TLDR: in Endless OS, we switched the IO scheduler from CFQ to BFQ, and set the IO priority of the threads doing Flatpak downloads, installs and upgrades to “idle”; this makes the interactive performance of the system while doing Flatpak operations indistinguishable from when the system is idle.
At Endless, we’ve been vaguely aware for a while that trying to use your computer while installing or updating apps is a bit painful, particularly on spinning-disk systems, because of the sheer volume of IO performed by the installation/update process. This was never particularly high priority, since app installations are user-initiated, and until recently, so were app updates.
But, we found that users often never updated their installed apps, so earlier this year, in Endless OS 3.3.10, we introduced automatic background app updates to help users take advantage of “new features and bug fixes” (in the generic sense you so often see in iOS/Android app release notes). This fixed the problem of users getting “stuck” on old app versions, but made the previous problem worse: now, your computer becomes essentially unusable at arbitrary times when app updates happen. It was particularly bad when users unboxed a system with an older version of Endless OS (and hence a hundred or so older apps) pre-installed, received an automatic OS update, then rebooted into a system that’s unusable until all those apps have been updated.
At first, I looked for logic errors in (our versions of) GNOME Software and Flatpak that might cause unneccessary IO during app updates, without success. We concluded that heavy IO load when updating a large app or runtime is largely unavoidable, ((modulo Umang’s work mentioned in the coda)) so I switched to looking at whether we could mitigate this by tweaking the IO scheduler.
The BFQ IO scheduler is supposed to automatically prioritize interactive workloads over bulk workload, which is pretty much exactly what we’re trying to do. The specific example its developers give is watching a video, without hiccups, while copying a huge file in the background. I spent some time with the BFQ developers’ own suite of benchmarks on two test systems: a Lenovo Yoga 900 (with an Intel i5-6200U @ 2.30GHz and a consumer-grade M.2 SSD) and an Endless Mission One (an older system with a Celeron CPU and a laptop-class spinning disk). Neither JP nor I were able to reproduce any interesting results for the dropped-frames benchmark: with either BFQ or CFQ (the previous default IO scheduler), the Yoga essentially never dropped frames, whereas the IO workloads immediately rendered the Mission totally unusable. I had rather more success with a benchmark which measures the time to launch LibreOffice:
- On the Yoga, when the system was idle, the mean launch time went from 2.838s under CFQ to 2.98s under BFQ (a slight regression), but with heavy background IO, the mean launch time went from 16s with CFQ (standard deviation 0.11) to 3s with BFQ (standard deviation 0.51).
- On the Mission, with modest background IO, the mean launch time was 108 seconds under BFQ, which sounds awful; but under CFQ, I gave up waiting for LibreOffice to start after 8 minutes!
