May 1st, 2023 — Audio, General
The main goal of liquidsfz is to implement a library that supports playing .sfz files and is easy to integrate into other projects. We also provide a JACK client and a LV2 plugin.
A new version, liquidsfz-0.3.2 is now available.
This release fixes a crash triggered by Carla while saving without path. It also allows for overlapping notes during sustain, which makes sustain sound more realistic. A precompiled windows LV2 binary is now available.
For a list of changes, see the github release.
July 24th, 2022 — Audio, General
The main goal of liquidsfz is to implement a library that supports playing .sfz files and is easy to integrate into other projects. We also provide a JACK client and a LV2 plugin.
This week, liquidsfz-0.3.0 was released, and liquidsfz-0.3.1 which fixes some problematic bugs in 0.3.0.
The most important changes are:
The sound quality was improved. CPUs are getting faster every year, and systems which have multiple cores are increasingly common. So instead of trying to be ultra fast when playing samples, liquidsfz now provides good quality by default (and it has two lower quality modes if you really need maximum efficiency).
We load samples on demand now, only preloading the start of every sample. This reduces the startup time and memory usage for large sample sets.
For .sfz files which do not define CC7 (Volume) and CC10 (Pan) liquidsfz now provides default behaviour for these CCs (#30).
The license is now MPL2 which is a bit less restrictive than our previous license (LGPL).
The full list of changes is in the NEWS file.
January 27th, 2021 — Audio, General
The main goal of liquidsfz is to implement a library that supports playing .sfz files and is easy to integrate into other projects. We also provide a JACK client and a LV2 plugin.
A new release of liquidsfz is now available (under LGPL2.1+):
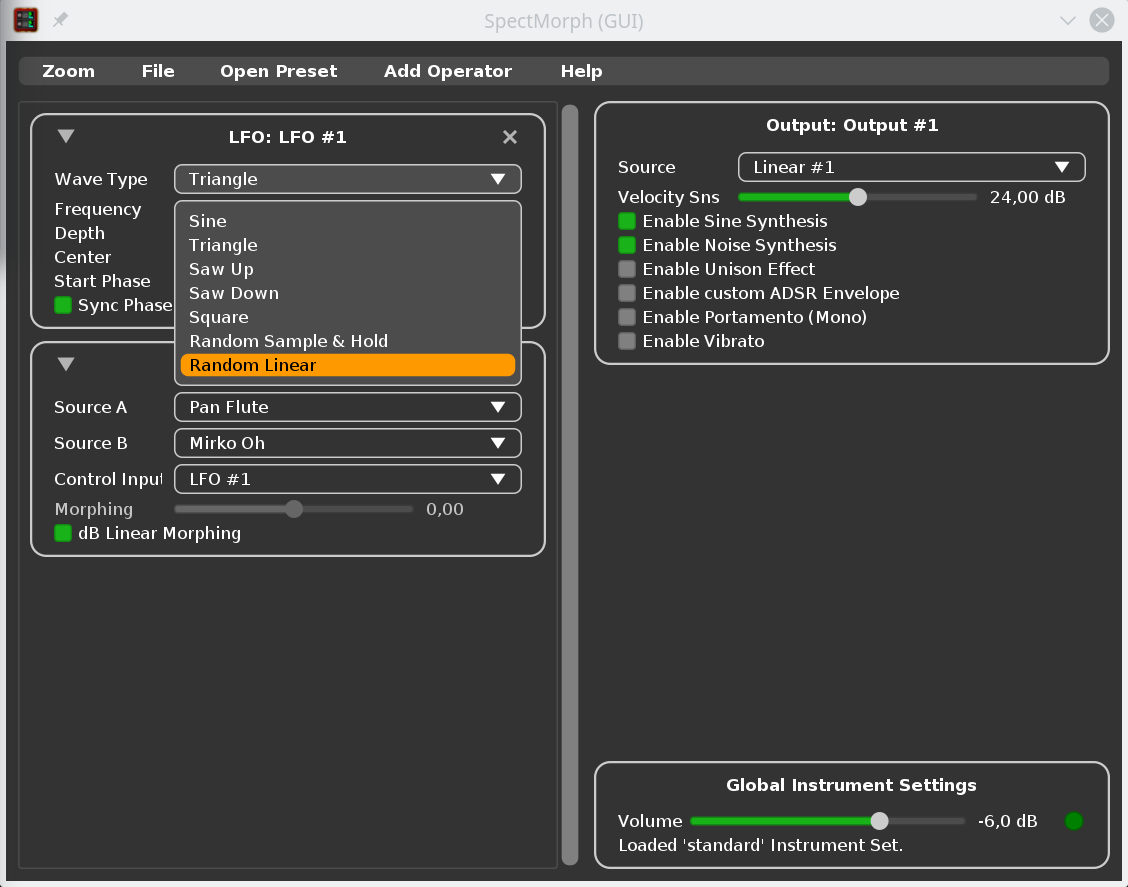
This release adds support for LFOs (both SFZ1 and SFZ2 style). Typical use cases for LFOs are vibrato and tremolo, and the set of opcodes we now support should be enough for many .sfz files which need these features.
