In multimedia, we often write vector assembly (SIMD) implementations of computationally expensive functions to make our software faster. At a high level, there are three basic approaches to write assembly optimizations (for any architecture):
- intrinsics;
- inline assembly;
- hand-written assembly.
Inline assembly is typically disliked because of its poor readability and portability. Intrinsics hide complex stuff (like register count or stack memory) from you, which makes writing optimizations easier, but at the same time typically carries a performance penalty (because of poor code generation by compilers) – compared to hand-written (or inline) assembly. x86inc.asm is a helper developed originally by various x264 developers, licensed under the ISC, which aims to make writing hand-written assembly on x86 easier. Other than x264, x86inc.asm is also used in libvpx, libaom, x265 and FFmpeg.
This guide is intended to serve as an introduction to x86inc.asm for developers (somewhat) familiar with (x86) vector assembly (either intrinsics or hand-written assembly), but not familiar with x86inc.asm.
Basic example of how to use x86inc.asm
To explain how this works, it’s probably best to start with an example. Imagine the following C function to calculate the SAD (sum-of-absolute-differences) of a 16×16 block (this would typically be invoked as distortion metric in a motion search):
#include <stddef.h>
#include <stdint.h>
#include <stdlib.h>
typedef uint8_t pixel;
static unsigned sad_16x16_c(const pixel *src, ptrdiff_t src_stride,
const pixel *dst, ptrdiff_t dst_stride)
{
unsigned sum = 0;
int y, x;
for (y = 0; y < 16; y++) {
for (x = 0; x < 16; x++)
sum += abs(src[x] - dst[x]);
src += src_stride;
dst += dst_stride;
}
return sum;
}
In x86inc.asm syntax, this would look like this:
%include "x86inc.asm"
SECTION .text
INIT_XMM sse2
cglobal sad_16x16, 4, 7, 5, src, src_stride, dst, dst_stride, \
src_stride3, dst_stride3, cnt
lea src_stride3q, [src_strideq*3]
lea dst_stride3q, [dst_strideq*3]
mov cntd, 4
pxor m0, m0
.loop:
mova m1, [srcq+src_strideq*0]
mova m2, [srcq+src_strideq*1]
mova m3, [srcq+src_strideq*2]
mova m4, [srcq+src_stride3q]
lea srcq, [srcq+src_strideq*4]
psadbw m1, [dstq+dst_strideq*0]
psadbw m2, [dstq+dst_strideq*1]
psadbw m3, [dstq+dst_strideq*2]
psadbw m4, [dstq+dst_stride3q]
lea dstq, [dstq+dst_strideq*4]
paddw m1, m2
paddw m3, m4
paddw m0, m1
paddw m0, m3
dec cntd
jg .loop
movhlps m1, m0
paddw m0, m1
movd eax, m0
RET
That’s a whole lot of stuff. The critical things to understand in the above example are:
- functions (symbols) are declared by cglobal;
- we don’t refer to vector registers by their official typed name (e.g.
mm0, xmm0, ymm0 or zmm0), but by a templated name (m0) which is generated in INIT_*;
- we use
mova, not movdqa, to move data between registers or from/to memory;
- we don’t refer to general-purpose registers by their official name (e.g.
rdi or edi), but by a templated name (e.g. srcq), which is generated (and populated) in cglobal – unless it is to store return values (eax);
- use
RET (not ret!) to return.
- in your build system, this would be treated like any other hand-written assembly file, so you’d build an object file using
nasm or yasm.
Let’s explore and understand all of this in more detail.
Understanding INIT_*, cglobal, DEFINE_ARGS and RET
INIT_* indicates what type of vector registers we want to use: MMX (mm0), SSE (xmm0), AVX (ymm0) or AVX-512 (zmm0). The invocation also allows us to target a specific CPU instruction set (e.g. ssse3 or avx2). This has various features:
- templated vector register names (
m0) which mirror a specific class of registers (mm0, xmm0, ymm0 or zmm0);
- templated instruction names (e.g.
psadbw) which can warn if we’re using instructions unsupported for the chosen set (e.g. pmulhrsw in SSE2 functions);
- templated instruction names also hide VEX-coding (
vpsadbw vs. psadbw) when targeting AVX;
- aliases for moving data to or from full aligned (
mova, which translates to movq for mm, (v)movdqa for xmm or vmovdqa for ymm registers), full unaligned (movu) or half (movh) vector registers;
- convenience aliases
mmsize and gprsize to indicate the size (in bytes) of vector and general-purpose registers.
