
When I first looked into video codecs (back when VP8 was released), I imagined them being these insanely complex beasts that required multiple PhDs to understand. But as I quickly learned, video codecs are quite simple in concept. Now that VP9 is gaining support from major industry players (see supporting statements in December 2016 from Netflix and Viacom), I figured it’d be useful to explain how VP9 works.
Why we need video codecs
That new television that you’ve been dreaming of buying – with that fancy marketing term, UHD (ultra high-definition). In numbers, this is 3840×2160 pixels at 60 fps. Let’s assume it’s HDR, so 10 bits/component, at YUV-4:2:0 chroma subsampling. Your total uncompressed data rate is:
3840 x 2160 x 60 x 10 x 1.5 = 7,464,960,000 bits/sec =~ 7.5 Gbps
And since that would RIP your internet connection when watching your favourite internet stream, you need video compression.
Basic building blocks
A video stream consists of frames, and each frame consists of color planes. Most of us will be familiar with the RGB (red-green-blue) colorspace, but video typically uses the YUV (Y=luma/brightness, U/V=blue/red chroma difference) colorspace. What makes YUV attractive from a compression point-of-view is that most energy will be concentrated in the luma plane, which provides us with a focus point for our compression techniques. Also, since our eyes are less perceptive to color distortion than to brightness distortion, the chroma planes typically have a lower resolution. In YUV-4:2:0, the chroma planes have only half the width/height of the luma plane, so for 4K video (3840×2160), the chroma resolution is only 1920×1080 per plane:

VP9 also supports other chroma subsamplings, such as 4:2:2 and 4:4:4. Next, frames are sub-divided in blocks. For VP9, the base block size is 64×64 pixels (similar to HEVC). Older codecs (like VP8 or H.264) use 16×16 as base block size, which is one of the reasons they perform less well for high-resolution content. These blocks are the basic unit in which video codecs operate:

Now that the fundamentals are in place, let’s look closer at these 64×64 blocks.
Block decomposition
 Each 64×64 block goes through one or more rounds of decomposition, which is similar to quad-tree decomposition used in HEVC and H.264. However, unlike the two partitioning modes (none and split) in quad-tree, VP9 block decomposition has 4 partitioning modes: none, horizontal, vertical and split. None, horizontal and vertical are all terminal nodes, whereas split recurses down at the next block level (32×32), where each of the 4 sub-blocks goes through a subsequent round of the decomposition process. This process can continue up until the 8×8 block level, where all partitioning modes are terminal, which means 4×4 is the smallest possible block size.
Each 64×64 block goes through one or more rounds of decomposition, which is similar to quad-tree decomposition used in HEVC and H.264. However, unlike the two partitioning modes (none and split) in quad-tree, VP9 block decomposition has 4 partitioning modes: none, horizontal, vertical and split. None, horizontal and vertical are all terminal nodes, whereas split recurses down at the next block level (32×32), where each of the 4 sub-blocks goes through a subsequent round of the decomposition process. This process can continue up until the 8×8 block level, where all partitioning modes are terminal, which means 4×4 is the smallest possible block size.
If you do this for the blocks we highlighted earlier, the full block decomposition partitioning (red) looks like this:

Next, each terminal block goes through the main block decoding process. First, a set of block elements are coded:
- the segment ID allows selecting a per-block quantizer and/or loop-filter strength level that is different from the frame-wide default, which allows for adaptive quantization/loop-filtering. The segment ID also allows encoding a fixed reference and/or marking a block as skipped, which is mainly useful for static content/background;
- the skip flag indicates – if true – that a block has no residual coefficients;
- the intra flag selects what prediction type is used for prediction: intra or inter;
- lastly, the transform size defines the size of the residual transform through which residual data is coded. The transform size can be 4×4, 8×8, 16×16 or 32×32, and cannot be larger than the block size. This is identical to HEVC. H.264 only supports up to 8×8.
Depending on the value of the transform size, a block can contain multiple transform blocks (blue). If you overlay the transform blocks on top of the block decomposition from earlier, it looks like this:

Inter prediction
 If the intra flag is false, each block will predict pixel values by copying pixels from 1 or 2 previously coded reference frames at specified pixel offsets, called motion vectors. If 2 reference frames are used, the prediction values from each reference frame at the specified motion vector pixel offset will be averaged to generate the final predictor. Motion vectors have up to 1/8th-pel resolution (i.e. a motion vector increment by 1 implies a 1/8th pixel offset step in the reference), and the motion compensation functions use 8-tap filters for sub-pixel interpolation. Notably, VP9 supports selectable motion filters, which does not exist in HEVC/H.264. Chroma planes will use the same motion vector as the luma plane.
If the intra flag is false, each block will predict pixel values by copying pixels from 1 or 2 previously coded reference frames at specified pixel offsets, called motion vectors. If 2 reference frames are used, the prediction values from each reference frame at the specified motion vector pixel offset will be averaged to generate the final predictor. Motion vectors have up to 1/8th-pel resolution (i.e. a motion vector increment by 1 implies a 1/8th pixel offset step in the reference), and the motion compensation functions use 8-tap filters for sub-pixel interpolation. Notably, VP9 supports selectable motion filters, which does not exist in HEVC/H.264. Chroma planes will use the same motion vector as the luma plane.
In VP9, inter blocks code the following elements.
- the compound flag indicates how many references will be used for prediction. If false, this block uses 1 reference, and if true, this block uses 2 references;
- the reference selects which reference(s) is/are used from the internal list of 3 active references per frame;
- the inter mode specifies how motion vectors are coded, and can have 4 values: nearestmv, nearmv, zeromv and newmv. Zeromv means no motion. In all other cases, the block will generate a list of reference motion vectors from nearby blocks and/or from this block in the previous frame. If inter mode is nearestmv or nearmv, this block will use the first or second motion vector from this list. If inter mode is newmv, this block will have a new motion vector;
