The GNOME 44 release is rushing towards us like an irate pangolin! Here is a quick roundup of some of the Endless OS Foundation team’s contributions over its six-month development cycle.
Software
As in the previous cycle, our team has been a key contributor to GNOME Software 44. Based on a very unscientific analysis of the Git commit log, about 30% of non-merge commits and 75% of merge commits to GNOME Software during this cycle came from our team. Co-maintainer Philip Withnall has continued his work to refactor Software’s internal threading model to improve its reliability. He’s also contributed a number of fixes in both GNOME Software and Flatpak to fix issues related to app updates, such as not leaking large temporary directories when an update fails. Dan Nicholson fixed an issue in Flatpak which would cause Software to remove an app rather than updating it when its ID changes.
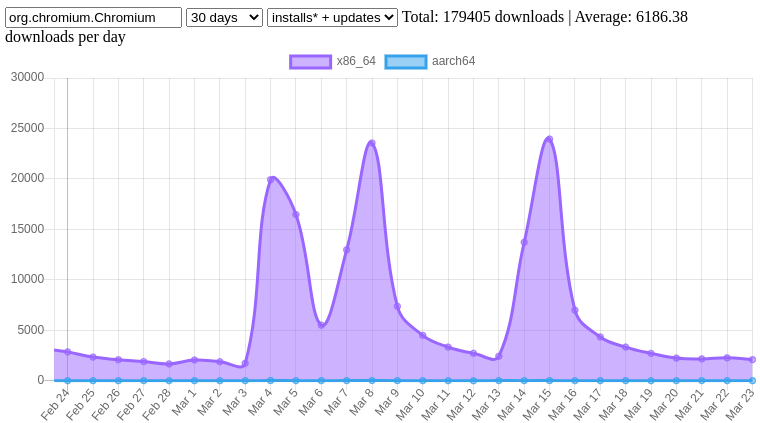
Georges Stavracas added some sysprof instrumentation which allowed him to quickly pinpoint the main cause of slow loading of category pages. To our collective surprise, the culprit was… loading remote icons for apps! Georges fixed this issue by downloading icons asynchronously. A side-by-side comparison is really quite striking:
As we came closer to the release of Endless OS 5, we realised we needed some improvements to the handling of OS updates in GNOME Software, such as showing a Learn More link for major upgrades, distinguishing between major upgrades and minor updates, and using the distro’s icon when showing a minor update. Like Endless OS, GNOME OS uses eos-updater, although these improvements will not kick in fully there right now, since it currently does not set any OS version metadata on its updates, or a logo in os-release.
Of course, we’ve also contributed to the ongoing maintenance of Software, and other functional improvements such as displaying release urgency levels for firmware updates.
Looking ahead, Joana Filizola has spearheaded a series of user studies on topics like how navigation within Software works, discoverability of search, and the name ‘Software’ itself: we hope these will bear fruit in future GNOME cycles.
Shell
As well as ongoing maintenance of Shell and Mutter, Georges Stavracas contributed improvements to the quick settings pills, adding subtitles to improve the information density. This went hand-in-hand with work to improve GNOME’s handling of Flatpak apps that are running in the background (i.e. without a visible window). Previously this was rather crude: if a Flatpak app ran without a window for some period of time, you would get a decontextualized dialog box asking if you want to allow the app to keep running. Choosing the “wrong” option would kill the app and forbid it from running in the background in future – breaking core functionality for certain apps. In GNOME 44, background apps are instead listed within the quick settings popover, and those apps that do use the background portal API to ask nicely to run in the background are allowed to do so without user interaction.
We also supported the design team’s experiments around how window focus is communicated.
GLib
Philip Withnall has, as in many previous cycles, contributed tens of hours of ongoing maintenance to this library that underpins the entire desktop. This has included a number of GVariant security fixes (like this one), GApplication security fixes, GDBus refcounting fixes, and more. Philip also added g_free_sized() and g_aligned_free_sized(), mirroring similar functions in C23, so that applications can start using these without needing to check for (or wait for) C23 support in the toolchain.
Initial Setup
I spent somewhat fewer hours—but not zero!—on general maintenance of Initial Setup. Georges fixed a regression that meant that privacy policies could not be viewed from within Initial Setup; I fixed the display of a shortlist of keyboard layouts, and of non-ASCII characters in location names after switching locale; and Cassidy James Blaede refreshed the design of the password page to use Adwaita widgets & styling.
…and more
Every quarter, the engineering teams at Endless OS Foundation have an “intermission week”, where the team sets aside our normal priorities to focus on addressing tech debt, wishlist items, innovative or experimental ideas, and learning. Some of the items above came out of the last couple of intermission weeks! On top of that, Philip has spent some time experimenting with APIs to allow apps’ state to be saved and restored; and João Paulo Rechi Vita explored making the GNOME Online Accounts daemon quit when idle, saving a small but non-zero amount of RAM. Neither of these are quite in a production-ready state, but as they say: there’s always another release!
Meanwhile, we’ve been working on extending the set of web apps offered in GNOME Software on Endless OS, using more expansive criteria than the list shipped by GNOME Software by default, and a different delivery mechanism for the catalogue. More on this in a future post!