
A while ago, I posted about ffvp9, FFmpeg‘s native decoder for the VP9 video codec, which significantly outperforms Google’s decoder (part of libvpx). We also talked about encoding performance (quality, mainly), and showed VP9 significantly outperformed H.264, although it was much slower. The elephant-in-the-room question since then has always been: what about HEVC? I couldn’t address this question back then, because the blog post was primarily about decoders, and FFmpeg’s decoder for HEVC was immature (from a performance perspective). Fortunately, that concern has been addressed! So here, I will compare encoding (quality+speed) and decoding (speed) performance of VP9 vs. HEVC/H.264. [I previously presented this at the Webm Summit and VDD15, and a Youtube version of that talk is available also.]
Encoding quality
The most important question for video codecs is quality. Scientifically, we typically encode one or more video clips using standard codec settings at various target bitrates, and then measure the objective quality of each output clip. The recommended objective metric for video quality is SSIM. By drawing these bitrate/quality value pairs in a graph, we can compare video codecs. Now, when I say “codecs”, I really mean “encoders”. For the purposes of this comparison, I compared libvpx (VP9), x264 (H.264) and x265 (HEVC), each using 2-pass encodes to a set of target bitrates (x264/x265: –bitrate=250-16000; libvpx: –target-bitrate=250-16000) with SSIM tuning (–tune=ssim) at the slowest (i.e. highest-quality) setting (x264/5: –preset=veryslow; libvpx: –cpu-used=0), all forms of threading/tiling/slicing/wpp disabled, and a 5-second keyframe interval. As test clip, I used a 2-minute fragment of Tears of Steel (1920×800).
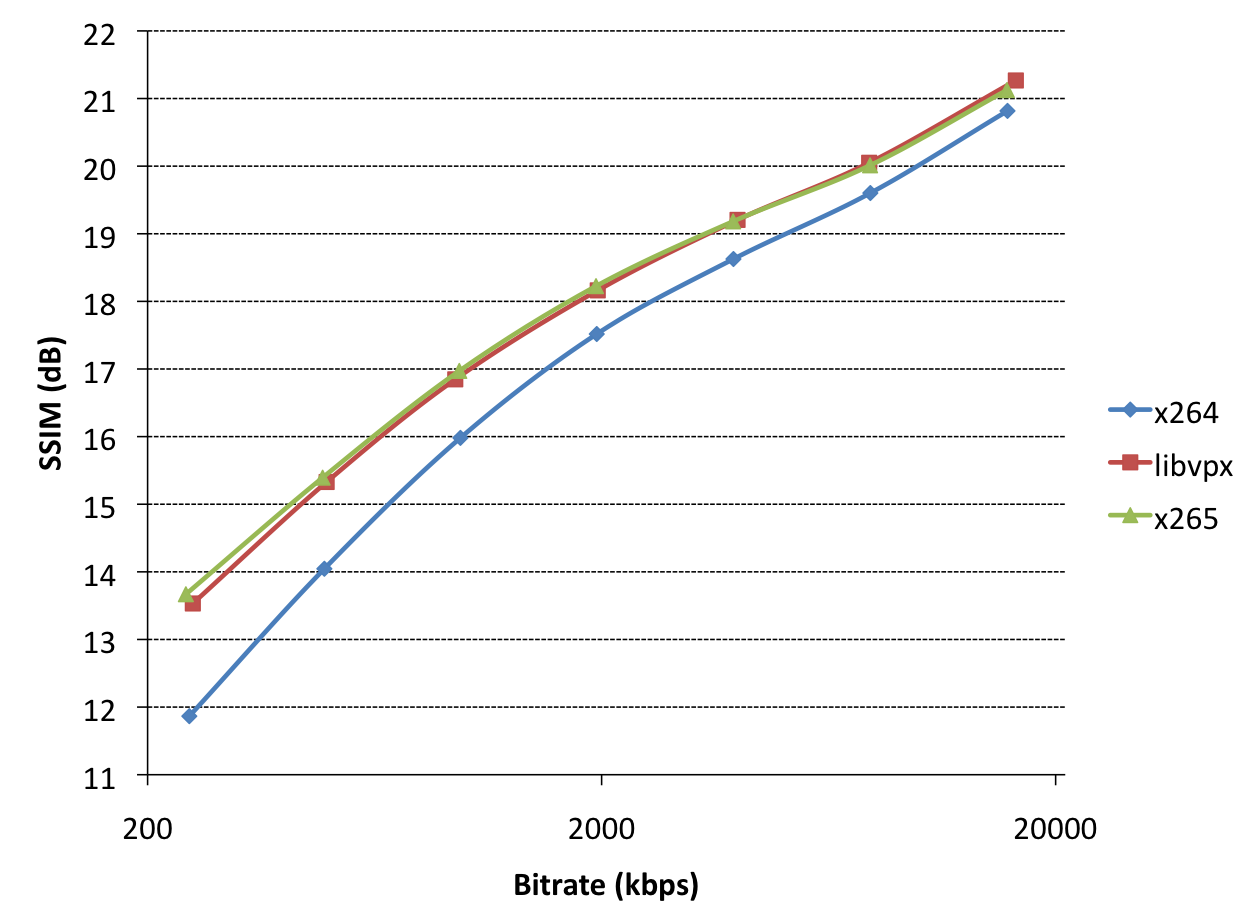
This is a typical quality/bitrate graph. Note that both axes are logarithmic. Let’s first compare our two next-gen codecs (libvpx/x265 as encoders for VP9/HEVC) with x264/H.264: they’re way better (green/ref is left of blue, which means “smaller filesize for same quality”, or alternatively you could say they’re above, which means “better quality for same filesize”). Either way, they’re better. This is expected. By how much? So, we typically try to estimate how much more bits “blue” needs to accomplish the same quality as (e.g.) “red”, by comparing an actual point of red to an interpolated point (at the same SSIM score) of the blue line. For example, the red point at 1960kbps has an SSIM score of 18.16. The blue line has two points at 17.52 (1950) and 18.63 (3900kbps). Interpolation gives an estimated point for SSIM=18.16 around 2920kbps, which is 49% larger. So, to accomplish the same SSIM score (quality), x264 needs 49% more bitrate than libvpx. Ergo, libvpx is 49% better than x264 at this bitrate, this is called the bitrate improvement (%). x265 gets approximately the same improvement over x264 as libvpx at this bitrate. The distance between the red/green lines and blue line get larger as the bitrate goes down, so the codecs have a higher bitrate improvement at low bitrates. As bitrates go up, the improvements go down. We can also see slight differences between x265/libvpx for this clip: at low bitrates, x265 slightly outperforms libvpx. At high bitrates, libvpx outperforms x265. These differences are small compared to the improvement of either encoder over x264, though.
Encoding speed
So, these next-gen codecs sound awesome. Now let’s talk speed. Encoder devs don’t like to talk speed and quality at the same time, because they don’t go well together. Let’s be honest here: x264 is an incredibly well-optimized encoder, and many people still use it. It’s not that they don’t want better bitrate/quality ratios, but rather, they complain that when they try to switch, it turns out these new codecs have much slower encoders, and when you increase their speed settings (which lowers their quality), the gains go away. Let’s measure that! So, I picked a target bitrate of 4000kbps for each encoder, using otherwise the same settings as earlier, but instead of using the slow presets, I used variable-speed presets (x265/x264: –preset=placebo-ultrafast; libvpx: –cpu-used=0-7).
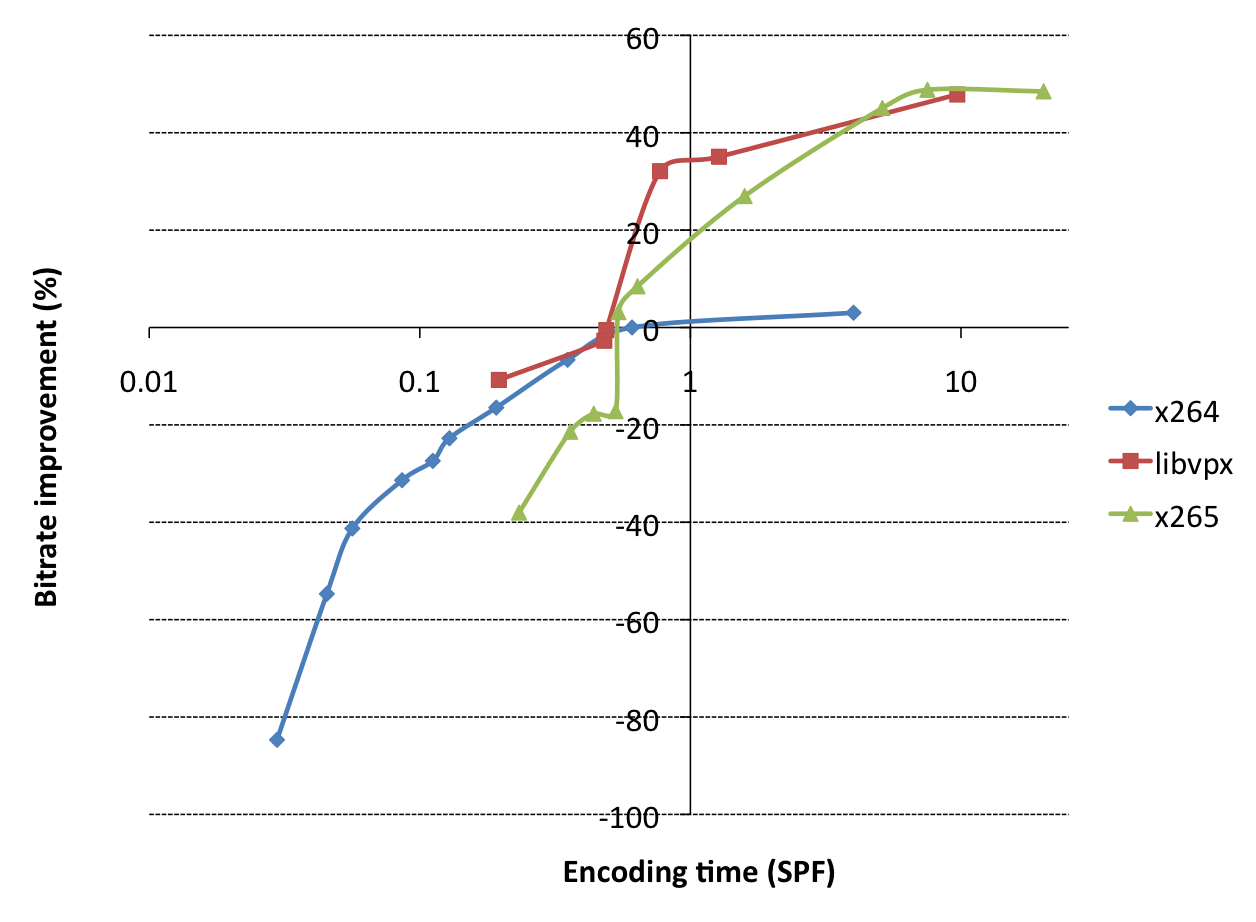
This is a graph people don’t talk about often, so let’s do exactly that. Horizontally, you see encoding time in seconds per frame. Vertically, we see bitrate improvement, the metric we introduced previously, basically a combination of the quality (SSIM) and bitrate, compared to a reference point (x264 @ veryslow is the reference point here, which is why the bitrate improvement over itself is 0%).
So what do these results mean? Well, first of all, yeah, sure, x265/libvpx are ~50% better than x264, as claimed. But, they are also 10-20x slower. That’s not good! If you normalize for equal CPU usage, you’ll notice that (again looking at the x264 point at 0%, 0.61 sec/frame), if you look at intersected points of the red line (libvpx) vertically above it, the bitrate improvement normalized for CPU usage is only 20-30%. For x265, it’s only 10%. What’s worse is that the x265 line actually intersects with the x264 line just left of that. In practice, that means that if your CPU usage target for x264 is anything faster than veryslow, you basically want to keep using x264, since at that same CPU usage target, x265 will give worse quality for the same bitrate than x264. The story for libvpx is slightly better than for x265, but it’s clear that these next-gen codecs have a lot of work left in this area. This isn’t surprising, x264 is a lot more mature software than x265/libvpx.
Decoding speed
Now let’s look at decoder performance. To test decoders, I picked the x265/libvpx-generates files at 4000kbps, and created an additional x264 file at 6500kbps, all of which have an approximately matching SSIM score of around 19.2 (PSNR=46.5). As decoders, I use FFmpeg’s native VP9/H264/HEVC decoders, libvpx, and openhevc. OpenHEVC is the “upstream” of FFmpeg’s native HEVC decoder, and has slightly better assembly optimizations (because they used intrinsics for their idct routines, whereas FFmpeg still runs C code in this place, because it doesn’t like intrinsics).
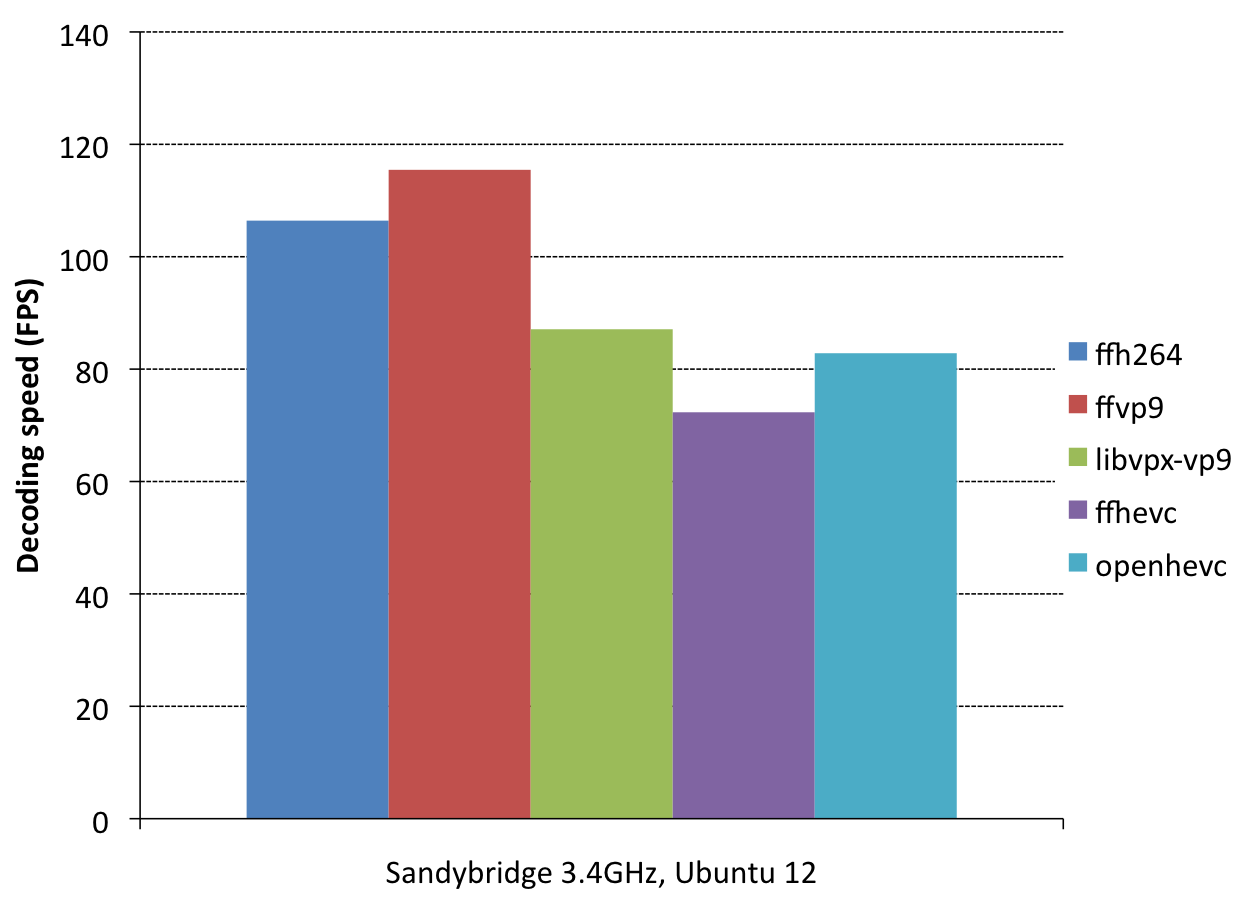
So, what does this mean? Let’s start by comparing ffh264 and ffvp9. These are FFmpeg’s native decoders for H.264 and VP9. They both get approximately the same decoding speed, ffvp9 is in fact slightly faster, by about 5%. Now, that’s interesting. When academics typically speak about next-gen codecs, they claim it will be 50% slower. Why don’t we see that here? The answer is quite simple: because we’re comparing same-quality (rather than same-bitrate) files. Decoders that are this well optimized and mature, tend to spend most of their time in decoding coefficients. If the bitrate is 50% larger, it means you’re spending 50% more time in coefficient decoding. So, although the codec tools in VP9 may be much more complex than in VP8/H.264, the bitrate savings cause us to not spend more time doing actual decoding tasks at the same quality.
Next, let’s compare ffvp9 with libvpx-vp9. The difference is pretty big: ffvp9 is 30% faster! But we already knew that. This is because FFmpeg’s codebase is better optimized than libvpx. This also introduces interesting concepts for potential encoder optimizations: apparently (in theory) we should be able to make encoders that are much better optimized (and thus much faster) than libvpx. Wouldn’t that be nice?
Lastly, let’s compare ffvp9 to ffhevc: VP9 is 55% faster. This is partially because HEVC is much, much, much more complex than VP9, and partially because of the C idct routines in ffhevc. To normalize, we also compare to openhevc (which has idct intrinsics). It’s still 35% slower, so the story for VP9 at this point seems more interesting than for HEVC. A lot of work is left to be done on FFmpeg’s HEVC decoder.
Multi-threaded decoding
Lastly, let’s look at multi-threaded decoding performance:
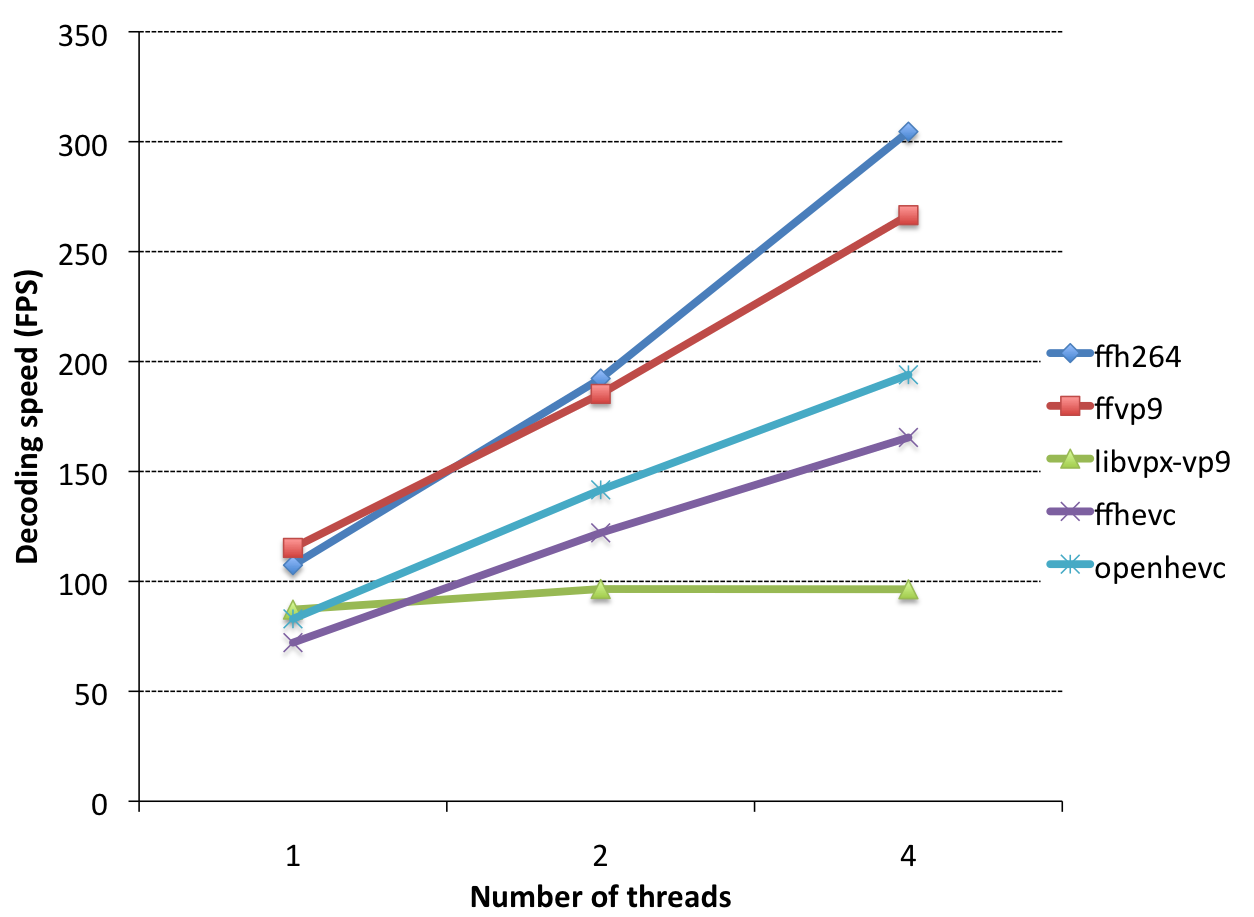
Again, let’s start by comparing ffvp9 with ffh264: ffh264 scales much better. This is expected, the backwards adaptivity feature in VP9 affects multithreaded scaling somewhat, and ffh264 doesn’t have such a feature. Next, ffvp9 versus ffhevc/openhevc: they both scale about the same. Lastly: libvpx-vp9. What happened? Well, when backwards adaptivity is enabled and tiling is disabled in the VP9 bitstream, libvpx doesn’t use multi-threading at all, so I’ll call it a TODO item in libvpx. There is no reason why this is the case, as is proven by ffvp9.
Conclusions
- Next-gen codecs provide 50% bitrate improvements over x264, but are 10-20x as slow at the top settings required to accomplish such results.
- Normalized for CPU usage, libvpx already has some selling points when compared to x264; x265 is still too slow to be useful in most practical scenarios except in very high-end scenarios.
- ffvp9 is an incredibly awesome decoder that outperforms all other decoders.
Lastly, I was asked this question during my VDD15 talk, and it’s fair question so I want to address it here: why didn’t I talk about encoder multi-threading? There’s certainly a huge scope of discussion there (slicing, tiling, frame-multithreading, WPP). The answer is that the primary target of my encoder portion was VOD (e.g. Youtube), and they don’t really care about multi-threading, since it doesn’t affect total workload. If you encode four files in parallel on a 4-core machine and each takes 1 minute, or you encode each of them serially using 4 threads, where each takes 15 seconds, you’re using the full machine for 1 minute either way. For clients of VOD streaming services, this is different, since you and I typically watch one Youtube video at a time.
very nice, thank you! could you please provide some sources to reproduce this tests?
Very interesting and very well explained article. Thanks a lot!
Isn’t it possible that optimizations in the encoders could take advantage of multi-threading more than just a mere parallelization? Meaning that maybe 1 file on 4 cores would take less time than 4 files on 1 core?
Cheers!
You write
> I posted about ffvp9, FFmpeg‘s native for the VP9 video codec
I would formulate that as
> I posted about ffvp9, FFmpeg‘s native video codec for the VP9 video coding format
A codec is a specific encoder/decoder implementation from/to a video coding format. See https://en.wikipedia.org/wiki/Video_coding_format .
I know that there has been some conflation same places in the literature between the two concepts of a video format specification and the actual software/hardware to translate to/from that format. But IMO some consideration should make everyone realize that 1) the two things are quite different 2) the name “codec” should only be applied to the actual implementation.
You mentioned it in the last post, but for anyone looking here: the clip used is 1920×800.
The cpu-time usage is particularly interesting! Sounds like at the moment the hevc isn’t quite there yet. This must have taken considerable time to compute…
x264 has a (considerably slower) 10bit encoding mode that is claimed to improve quality (or decrease bandwidth needs, if you will). It would be interesting to see how much of the advantage of the newer codecs remains in that mode.
I understand that tuning for SSIM results in better scores, but how much systematic measurement error is this introducing? How much does such tuning matter? The extent that tuning really does improve scores (but not perceptual quality) is indicative of how accurate a measure SSIM is; it may well be that all three encoders are indistinguishable after considering measurement inaccuracy.
The dire situation with libvpx just leaves me wondering “What the heck are you doing, Google?”. VP9 is a very decent codec, hold back by its horrible implementations (except for ffvp9, of course).
Wouldn’t it make sense for Mozilla to switch to ffvp9 for VP9 decoding, at least? I often hear complaints about slow video in Firefox, and this should definitely help, even if there are no improvements on the video presentation side of things.
Pingback: Сравнение скорости кодирования и декодирования видео при помощи VP9, HEVC и H.264 | AllUNIX.ru — Всероссийский портал о UNIX-системах
Pingback: VP9 Video vs. H.264/H.265 » GNU Linux România
Pingback: Comparație intre VP9 și H.264/H.265 » GNU Linux România
@Eamon: 10bit is indeed very interesting. The implementation in libvpx should work, although it looks somewhat slow to me. Ffvp9 supports 10/12bit VP9 input, but isn’t fully SIMD-optimized yet, so it wouldn’t be an entirely fair comparison to ffh264 10bit, which has full SIMD coverage. Maybe in about 6 months to 1 year, I’ll write a 10bit comparison between these three codecs (encoder + decoder, same as here).
@Thue and @Colin: post slightly edited for your comments, thanks!
@Braulio: yes, happily! For encoder comparisons, the libvpx revision tested was mentioned in my old blog post (bb61327b98da33471eb760f9ef3bb6fa4cef7cd6). x264/5 revisions are from approximately early June 2015, I don’t recall exact revisions unfortunately. For decoders, we compared libvpx/ffmpeg/openhevc versions from early June 2015 also. Raw data + complete commandlines: https://people.gnome.org/~rbultje/vp9/logs/encoder_data.txt
Thanks, very interesting.