To further improve compatibility with existing .sfz files, the preprocessor (#include/#define handling) was improved and support for curve sections and the related opcodes was added.
The full list of changes is in the NEWS files.
January 7th, 2021 — Audio, General
The main goal of liquidsfz is to implement a library that supports playing .sfz files and is easy to integrate into other projects. We also provide a JACK client and a LV2 plugin.
A new release of liquidsfz is now available (under LGPL2.1+):
This release adds SFZ style filters, which means fil_type, cutoff, resonance and a lot of other new opcodes are now supported. All SFZ1 filter types are implemented, and a few SFZ2 filter types (lpf_4p, lpf_6p, hpf_4p, hpf_6p), as well as a filter envelope.
The other bigger change is that the LV2 plugin now reports the supported controllers, the names of the controllers, the names of key switches and the names of the keys to the host using a midnam file. For Ardour6 for instance this means that the names of the keys are shown, as well as the names of the supported controllers, which makes sfzs with exported CCs a lot more usable.
The hydrogen loader also passes this information, so for instance you will see that note 36 is called “Kick” in the loaded hydrogen drumkit.
The full list of changes is in the NEWS files.
October 19th, 2020 — Audio, General
The main goal of liquidsfz is to implement a library that supports playing .sfz files and is easy to integrate into other projects. We also provide a JACK client and a LV2 plugin.
A new release of liquidsfz is now available (under LGPL2.1+):
New opcodes, offset / offset_random / offset_ccN / offset_onccN were added, in order to be able to properly support more .sfz files.
Hydrogen drumkits can now be loaded transparently by loading the drumkit.xml file. We try to map hydrogen features to sfz features. For many drumkits liquidsfz should replay the drumkit identically like hydrogen would. But not all hydrogen features are mapped (for instance hydrogens randomized sample selection is not, so drumkits that use it don’t sound entierly correct). Fortunately most drumkits either sound great or at least usable even without all features hydrogen itself has.
The liquidsfz JACK client is now interactive, so users can type commands like noteon 0 60 127 which would create a note on event for note 60. I use this very heavily for debugging, since using a full DAW like Ardour is quite slow compared to typing a few commands or making a script which can be executed using source somefile as liquidsfz command.
I’d like to summarize everything else as: many small improvements have been made, a few of them requested from the community. This includes better API documentation and a few API additions, a global sample cache to optimize memory usage in some situations, support for shared libraries and lots of other fixes, which should make everything a little bit better for many users.
The full list of changes is in the NEWS files.
September 24th, 2020 — Audio, General
A new version, SpectMorph 0.5.2 is available at www.spectmorph.org.
SpectMorph (LV2/VST plugin, JACK) is able to morph between samples of musical instruments. A standard set of instruments is shipped with SpectMorph, and an instrument editor is available to create user defined instruments from user samples.
With this release, the SpectMorph LFO can be synchronized with the song tempo. This allows morphing frequency to be specified as note length (for instance quarter notes). As a related new feature, the playback speed of samples (user defined instruments) can be controlled using automation/LFOs, so it is possible to time-stretch a sample as needed to be synchronized to the song tempo. To see how to use the new possibilities, I recommend these tutorials:
A full list of all changes can be found here.