For example, to write an AVX2 function using ymm registers, you’d use INIT_YMM avx2. To write a SSSE3 function using xmm registers, you’d use INIT_XMM ssse3. To write a “extended MMX” (the integer instructions introduced as part of SSE) function using mm registers, you’d use INIT_MMX mmxext. Finally, for AVX-512, you use INIT_ZMM avx512.
cglobal indicates a single function declaration. This has various features:
- portably declaring a global (exported) symbol with project name prefix and instruction set suffix;
- portably making callee-save general-purpose registers available (by pushing their contents to the stack);
- portably loading function arguments from stack into general-purpose registers;
- portably making callee-save
xmm vector registers available (on Win64);
- generating named and numbered general-purpose register aliases whose mapping to native registers is optimized for each particular target platform;
- allocating aligned stack memory (see “Using stack memory”).
The sad_16x16 function declared above, for example, had the following cglobal line:
cglobal sad_16x16, 4, 7, 5, src, src_stride, dst, dst_stride, \
src_stride3, dst_stride3, cnt
Using the first argument (sad_16x16), this creates a global symbol <prefix>_sad_16x16_sse2() which is accessible from C functions elsewhere. The prefix is a project-wide setting defined in your nasm/yasm build flags (-Dprefix=name).
Using the third argument, it requests 7 general-purpose registers (GPRs):
- on x86-32, where only the first 3 GPRs are caller-save, this would push the contents of the other 4 GPRs to the stack, so that we have 7 GPRs available in the function body;
- on unix64/win64, we have 7 or more caller-save GPRs available, so no GPR contents are pushed to the stack.
Using the second argument, 4 GPRs are indicated to be loaded with function arguments upon function entry:
- on x86-32, where all function arguments are transferred on the stack, this means that we
mov each argument from the stack into an appropriate register;
- on win64/unix64, the first 4/6 arguments are transferred through GPRs (
rdi, rsi, rdx, rcx, R8, R9 on unix64; rcx, rdx, R8, R9 on win64), so no actual mov instructions are needed in this particular case.
This should also explain why we want to use templated register names instead of their native names (e.g. rdi), since we want the src variable to be kept in rcx on win64 and rdi on unix64. At this level inside x86inc.asm, these registers have numbered aliases (r0, r1, r2, etc.). The specific order in which each numbered register is associated with a native register per target platform depends on the function call argument order mandated by the ABI; then caller-save registers; and lastly callee-save registers.
Lastly, using the fourth argument, we indicate that we’ll be using 5 xmm registers. On win64, if this number is larger than 6 (or 22 for AVX-512), we’ll be using callee-save xmm registers and thus have to back up their contents to the stack. On other platforms, this value is ignored.
The remaining arguments are named aliases for each GPR (e.g. src will refer to r0, etc.). For each named or numbered register, you’ll notice a suffix (e.g. the q suffix for srcq). A full list of suffixes:
q: qword (on 64-bit) or dword (on 32-bit) – note how q is missing from numbered aliases, e.g. on unix64, rdi = r0 = srcq, but on 32-bit eax = r0 = srcq;d: dword, e.g. on unix64, eax = r6d = cntd, but on 32-bit ebp = r6d = cntd;w: word, e.g. on unix64 ax = r6w = cntw, but on 32-bit bp = r6w = cntw;b: (low-)byte in a word, e.g. on unix64 al = r6b = cntb;h: high-byte in a word, e.g. on unix64 ah = r6h = cnth;m: the stack location of this variable, if any, else the dword alias (e.g. on 32-bit [esp + stack_offset + 4] = r0m = srcm);mp: similar to m, but using a qword register alias and memory size indicator (e.g. on unix64 qword [rsp + stack_offset + 8] = r6mp = cntmp, but on 32-bit dword [rsp + stack_offset + 28] = r6mp = cntmp).
DEFINE_ARGS is a way to re-name named registers defined with the last arguments of cglobal. It allows you to re-use the same physical/numbered general-purpose registers under a different name, typically implying a different purpose, and thus allows for more readable code without requiring more general-purpose registers than strictly necessary.
RET restores any callee-save register (GPR or vector) from the stack that was pushed by cglobal, undoes any additional stack memory allocated for custom use (see “Using stack memory”). It will also call vzeroupper to clear the upper half of ymm registers (if invoked with INIT_YMM or higher). At the end, it calls ret to return to the caller.
Templating functions for multiple register types
At this point, it should be fairly obvious why we use templated names (r0 or src instead of rdi (unix64), rcx (win64) or eax (32-bit)) for general-purpose registers: portability. However, we have not yet explained why we use templated names for vector registers (m0instead of mm0, xmm0, ymm0 or zmm0). The reason for this is function templating. Let’s go back to the sad_16x16 function above and use templates:
%macro SAD_FN 2 ; width, height
cglobal sad_%1x%2, 4, 7, 5, src, src_stride, dst, dst_stride, \
src_stride3, dst_stride3, cnt
lea src_stride3q, [src_strideq*3]
lea dst_stride3q, [dst_strideq*3]
mov cntd, %2 / 4
pxor m0, m0
.loop:
mova m1, [srcq+src_strideq*0]
mova m2, [srcq+src_strideq*1]
mova m3, [srcq+src_strideq*2]
mova m4, [srcq+src_stride3q]
lea srcq, [srcq+src_strideq*4]
psadbw m1, [dstq+dst_strideq*0]
psadbw m2, [dstq+dst_strideq*1]
psadbw m3, [dstq+dst_strideq*2]
psadbw m4, [dstq+dst_stride3q]
lea dstq, [dstq+dst_strideq*4]
paddw m1, m2
paddw m3, m4
paddw m0, m1
paddw m0, m3
dec cntd
jg .loop
%if mmsize >= 16
%if mmsize >= 32
vextracti128 xm1, m0, 1
paddw xm0, xm1
%endif
movhlps xm1, xm0
paddw xm0, xm1
%endif
movd eax, xm0
RET
%endmacro
INIT_MMX mmxext
SAD_FN 8, 4
SAD_FN 8, 8
SAD_FN 8, 16
INIT_XMM sse2
SAD_FN 16, 8
SAD_FN 16, 16
SAD_FN 16, 32
INIT_YMM avx2
SAD_FN 32, 16
SAD_FN 32, 32
SAD_FN 32, 64
This indeed generates 9 functions for square and rectangular sizes for each register type. More could be done to reduce binary size, but for the purposes of this tutorial, the take-home message is that we can use the same source code to write functions for multiple vector register types (mm0, xmm0, ymm0 or zmm0).
Some readers may at this point notice that x86inc.asm allows a programmer to use non-VEX instruction names (such as psadbw) for VEX instructions (such as vpsadbw), since you can only operate on ymm registers using VEX-coded instructions. This is indeed the case, and is discussed in more detail in “AVX three-operand instruction emulation” below. You’ll also notice how we use xm0 at the end of the function, this allows us to explicitly access xmm registers in functions otherwise templated for ymm registers, but will still correctly map to mm registers in MMX functions.
Templating functions for multiple instruction sets
We can also use this same approach to template multiple variants of a function that vary in instruction sets. Consider, for example, the pabsw instruction that was added in SSSE3. You could use templates to write two versions of a SAD version for 10- or 12-bits per pixel component pictures (typedef uint16_t pixel in the C code above):
%macro ABSW 2 ; dst/src, tmp
%if cpuflag(ssse3)
pabsw %1, %1
%else
pxor %2, %2
psubw %2, %1
pmaxsw %1, %2
%endif
%endmacro
%macro SAD_8x8_FN 0
cglobal sad_8x8, 4, 7, 6, src, src_stride, dst, dst_stride, \
src_stride3, dst_stride3, cnt
lea src_stride3q, [src_strideq*3]
lea dst_stride3q, [dst_strideq*3]
mov cntd, 2
pxor m0, m0
.loop:
mova m1, [srcq+src_strideq*0]
mova m2, [srcq+src_strideq*1]
mova m3, [srcq+src_strideq*2]
mova m4, [srcq+src_stride3q]
lea srcq, [srcq+src_strideq*4]
psubw m1, [dstq+dst_strideq*0]
psubw m2, [dstq+dst_strideq*1]
psubw m3, [dstq+dst_strideq*2]
psubw m4, [dstq+dst_stride3q]
lea dstq, [dstq+dst_strideq*4]
ABSW m1, m5
ABSW m2, m5
ABSW m3, m5
ABSW m4, m5
paddw m1, m2
paddw m3, m4
paddw m0, m1
paddw m0, m3
dec cntd
jg .loop
movhlps m1, m0
paddw m0, m1
pshuflw m1, m0, q1010
paddw m0, m1
pshuflw m1, m0, q0000 ; qNNNN is a base4-notation for imm8 arguments
paddw m0, m0
movd eax, m0
movsxwd eax, ax
RET
%endmacro
INIT_XMM sse2
SAD_8x8_FN
INIT_XMM ssse3
SAD_8x8_FN
Altogether, function templating allows for making easily-maintainable code, as long as developers understand how templating works and what the goals are. Templating can partially hide complexity of a function in macros, which can be very confusing and thus make code harder to understand. At the same time, it will significantly reduce source code duplication, which makes code maintenance easier.
AVX three-operand instruction emulation
One of the key features introduced as part of AVX – independent of ymm registers – is VEX encoding, which allows three-operand instructions. Since VEX-instructions (e.g. vpsadbw) in x86inc.asm are defined from non-VEX versions (e.g. psadbw) for templating purposes, the three-operand instruction support actually exists in the non-VEX versions, too. Therefore, code like this (to interleave vertically adjacent pixels) is actually valid:
[..]
mova m0, [srcq+src_strideq*0]
mova m1, [srcq+src_strideq*1]
punpckhbw m2, m0, m1
punpcklbw m0, m1
[..]
An AVX version of this function (using xmm vector registers, through INIT_XMM avx) would translate this literally to the following on unix64:
[..]
vmovdqa xmm0, [rdi]
vmovdqa xmm1, [rdi+rsi]
vpunpckhbw xmm2, xmm0, xmm1
vpunpcklbw xmm0, xmm0, xmm1
[..]
On the other hand, a SSE2 version of the same source code (through INIT_XMM sse2) would translate literally to the following on unix64:
[..]
movdqa xmm0, [rdi]
movdqa xmm1, [rdi+rsi]
movdqa xmm2, xmm0
punpckhbw xmm2, xmm1
punpcklbw xmm0, xmm1
[..]
In practice, as demonstrated earlier, AVX/VEX emulation also allows using the same (templated) source code for pre-AVX functions and AVX functions.
Using SWAP
Another noteworthy feature in x86inc.asm is SWAP, a assembler-time and instruction-less register swapper. The typical use case for this is to be numerically consistent in ordering data in vector registers. As an example: SWAP 0, 1 would switch the assembler’s internal meaning of the templated vector register names m0 and m1. Before, m0 might refer to xmm0 and m1 might refer to xmm1; after, m0 would refer to xmm1 and m1 would refer to xmm0.
SWAP can take more than 2 arguments, in which case SWAP is sequentially invoked on each subsequent pair of numbers. For example, SWAP 1, 2, 3, 4 would be identical to SWAP 1, 2, followed by SWAP 2, 3, and finally followed by SWAP 3, 4.
The ordering is re-set at the beginning of each function (in cglobal).
Using stack memory
Using stack memory in hand-written assembly is relatively easy if all you want is unaligned data or if the platform provides aligned stack access at each function’s entry point. For example, on Linux/Mac (32-bit and 64-bit) or Windows (64-bit), the stack upon function entry is guaranteed by the ABI to be 16-byte aligned. Unfortunately, sometimes we need 32-byte alignment (for aligned vmovdqa of ymm register contents), or we need aligned memory on 32-bit Windows. Therefore, x86inc.asm provides portable alignment. The fourth (optional) numeric argument to cglobal is the number of bytes you need in terms of stack memory. If this value is 0 or missing, no stack memory is allocated. If the alignment constraint (mmsize) is greater than that guaranteed by the platform, the stack is manually aligned.