- the sub-pixel motion filter can have 3 values: regular, sharp or smooth. It defines which 8-tap filter coefficients will be used for sub-pixel interpolation from the reference frame, and primarily effects the appearance of edges between objects;
- lastly, if the inter mode is newmv, the motion vector residual is added to the nearestmv value to generate a new motion vector.
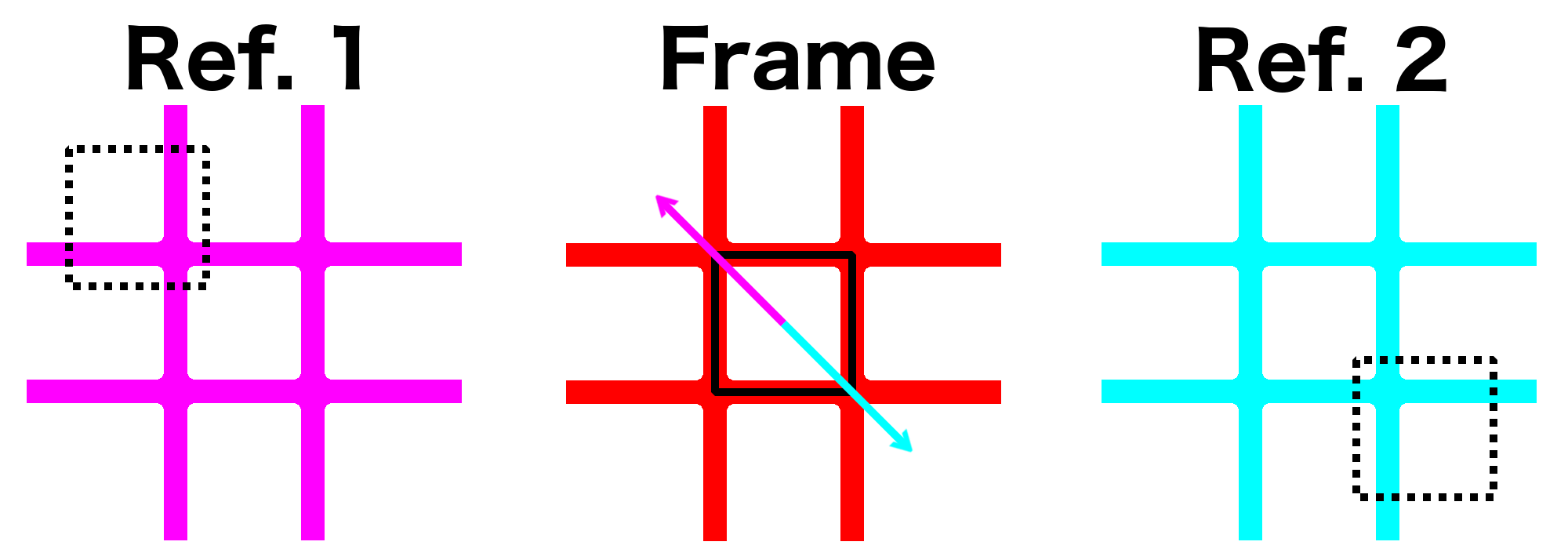
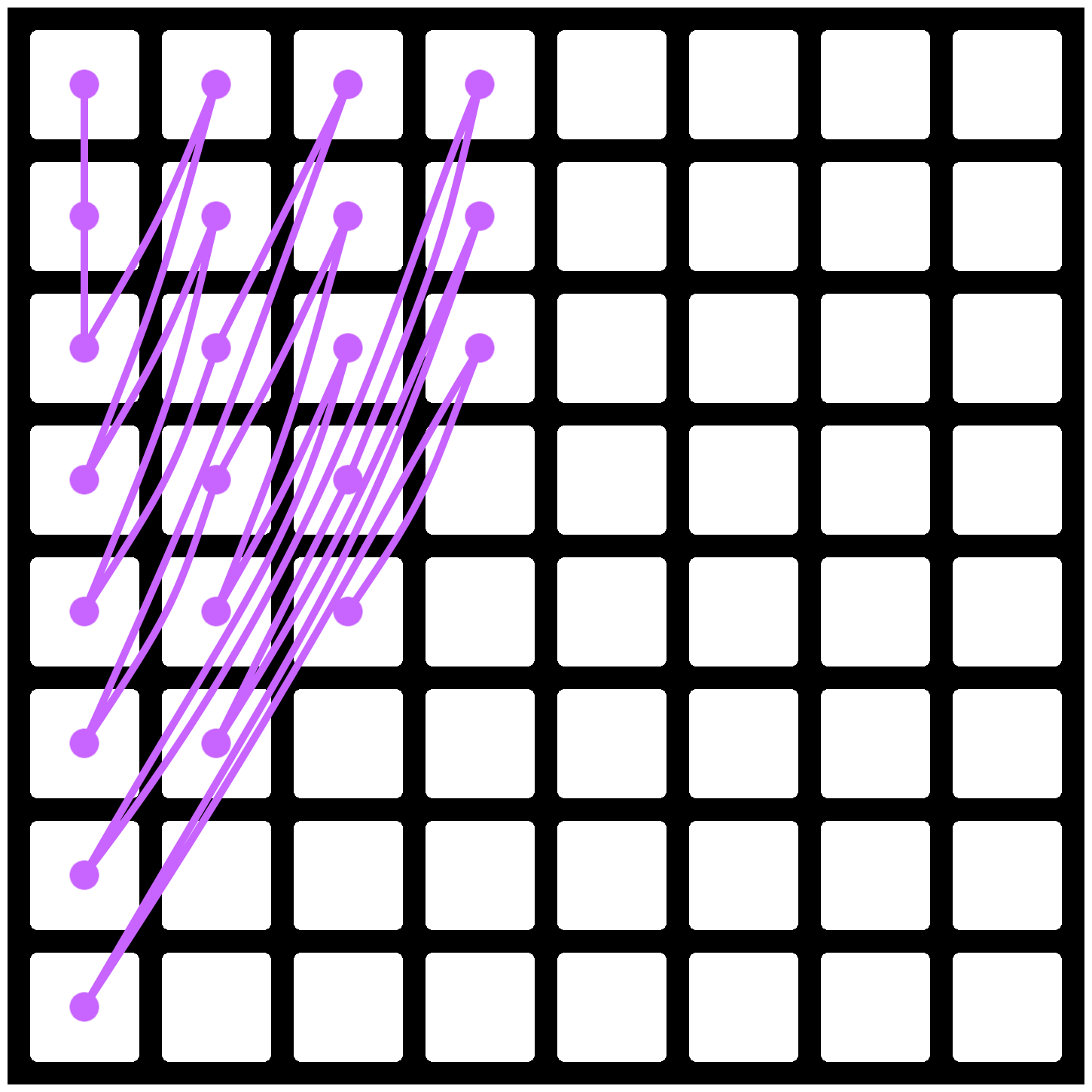
If you overlay motion vectors (using cyan, magenta and orange for each of the 3 active references) on top of the transform/block decomposition image from earlier, it’s easy to notice that the motion vectors essentially describe the motion of objects between the current frame and the reference frame. It’s easy to see that the purple/cyan motion vectors often have opposite directions, because one reference is located (temporally) before this frame, whereas the other reference is located (temporally) after this frame.

Intra Prediction
 In case no acceptable reference is available, or no motion vector for any available reference gives acceptable prediction results, a block can use intra prediction. For intra prediction, edge (top/top-right, left and top-left) pixels are used to predict the contents of the current block. The exact mechanism through which the edge pixels are filtered to generate the predictor is called the intra prediction mode. There are three types of intra predictors:
In case no acceptable reference is available, or no motion vector for any available reference gives acceptable prediction results, a block can use intra prediction. For intra prediction, edge (top/top-right, left and top-left) pixels are used to predict the contents of the current block. The exact mechanism through which the edge pixels are filtered to generate the predictor is called the intra prediction mode. There are three types of intra predictors:
- directional, with 8 different values, each indicating a different directional angle – see schematic;
- TM (true-motion), where each predicted pixel(x,y) = top(x) + left(y) – topleft;
- and DC (direct current), where each predicted pixel(x,y) = average(top(1..n) and left(1..n)).
This makes for a total of 10 different intra prediction modes. This is more than H.264, which only has 4 or 9 intra prediction modes (DC, planar, horizontal, vertical or DC and 8 directional ones) depending on the block size and plane type (luma vs. chroma), but also less than HEVC, which has 35 (DC, planar and 33 directional angles).
Although a mode is shared at the block level, intra prediction happens at the transform block level. If one block contains multiple transform blocks (e.g. a block of 8×4 will contain two 4×4 transform blocks), both transform block re-use the same intra prediction mode, so it is only coded once.
Intra prediction blocks contain only two elements:
- luma intra prediction mode;
- chroma intra prediction mode.
So unlike inter blocks, where all planes use the same motion vector, intra prediction modes are not shared between luma and chroma planes. This image shows luma intra prediction modes (green) overlayed on top of the transform/block decompositions from earlier:

Residual coding
The last part in the block coding process is the residual data, assuming the skip flag was false. The residual data is the difference between the original pixels in a block and the predicted pixels in a block. These pixels are then transformed using a 2-dimensional transform, where each direction (horizontal and vertical) is either a 1-dimensional (1-D) discrete cosine transform (DCT) or an asymmetric discrete sine transform (ADST). The exact combination of DCT/ADST in each direction depends on the prediction mode. Intra prediction modes originating from the top edge (the vertical intra prediction modes) use ADST vertically and DCT horizontally; modes originating from the left edge (the horizontal intra prediction modes) use ADST horizontally and DCT vertically; modes originating from both edges (TM and the down/right diagonal directional intra prediction mode) use ADST in both directions; and finally, all inter modes, DC and the down/left diagonal intra prediction mode use DCT in both directions. By comparison, HEVC only supports ADST combined in both directions, and only for the 4×4 transform, where it’s used for all intra prediction modes. All inter modes and all other transform sizes use DCT in both directions. H.264 does not support ADST.
