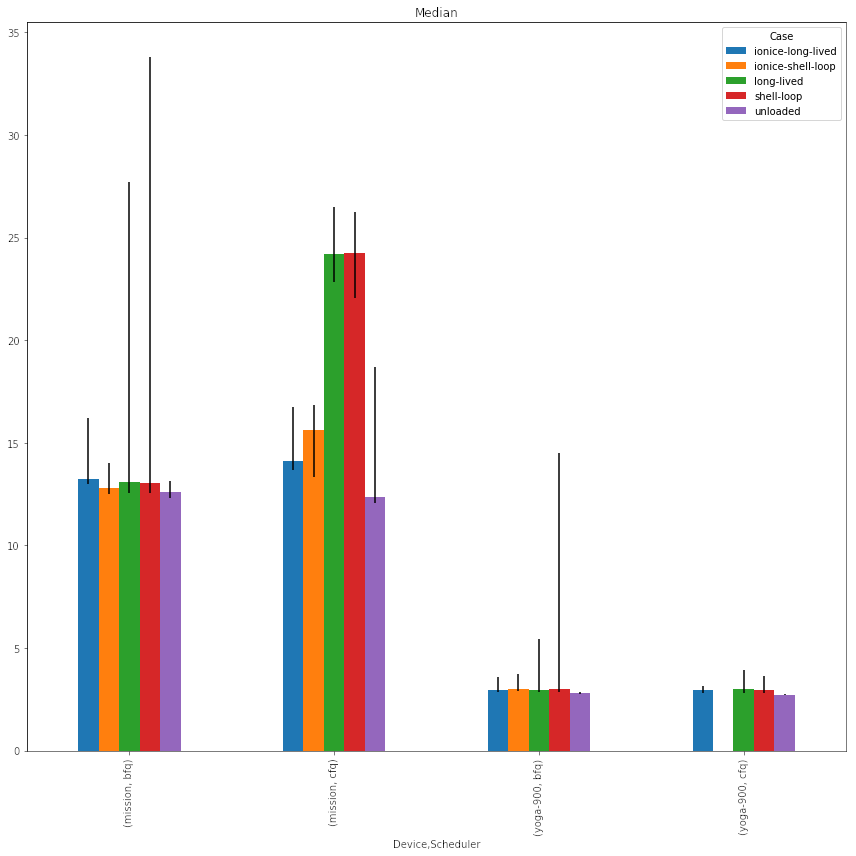
OARS (Open Age Ratings Service) defines a scheme to include content rating information in apps’ AppData/AppStream file. GNOME Software and similar tools use this metadata to show age ratings for applications. In Endless OS, we also support restricting which applications a given user can install based on this data – see this page, and the reports it links to, for a bit more information about this feature and its future.

Every new app on Flathub should include OARS metadata, but there are many existing apps which don’t have this data, so it’s not (yet) enforced at build time. Edit: Bartłomiej tells me that it has been enforced at build time for a little over a month. (See App Requirements and AppData Guidelines on the Flathub wiki for some more information on what’s required and recommended; this branch of appstream-glib is modified to enforce Flathub’s policies.) My colleague Andre Magalhaes crunched the data and opened a tracker task for Flathub apps without OARS metadata. ((We have a similar list for our in-house apps.)) This information is much more useful if it can be relied upon to be present.
If you’re familiar with an app on this list, generating the OARS data is a simple process: open this generator in your browser, answer some questions about the app, and receive some XML. The next step is to put that OARS data into the AppData. ((If you’re the upstream maintainer for the app, you probably already know how to do all this, and can stop reading here!)) Take a look at the app’s Flathub repo and check whether it has an .appdata.xml file.
If it doesn’t, then the app’s AppData must be maintained upstream. Great! Find the upstream repository for the project, and send a merge request there. (Here’s one I sent earlier, for D-Feet.) You can either add the same patch to the Flathub packaging (as I did for D-Feet) or wait for a new upstream release and then update the Flathub packaging to that version (as I also did for D-Feet, a couple of days later).
If the appdata is maintained in the Flathub repo, make the relevant changes there directly. (Here’s a PR I opened for Tux, of Math Command while writing this post.) Ideally, the appdata would make its way upstream, but there are a fair few apps on Flathub which do not have active upstreams.
You might well find that the appdata requirements have become more strict about things other than OARS since the app was last updated, and these will have to be fixed too. In both the example cases above, I had to add release information, which has become mandatory for Flathub apps since these were last updated.