If the stack was manually aligned, there’s two ways to restore the original (pre-aligned) stack pointer in RET, each of which have implications for the function body/implementation:
- if we saved the original stack pointer in a general-purpose register (GPR), we will still have access to the original
m and mp named register aliases in the function body. However, it means that one GPR (the one holding the stack pointer) is not available for other uses in our function body. Specifically, on 32-bit, this would limit the number of available GPRs in the function body to 6. To use this option, specify a positive stack size;
cglobal sad_16x16, 4, 7, 5, 64, src, src_stride, dst, dst_stride, \
src_stride3, dst_stride3, cnt
- if we saved the original stack pointer on the (post-aligned) stack, we will not have access to
m or mp named register aliases in the function body, but we don’t occupy a GPR. To use this option, specify a negative stack size. Note how we write a negative number as 0 - 64, not just -64, because of a bug in some older versions of yasm.
cglobal sad_16x16, 4, 7, 5, 0 - 64, src, src_stride, dst, dst_stride, \
src_stride3, dst_stride3, cnt
After stack memory allocation, it can be accessed using [rsp] (which is an alias for [esp] on 32-bit).
Conclusion
This post was meant as an introduction to x86inc.asm, an x86 hand-written assembly helper, for developers (somewhat) familiar with hand-written assembly or intrinsics. It was inspired by an earlier guide called x264asm.



































































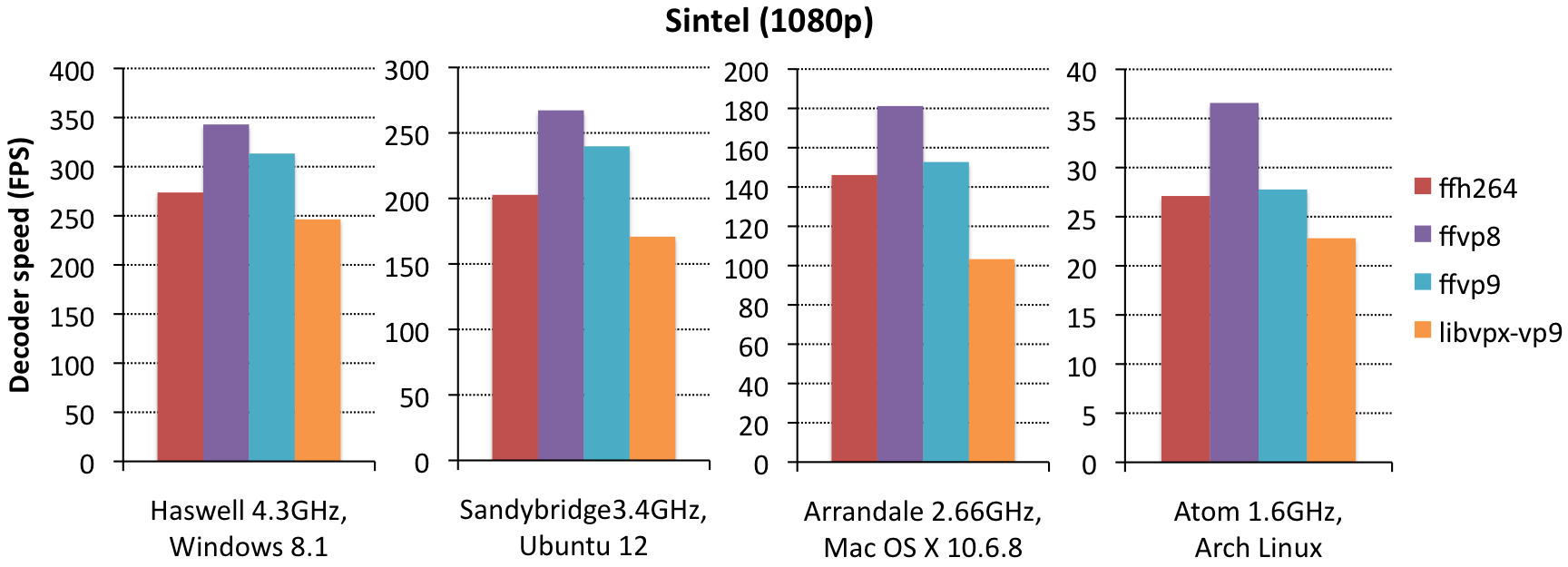
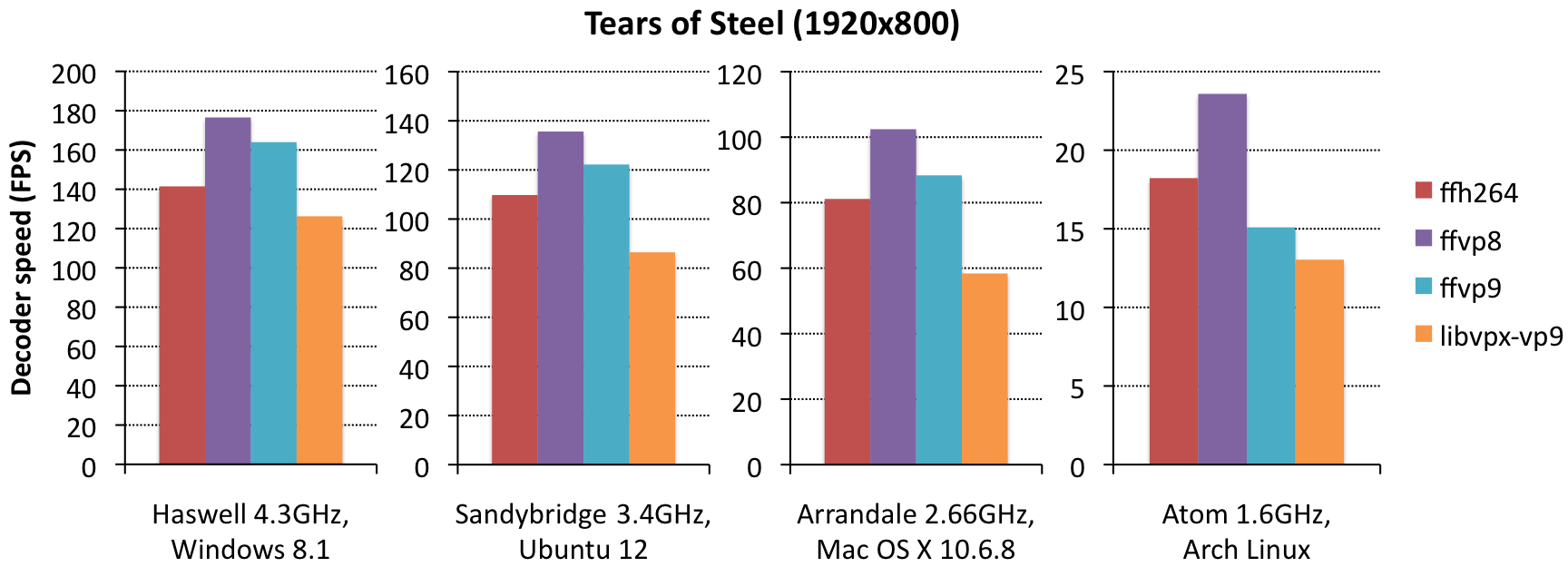
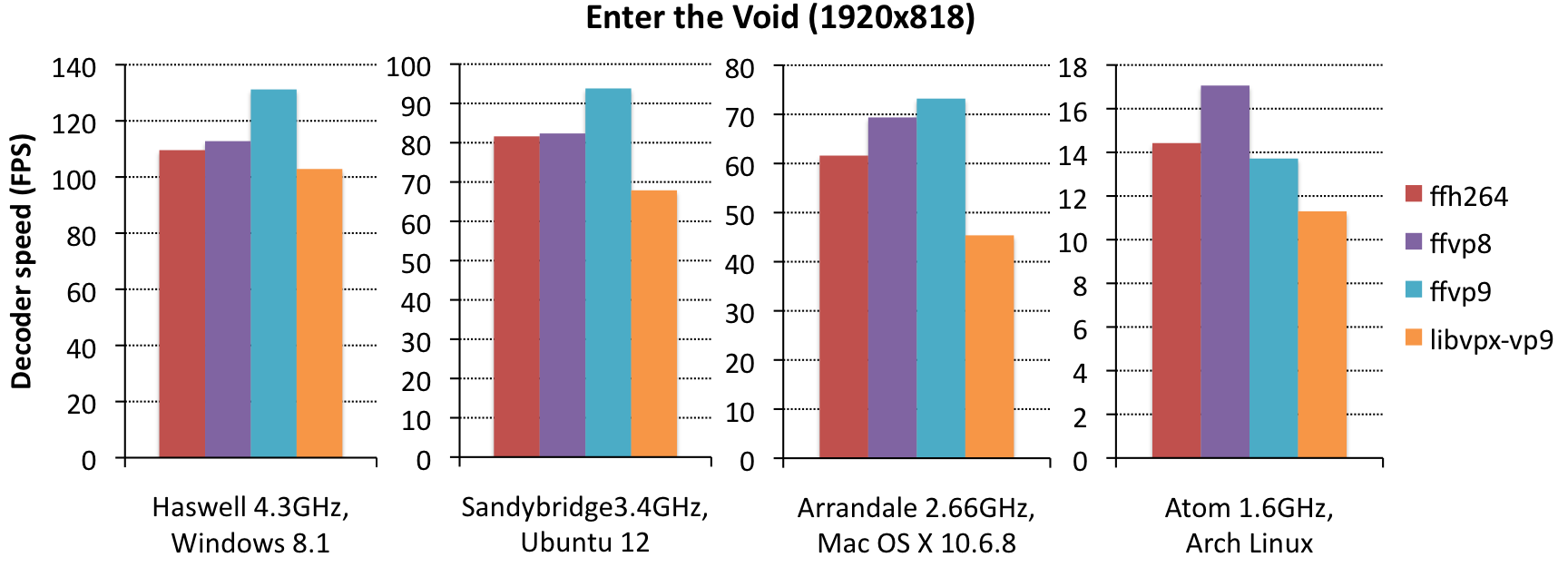
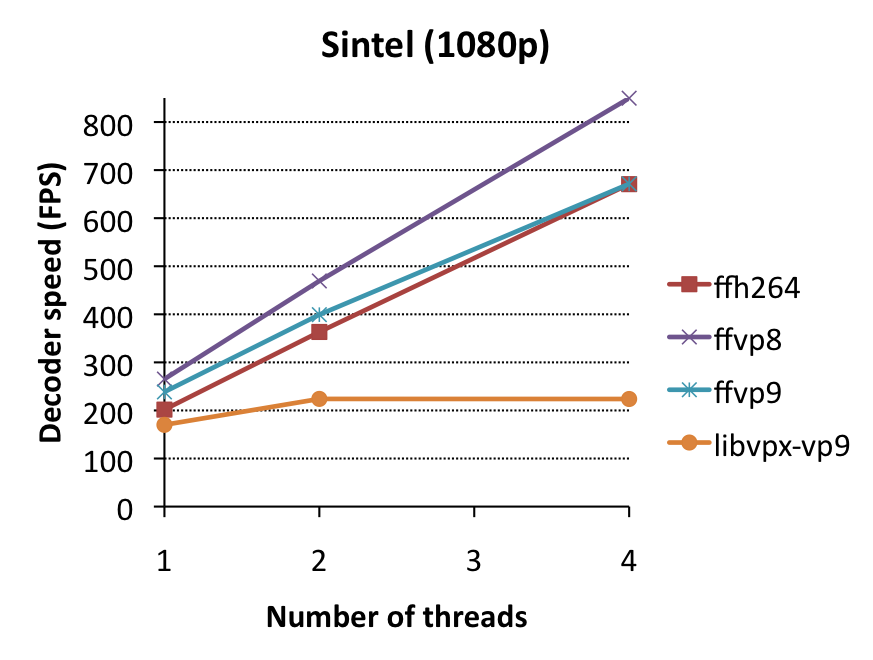

{kind=link}
{kind=link}