- DCT:
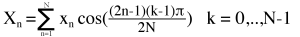
- ADST:
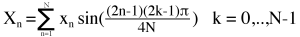
Lastly, the transformed coefficients are quantized to reduce the amount of data, which is what provides the lossy part of VP9 compression. As an example, the quantized, transformed residual of the image that we looked at earlier looks like this (contrast increased by ~10x):

Coefficient arrays are coded into the bitstream using scan tables. The purpose of a transform is to concentrate energy in fewer significant coefficients (with quantization reducing the non-significant ones to zero or near-zero). Following from that, the purpose of scan tables is to find a path through the 2-dimensional array of coefficients that is most likely to find all non-zero coefficients while encountering as few zero coefficients as possible. Classically, most video codecs (such as H.264) use scan tables derived from the zig-zag pattern. VP9, interestingly, uses a slightly different pattern, where scan tables mimic a quarter-circle connecting points ordered by distance to the top/left origin. For example, the 8×8 zig-zag (left) and VP9 (right) scan tables (showing ~20 coefficients) compare like this:


In cases where the horizontal and vertical transform (DCT vs. ADST) are different, the scan table also has a directional bias. The bias stems from the fact that transforms combining ADST and DCT typically concentrate the energy in the ADST direction more than in the DCT direction, since the ADST is the spatial origin of the prediction data. These scan tables are referred to as row (used for ADST vertical + DCT horizontal 2-D transforms) and column (used for ADST horizontal + DCT vertical 2-D transforms) scan tables. For the 8×8 transform, these biased row (left) and column (right) scan tables (showing ~20 coefficients) look like this:

The advantage of the VP9 scan tables, especially at larger transform sizes (32×32 and 16×16) is that it leads to a better separation of zero- and non-zero-coefficients than classic zig-zag or related patterns used in other video codecs.
Loopfilter
The aforementioned processes allow you to compress individual blocks in VP9. However, they also lead to blocking artifacts at the edges between transform blocks and prediction blocks. To resolve that (i.e. smoothen unintended hard edges), VP9 imposes a post-block decoding loopfilter which aims to soften hard block edges. There are 4 separate loopfilters that run at block edges, modifying either 16, 8, 4 or 2 pixels. Smaller transforms allow only small filters, whereas for the largest transforms, all filters are available. Which one runs for each edge depends on filter strength and edge hardness.
On the earlier-used image, the loopfilter effect (contrast increased by ~100x) looks like this:

Arithmetic coding and adaptivity
So far, we’ve comprehensively discussed algorithms used in VP9 block coding and image reconstruction. We have not yet discussed how symbol aggregation into a serialized bitstream works. For this, VP9 uses an binary arithmetic range coder. Each symbol (e.g. an intra mode choice) has a probability table associated with it. These probabilities can either be global defaults, or they can be explicitly updated in the header of each frame (forward updates). Based on the entropy of the decoded data of previous frames, the probabilities are updated before the coding of next frames starts (backward updates). This means that probabilities effectively adapt to data entropy – but without explicit signaling. This is very different from how H.264/HEVC use CABAC, since CABAC uses per-symbol adaptivity (i.e. after each bit, the associated probability is updated – which is useful, especially in intra/keyframe coding) but resets state between frames, which means it can’t take advantage of entropic redundancy between frames. VP9 keeps probabilities constant during the coding of each frame, but maintains state (and adapts probabilities) between frames, which provides compression benefits during long stretches of inter frames.
Summary
The above should give a pretty comprehensive overview of algorithms and designs of the VP9 video codec. I hope it helps in understanding why VP9 performs better than older video codecs, such as H.264. Are you interested in video codecs and would you like to write amazing video encoders? Two Orioles, based in New York, is hiring video engineers!
“I imagined them being these insanely complex beasts that required multiple PhDs to understand.”