Software decoding speed is still very important today for most users, perhaps a little less tomorrow with the new HW decoding capability ( I have a new little N3150 braswell nuc that can HW decoding 4K 8bit HEVC for example )
But encoding speed will remain critical for the next generation codec. Did you ( or ffmpeg team ) plan to do some ASM code for VP9 because libvpx is really to slow compared to x264 ?
I really miss NEON optimization. ARM SOCs are much cheaper than intels.
I get same speed of x264 encoding on latest Samsung Exinos vs intel celeron for example.
And intel SOCs are much more expensive
I do not get why there is so much mumbling about coding speed. You usually do encoding once per whole file lifetime and then distribute or watch it it at least several times.
So IMHO topmost priority is decode speed and small file size. Encode speed only matters in real time application and VP9 got related modes & tweaks. But needless to say, realtime encode is compromise and since encoder can’t do optimal search and encoding due to time pressure, bitrate to quality ratio is doomed to be worse. But since its one encode – one use it usually not a big deal.
When will ffvp9 start passing all the conformance tests? 🙂 Currently it produces incorrect images with commercial compliance streams.
@Pieter: I’ve been told by people that helped me test this that it passes all Argon streams as of a0d8a81075c0d5119083df9a0cb0be094a4e0190 (2 weeks ago). Are there other sets I missed?
The vp9 encoder having good single thread performance is great. What’s not so good is that it doesn’t scale up that well. It would be lovely to see vp9 in time sensitive applications like livestreaming but it seems unlikely to happen anytime soon. On a more positive note, less of the work needed to make the encoder faster will be needed for vp10.
Are there plans for ARM optimizations?
ffvp9 can easily do 1080p in a circa 2007 Core 2 Duo laptop. Ob the other hand, real-time 720p decoding in Tegra 3 can hardly be achieved without dropping frames.
I had to disable VP9 in YouTube for that reason.
@rbultje: Ah, I have not tried that version. If you are passing all Argon streams then it should be pretty safe to declare it compliant.
@Mohammad AlSaleh: my Neon knowledge is fairly limited, so I guess we’re waiting for a volunteer to write neon optimizations for ffvp9. Libvpx (which is used by Chrome when you play Youtube) has some neon, but may not have full coverage.
Awesome post up, my biggest take away – “50% bitrate improvements over x264, but are 10-20x as slow” – maybe in a few years for me.
VOD encoding does not imply single-threaded. Not everyone uses a worker-per-core model. Besides the real-time/live-streaming mentioned previously, users of desktop tools and workgroup servers usually desire a fast turnaround time. Nonetheless, I can understand Google’s contribution to libvpx does not focus on that since it is not an essential requirement for them.
Excellent news. Ogg has replaced MP3 in video games, Youtube plays HTML5 videos by default, Libre formats are slowly replacing their proprietary counterparts. It’s like fossilization, it happens slowly, but it is happening!
Pingback: Reflections on the First MSU HEVC Encoder Comparison Study Report
Missing vp8 Results 🙁
A nice summary of the issues Ronald.
For the YouTube encoding pipeline, a further reason that multi-threaded encode is less of an issue (even in terms of the turn around time for a single clip), is that longer clips can be broken up into “key frame chunks” that can be encoded separately and then stitched back together. While this can impact compression efficiency by a small amount it scales in a way that is otherwise impossible. In effect even a very long clip can be turned around almost as fast as a clip that is only a few seconds long.
That said, threading is very important to other applications and the libvpx encoder does now support a tile based multi-threaded encoder mode.
For example –tile-columns=2 (this argument a log2 number so 2 actually means 4 tiles) and –threads=4 on a 1080P source, will do 4 thread/tile encoding and is more than twice as fast as single threaded encode.
I agree though that there is still more work to do on the encoder side, to improve the speed / quality trade off.
Pingback: Mark's Corner - Around the web – Highlights Week 40
Previously, I left a rather negative comment. I just want to add that I think the results that VP9 provides is great, and I am glad we all have this as an option. Also (and on behalf of my users) I appreciate the effort @rbultje and others has put into ffvp9. Onward and upward!
Pingback: VP9 encoding/decoding performance vs. HEVC/H.26...
Pingback: TD-Linux comments on “HEVC Video Codecs Comparison” | Exploding Ads
Thanks for posting this–great information!