And finally here is a new piece of music made with SpectMorph:
April 18th, 2020 — Audio, General
In 2018, a company I was working for asked me to develop an open source solution for audio watermarking. At that point, we didn’t even find a single open source software that would be close to being usable in production.
As a result, today I am making the source code of “audiowmark” publically available under GNU GPL3 or later. It has many features, it is robust, fast, secure and of course we believe that the watermark is not audible for most users.
More infos, source code and audio demos are available on the audiowmark web page.
February 13th, 2020 — Audio, General
A new version, SpectMorph 0.5.1 is available at www.spectmorph.org. SpectMorph is a VST/LV2/JACK synthesis engine which is based on the idea of analyzing audio samples and combining them using morphing.
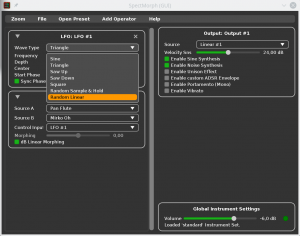
As you can see in the screenshot, there are a few new LFO wave forms available (saw, square and random).
On Windows and macOS, from the beginning there was no need for users to compile anything. You could just download SpectMorph, install it and use it. On Linux, we provide packages for Ubuntu and there are also distribution packages for Arch Linux. But this means that as a user, if you use a different linux distribution, you had to build SpectMorph from source. Which may be too difficult for the average user.
This release improves the situation: there are now Generic 64bit Linux binaries available, which provide the VST/LV2 plugin (statically linked). So these binaries should run on just about any linux. Note that this is a new feature, so please let me know if the generic binaries don’t work for you.
This release also contains a few fixes and the detailed list of changes can be found here.
Finally let me recommend two youtube videos (if you haven’t watched these yet):
November 12th, 2019 — Audio
Years ago, I’ve implemented SF2 (“SoundFont”) support for Beast. This was fairly easy. FluidSynth provides everything to play back SF2 files in an easy to use library, which is available under LGPL2.1+. Since integrating FluidSynth is really easy, many other projects like LMMS, Ardour, MusE, MuseScore, QSynth,… support SF2 via FluidSynth.
For SFZ, I didn’t find anything that would be as easy to use as FluidSynth. Some projects ship their own implementation (MuseScore has Zerberus, Carla has its own version of SFZero). Both are effectively GPL licensed. Neither SFZ code would be easily integrated into Beast. Zerberus depends on the Qt toolkit. SFZero originally used JUCE and now uses a stripped down version of JUCE called water, which is Carla only (and should not be used in other projects).
LinuxSampler is also GPL with one additional restriction that disallows usage in proprietary context without permission. I am not a lawyer but I think this is no longer GPL, meaning that you cannot combine this code with other GPL software. A small list of reasons why Carla no longer uses LinuxSampler can be found here: https://kx.studio/News/?action=view&url=carla-20-rc1-is-here
In any case for Beast we want to keep our core libraries LGPL, which none of the projects I mentioned can do. So liquidsfz is my attempt to provide an easy-to-integrate SFZ player, which can be used in Beast and other projects. So I am releasing the very first version “0.1.0” today: https://github.com/swesterfeld/liquidsfz#releases
This first release should be usable, there are only the most important SFZ opcodes covered.
July 22nd, 2019 — Audio, General
A new version of SpectMorph, my audio morphing software, is now available on www.spectmorph.org. SpectMorph is a VST/LV2/JACK synthesis engine which is based on the idea of analyzing audio samples and combining them using morphing.
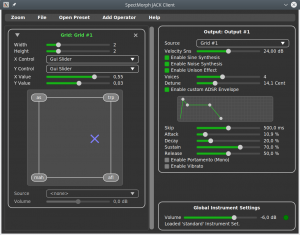
SpectMorph could always create sounds by morphing between the musical instruments bundled with SpectMorph. With this release, a new graphical instrument editor was added, which allows loading custom samples. So SpectMorph users can now create user defined instruments and morph between them.
Here is a screencast which demonstrates how to do it.
Besides this big change, the releases contains a few smaller improvements. A detailed list of changes is available here.
Finally, here is some new music made with SpectMorph: