It seems I am now on planet gnome. Thanks Jeff! I’d better introduce myself. I am a 4th year CS student living in Cape Town, South Africa. I have been hacking on Glade 3 since 2006, and have committed bug fixes to various GNOME modules.
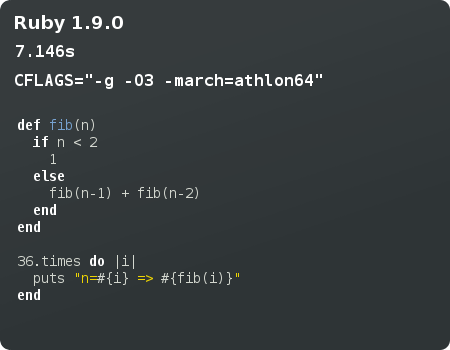
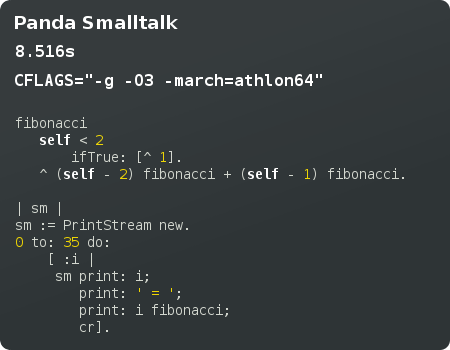
Since November, I have been working on a new project of mine, Panda, a Smalltalk system. Its a personal mastery project, aimed at improving my programming skills whilst producing a complex system. I didn’t think I was challenging myself with glade3, and realised that I no longer wanted to do application development using C and GObject. I was on the lookout for a new language, sampling Java, Ruby, and Objective-C. I finally made my bed with Smalltalk.
My long term goal is put a GNOME development environment on top of Panda. Smalltalk IDEs are very different to conventional ones such as Eclipse or Emacs. For one, there is no process boundary separating the IDE and the program being tested, allowing all sorts of rich refactoring and inspection. Gilad Bracha speaks more about this.
That’s going to be at least 18 months away though, since there’s still a lot of VM work to be done. We do have some pretty compelling VM technology in panda right now, including a bytecode interpreter, compacting garbage collector, and fast tagged integers. Of course this all normal stuff for most Smalltalk VMs out there. The next step for me is rewrite the compiler in Smalltalk, since the VM seems stable enough to support it.