rolls and dB meters are already displayed, but not much beyond that as it’s still in pre-alpha stage. However it’s a good showcase for our future UI direction, you can start it and take a quick look with:
$prefix/beast-0-12/bin/ebeast
April 10th, 2018 — Audio, General
A new version of SpectMorph, my audio morphing software is now available on www.spectmorph.org.
One main feature is that besides providing VST, LV2, JACK and BEAST support on Linux, this version is the first version that also provides a VST plugin for (64-bit) Windows.
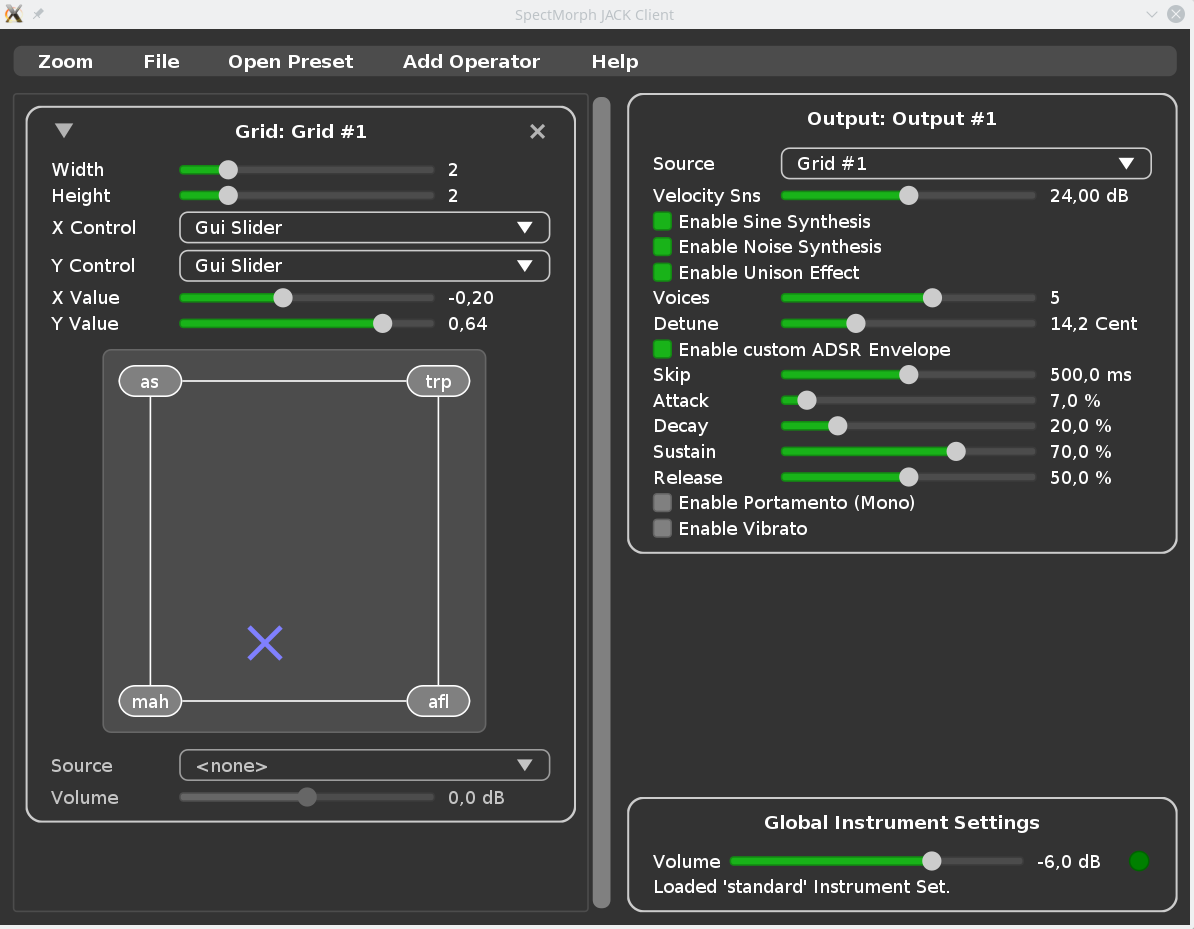
To make the VST plugin portable to Windows, the plugin UI now uses the pugl library (with GL + Cairo) instead of Qt5. This should also allow supporting macOS in the future.
Since the whole plugin UI was reimplemented, a new design is used, and many small improvements were made; the UI is also ready for high(er) DPI displays, everything can be scaled using a global zoom factor. Below is a screenshot of the new UI:
Other changes are:
- A new non-linear mapping from midi velocities to volumes was implemented
- New instrument: French Horn
- Improved tools for building custom instruments
- LPC/LSF support removed
November 29th, 2017 — Audio, General
A new version of gst123, my command line media player – based on gstreamer – is available at http://space.twc.de/~stefan/gst123.php
Thanks to David Fries, this version supports playing media faster or slower compared to the original speed, using { [ ] } as keyboard commands. This works, however, it also changes the pitch. So for instance speech sounds unnatural if the playback rate is changed.
I’ve played around with the youtube speed setting a bit, and they preserve pitch while changing playback speed, providing acceptable audio quality. There are open source solutions for doing this properly, we could get comparable results if we used librubberband (GPL) to correct the pitch in the pipeline after the actual decoding. However, there is no librubberband gstreamer plugin as far as I know.
Also there is playitslowly does the job with existing gstreamer plugins, but I think the sound quality is not as good as what librubberband would do.
I think ideally, playback pitch correction should not be done in gst123 itself (as other players may want to use the feature). So if anybody feels like working on this, I think it would be a nice project to hack on. Feel free to propose patches to gst123 for pitch correct playback rate adjustments, I would be happy to integrate it, but maybe it should just go into the playbin (maybe optional, as in 1. set playback rate, 2. enable pitch correction), so the code could live in gstreamer.
September 29th, 2017 — Audio
A new version of SpectMorph, my audio morphing software is now available on www.spectmorph.org.
The biggest addition is an ADSR-Envelope which is optional, but when enabled allows overriding the natural instruments attack and volume envelope (full list of changes).
I also created a screencast of SpectMorph which gives a quick overview of the possibilities.
June 27th, 2017 — Audio, General
Beast is a music composition and modular synthesis application. beast-0.11.0 is now available at beast.testbit.eu. Support for Soundfont (.sf2) files has been added. On multicore CPUs, Beast now uses all cores for synthesis, which improves performance. Debian packages also have been added, so installation should be very easy on Debian-like systems. And as always, lots of other improvements and bug fixes went into Beast.
Update: I made a screencast of Beast which shows the basics.
June 20th, 2017 — Audio, General
A new version of SpectMorph, my audio morphing software is now available on www.spectmorph.org. The main improvement is that SpectMorph supports now portamento and vibrato. For VST hosts with MPE (Bitwig), the pitch of each note can be controlled by the sequencer. So sliding from a C major chord to a D minor chord is possible. There is also a new portamento/mono mode, which should work with any host.
April 24th, 2017 — Audio, General
Finally after taking the time to integrate improvements, spectmorph-0.3.2 was released. The main feature is certainly the new unison effect. By adding up multiple detuned copies of the same sound, it produces the illusion of multiple instruments playing the same notes. Of course this is just a cheap approximation of what it would sound like if you really recorded multiple real instruments playing the same notes, but it at least makes the sound “seem” more fat than without the effect.
At the same time, the website was redesigned and improved. Besides the new look and feel, there is now also a piece of music called “Morphing Motion” which was made with the newest version of the SpectMorph VST plugin.
Visit www.spectmorph.org to get the new version or listen to the audio demos.
March 29th, 2013 — Audio, General
The new release BEAST-0.8.0 is now available at the beast website. As end-user, you’ll get exactly the same features as before, and might be wondering what changes were made and why. In this blog posting, I’ll try to explain why BEAST-0.8.0 is a lot better than any previous release, and why the improvements in the codebase will soon also speed up all development efforts. If you don’t want to know the technical details, just trust me on this one: I’ve been contributing to BEAST for more than 10 years now, and I’m more than happy that after BEAST-0.8.0, and possibly more infrastructure enhancements in the next minor releases, contributing will become easier, more fun and more productive.
When BEAST development originally started, the project was designed to use Gtk+ as toolkit, and the GObject typesystem as a way to do object oriented programming. This automatically resulted in the requirement that all BEAST code had to be written in C. So from the beginning, a huge codebase (> 200.000 lines of code) of C code were written. The only exception was a few scheme scripts, but compared to the rest of BEAST, a neglectable amount of work was done in Scheme.
I think for realtime audio processing and also GUI programming, C is mostly a waste of developer time (and also leads to less readable code), when compared to C++. But even after it became obvious that I argree on that issue with Tim Janik, the founder of BEAST, it was still a long way to make C++ programming fully acceptable in BEAST. It started with the plugins. BEAST plugins are relatively isolated chunks of code, that do not interact a lot with the rest of the codebase. So relatively early in the history of BEAST, we supported implementing plugins in C++. And if you compare a C++ BEAST plugin with the older C BEAST plugins, you’ll find the code is cleaner, shorter, and more readable.
However, a lot more code is in the GUI and in the BEAST core, or: plugins in C++ are good, but only are a fraction of the whole codebase. Still for all other code, the problem was that interfaces between components had to designed in C, because the majority of the code was written in C. Introducing C++ APIs in the core was acceptable, but only if a second C API was added. So for instance the new FLAC support for BEAST I’ve recently implemented is written in C++, but some of the code is just needed so that the other components in the BEAST core can use it; and these are written in C.
What changed with BEAST-0.8.0? Now the C code hasn’t magically disappeared, but we’re now using the C++ compiler to compile all of BEAST. So with this release the foundation was made for introducing C++ APIs into the core of BEAST, because now all code can use C++ APIs, because the whole core is compiled as C++.
To be more precise, another step was made at the same time. We’re using C++11 as the implementation language now. C++11 is the recently finished new C++ standard, that introduces many new features for the language, and although it is not yet currently fully implemented by g++, many parts already work and will make further development easier. So all in all, the process of getting rid of lots of lots of legacy C code and being able to develop new code in an elegant and efficient C++11 way is not complete. But BEAST-0.8.0 is probably still a lot more developer friendly than any previous release, and I hope that this process will continue in the next releases until the codebase is as C++ friendly as it should be. On the way, we’ll probably also be able to dump GObject based inheritance from the core, and add Python as scripting language; but I’ll blog about these things when they happen.
December 4th, 2012 — General
The flexible and easy to configure backup software twcbackup is now available under GPLv3. It has a graphical configuration tool, can do file level deduplication and supports backing up remote hosts via ssh+rsync (for remote linux hosts) or smb protocol (for windows hosts).
The recommended backup method is bfsync, which I blogged about earlier. This allows nice features like storing the backups on host A in the backup pool, and replicating the backups to host B (via ssh or rsh).
Here is the twcbackup page.