So did I, and after reading this blog post, I realize…it’s all true!
– Yours, a history major
Hi, can you recommend some resources to learn further?
I will probably sound pedantic but I think this is actually very important: the Y component, that should be written Y’ to denote its non linearity, does not represent Luminance but Luma which is the weighted sum of non-linearly encoded R’G’B’ components.
I would suggest reading this paper by Charles Poynton: http://www.poynton.com/PDFs/YUV_and_luminance_harmful.pdf
Great article by the way!
Cheers,
Thomas
Cheers,
Thomas
https://en.wikipedia.org/wiki/AOMedia_Video_1
Please do an overview for the AV1 codec too once it’s finalized in March 2017.
Under the Block decomposition subheading do you mean HEVC/h.265 instead of h.264 as written there?
Pingback: Links 14/12/2016: CrossOver 16, GNOME 3.23.3, and KDevelop 4.7.4 released | Techrights
A great overview, and very well written!
One minor correction though: H.264 has nine intra prediction modes, not just four. It’s true that in some cases (specifically, Intra_16x16 and chroma) only four of them are available, but in the commonly used Intra_8x8 and Intra_4x4 modes, the full set (eight directions + DC) can be used.
@Thomas Mansencal, @Johnny Doe and @KeyJ: I made minor edits to address comments, thanks for the suggestions!
Thank you.
I dont know if I need a coffee or an aspirin now, so I’m gonna get both :p
buy a capable 7680×4320 screen …then watch 4k .
that did the trick if you want good picture .
Thank you for this great explanation, video codecs are indeed quite complex and with you it seems almost simple.
I still have a couple of questions about how codecs works :
* You describe here how we store data from one frame to another but frame often change totally in a video. How is this manage ? You can’t use motion vector, the YUV data must be recreate entirely, no ?
* In a 3840 x 2160 video, do we really have 3840 x 2160 luma pixels (even for one frame) or is there a compression algorithm (like PNG ou JPEG) apply on the data to reduice the image size ?
Sorry if I’m missing my point here, it is still a bit vague for me.
@Andreas for “scene changes”, a good encoder will typically insert a keyframe, which doesn’t use any inter prediction, only intra prediction, which only uses edge pixels (left/top) to predict blocks. The top/left block in this frame is predicted by filling in all pixels with the value 128 (for 8 bits/component).
@rbultje : Thank you for your response. After re-reading the intra prediction paragraph, I understand it’s some kind of interpolation based on the surrounded pixels. A bit like what anti aliasing does ? Am I right ?
So we only store the left/top block edge and the rest is “calculated” at runtime ?
Does the complexity and quality of a codec always increase the decoding cost in term of CPU ? I remember the first DivX I’ve seen (like Matrix 1) took like 1.4Gb and was totally crap in term of image quality. But it could be seen with a 500Mhz processor or even less. What is the minimum requirement for VP9 for example ?
@Andreas: I blogged about HEVC vs. H.264 vs. VP9 decoding performance a year ago: https://blogs.gnome.org/rbultje/2015/09/28/vp9-encodingdecoding-performance-vs-hevch-264/(scroll down to “Decoding speed”). Yes, you need more than 500MHz to view a 4K video with reasonable quality. Overall, VP9 doesn’t need significantly more decoding resources than H.264. It’s much more complex (like 2x or so) than DivX, though.
@rbultje : Ok thank you for your explanations. Great articles !
Hi, @rbultje.
I read your article interestingly. I’m researching video decoding with VP9. I’m finding a way to visualize inter-prediction in VP9 like this picture:(https://blogs.gnome.org/rbultje/files/2016/12/146-mvs-closeup.png)
I found the decoder code but still need to get the visualized one. If you don’t mind, could you introduce how to generate the visualization?
(I’m working in NYC as well. Nice to meet you.)
Nice to meet you too! I used AV1/VP9 Analyzer to generate the image:
https://apps.apple.com/us/app/av1-analyzer/id1486081469?mt=12