Few questions:
1. For SSIM scores, how are you computing those across video? I assume SSIM of each frame, and then an average of all frames?
2. Seems like x264 is generally 0.5 to 2.0 dB off libvpx and x265; having worked with SSIM before, I had a very, very hard time visually seeing a difference that small (and particularly in video, where the averaging effect between frames tends to hide a lot). My question is: visually, what do the differences look like?
In my own testing when it’s 3-5 dB off, the difference is discernible, and anything past 5 dB is a landslide. Where I’m getting at with this line of reasoning is if x264 can get within spitting distance of encoding performance for a fraction of the computing cost, why would anyone care about libvpx or x265?
Pingback: Reflections on the First MSU HEVC Encoder Comparison Study Report
@Jeremy N.:
1: ssim error (like sse) is summed across all frames, divided by number of frames, and that number is used to compute ssim-db. See https://ffmpeg.org/doxygen/2.8/tiny__ssim_8c_source.html or https://ffmpeg.org/ffmpeg-filters.html#ssim, I can’t recall which I used, but they work identically.
2: it’s pretty easy to see 1dB, especially at the low-to-middle end of the bitrate spectrum. In terms of percents, I indeed have a hard time seeing 3-5%, but I don’t think that’s what you meant. Anyway, for me, the differences here are very trivial to see, especially at the low-to-middle end. See also this presentation a few years ago: https://www.youtube.com/watch?v=K6JshvblIcM. Having said that, at the high end, it’s indeed harder. It’s still visible, but harder. So maybe that’s why it’s harder for you to see?
As for showing results, I would like to show visual results, but people typically have a lot of “yes, but …” comments when I do. If I show low-to-mid end results, people will complain I should show high-end results because “nobody encodes at the low-to-mid end”. If I show high-end results, the difference is indeed harder to see, and it takes considerable time to explain the differences, which (as you mentioned) makes it all sound much less impressive. Visual differences also don’t lend themselves well for accumulative results, you can’t show 10×3 videos at the same time the way you can show 10 x/y results over 3 codecs in a graph/plot.
But yes, visual to support/backup the graph/number results is nice, and I’ll try to incorporate that into future versions. Thanks for the thoughtful comment!
Pingback: Videokoodekit vertailussa, miten avoimet pakkaajat ja purkajat pärjäävät? | Muropaketti
Why is there no “Multi-threaded encoding”?
I see huge problems there (see lasts post of this time): https://ffmpeg.org/pipermail/ffmpeg-user/2015-November/thread.html
Thanks for the response, @rbultje.
I’ve often wondered if averaging of all video frames for SSIM is correct; it seems like a side-by-side box plot might be revealing, particularly with regard to outliers? By averaging the values, it limits the ability to see how consistently the encoder is performing. I wrote about this on my blog a few years ago: http://goldfishforthought.blogspot.com/2010/05/hd-video-standard-cont.html
Anyway, again, thanks for the info. Very nice work.
x265 reportedly fixed the fast settings so they’re usable now (http://x265.org/performance-presets/)
Thanks for this post
I have tried the vp9 codec in real life with 4K video and I have to say that although it appears around 20% faster than h265 it compresses around 20% less too.
On a Mac it struggles to decoder with a quad core i7 3.4 ghz and seek doesn’t function
I am aware that Ffmpeg-ffvp9has sever bugs and I have not seen any real progress
It would appear that vp9 has already been pronounced dead waiting for vp10 that will address the issues
Meanwhile Google has disabled YouTube on 2013 to sets what a shameful decision
According to my experience with vpxenc (v1.3.0) on Amazon machines (c4.3large), vpxenc is single-threaded in virtue. Switching on tiles and threads in the command line does not impact on performance (always only one core is working).
On the other hand x265 can be parallized (with –wpp and –threads) on many cores.
Even if in-built HEVC features like WPP or Tiles are off x265 can be configured to exploit the frame-level parallelization (controlled with –frame-threads).
In my opinion without multi-threading mode vpxenc loom inferior to x265 (even if SSIM scores are comparable)
Pingback: ju-st comments on "H.265/HEVC vs. H.264/AVC: 50% bit rate savings verified"
One major mistake:
“x264 needs 49% more bitrate than libvpx. Ergo, libvpx is 49% better than x264” – no, if something is 50% bigger then the other, this doesn’t mean the other is 50% smaller then the first: 20+50%=30; 30-50%=15 🙂 libvpx is only 1/3 better (2920-1960=960; 960/2920 equals roughly 1/3).