Emboldened by these results, I went on to look at how the same “time to launch LibreOffice” benchmark fared when the background IO load is “installing and uninstalling a Lollipop Flatpak bundle in a loop”. I also looked at using ionice -c3 to set the IO priority of the install/uninstall loop to idle, which does what its name suggests: BFQ essentially will never serve IO at the idle priority if there is IO pending at any higher priority. You can see some raw data or look at some extended discussion copied from our internal issue tracker to a Flatpak pull request, but I suggest just looking at this chart:
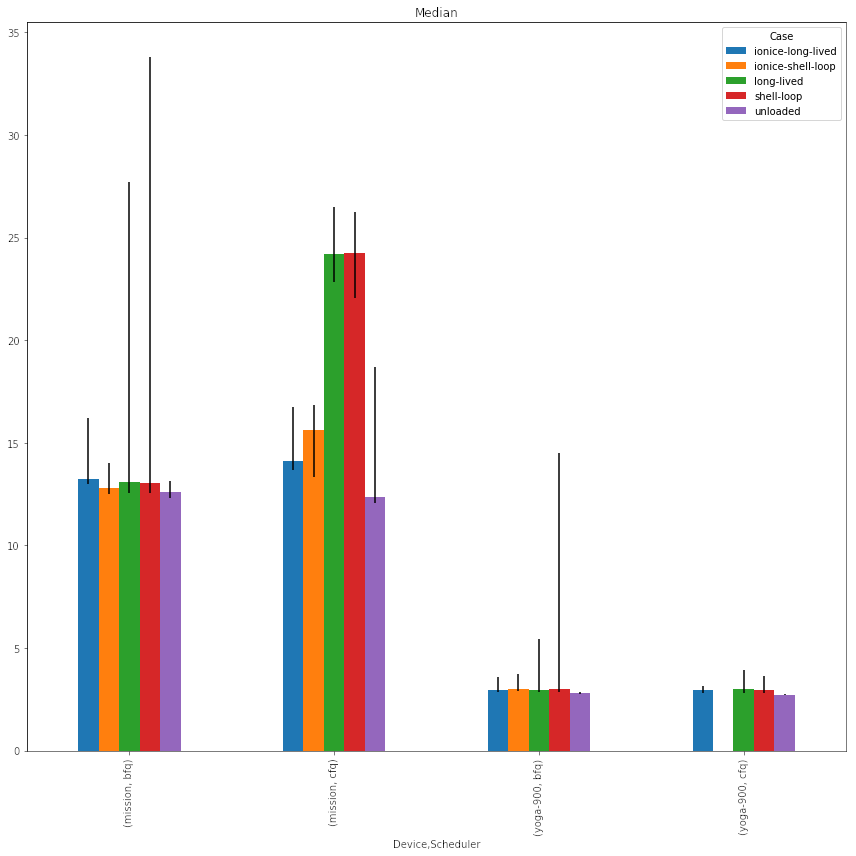
What does it all mean?
- The coloured bars represent median launch time in seconds for LibreOffice, across 15/30 trials for Yoga/Mission respectively.
- The black whiskers show the minimum and maximum launch times observed. I know this should have been a box-and-whiskers or violin plot, but I realised too late that multitime does not give enough information to draw those.
- “unloaded” refers to the performance when the system is otherwise idle.
- “shell-loop” refers to running while true; do flatpak install -y /home/wjt/Downloads/org.gnome.Lollypop.flatpak; flatpak uninstall -y org.gnome.Lollypop/x86_64/stable; done; “long-lived” refers to performing the same operations with the Flatpak API in a long-lived process. I tried this because I understood that BFQ gives new processes a slight performance boost, but on a real system the GNOME Software and Flatpak system helper processes are long-lived. As you can see, the behaviour under BFQ is actually the other way around in the worst case, and identical for CFQ and in the median case.
- The “ionice-” prefix means the Flatpak operation was run under ionice -c3.
- Switching from CFQ to BFQ makes the worst case a little worse at the default IO priority, but the median case much better.
- Setting the IO priority of the Flatpak process(es) to idle erases that worst-case regression under BFQ, and dramatically improves the median case under CFQ.
- In combination, the time to launch LibreOffice while performing Flatpak operations in the background on the Mission went from 24 seconds to 12 seconds by switching to BFQ & setting the IO priority to idle.
So, by switching to BFQ and setting IO priorities appropriately, the system’s interactive performance while performing background updates is now essentially indistinguishable from when the system is idle. To implement this in practice, Rob McQueen wrote some patches to set the IO priority of the Flatpak system helper and GNOME Software’s worker threads to idle (both changes are upstream) and changed Endless OS’s default IO scheduler to BFQ where available. As Matthias put it on #flatpak when shown this chart and that first link: “not bad for a 1-line change”.
Of course, this means apps take a bit longer to install, even on a mostly-idle system. No, I don’t have numbers on how big the impact is: this work happened months ago and it’s taken me this long to write it up because I couldn’t find the time to collect more data. But my colleague Umang is working on eliminating up to half of the disk IO performed during Flatpak installations so that should more than make up for it!