
As before, I was very excited when Google released VP9 – for one, because I was one of the people involved in creating it back when I worked for Google (I no longer do). How good is it, and how much better can it be? To evaluate that question, Clément Bœsch and I set out to write a VP9 decoder from scratch for FFmpeg. The goals never changed from the original ffvp8 situation (community-developed, fast, free from the beginning). We also wanted to answer new questions: how does a well-written decoder compare, speed-wise, with a well-written decoder for other codecs? TLDR (see rest of post for details):
- as a codec, VP9 is quite impressive – it beats x264 in many cases. However, the encoder is slow, very slow. At higher speed settings, the quality gain melts away. This seems to be similar to what people report about HEVC (using e.g. x265 as an encoder).
- single-threaded decoding speed of libvpx isn’t great. FFvp9 beats it by 25-50% on a variety of machines. FFvp9 is somewhat slower than ffvp8, and somewhat faster than ffh264 decoding speed (for files encoded to matching SSIM scores).
- Multi-threading performance in libvpx is deplorable, it gains virtually nothing from its loopfilter-mt algorithm. FFvp9 multi-threading gains nearly as much as ffh264/ffvp8 multithreading, but there’s a cap (material-, settings- and resolution-dependent, we found it to be around 3 threads in one of our clips although it’s typically higher) after which further threads don’t cause any more gain.
The codec itself
To start, we did some tests on the encoder itself. The direct goal here was to identify bitrates at which encodings would give matching SSIM-scores so we could do same-quality decoder performance measurements. However, as such, it also allows us to compare encoder performance in itself. We used settings very close to recommended settings for VP8, VP9 and x264, optimized for SSIM as a metric. As source clips, we chose Sintel (1920×1080 CGI content, source), a 2-minute clip from Tears of Steel (1920×800 cinematic content, source), and a 3-minute clip from Enter the Void (1920×818 high-grain/noise content, screenshot). For each, we encoded at various bitrates and plotted effective bitrate versus SSIM.
{kind=link}
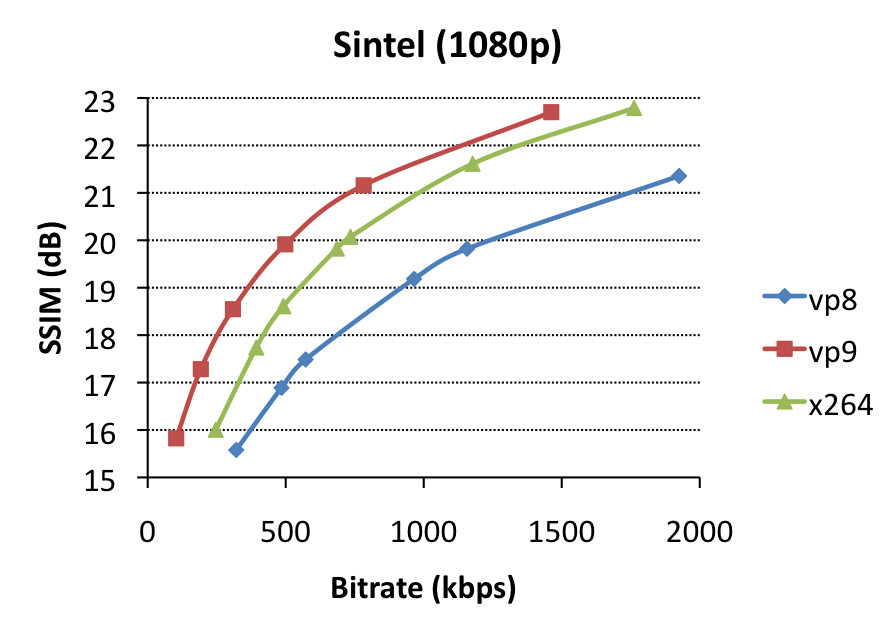
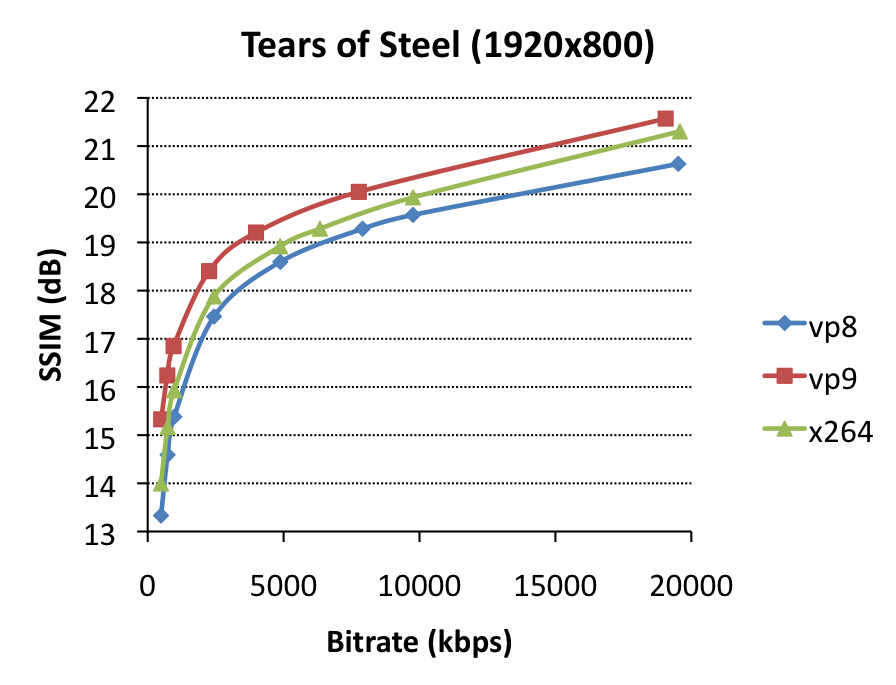
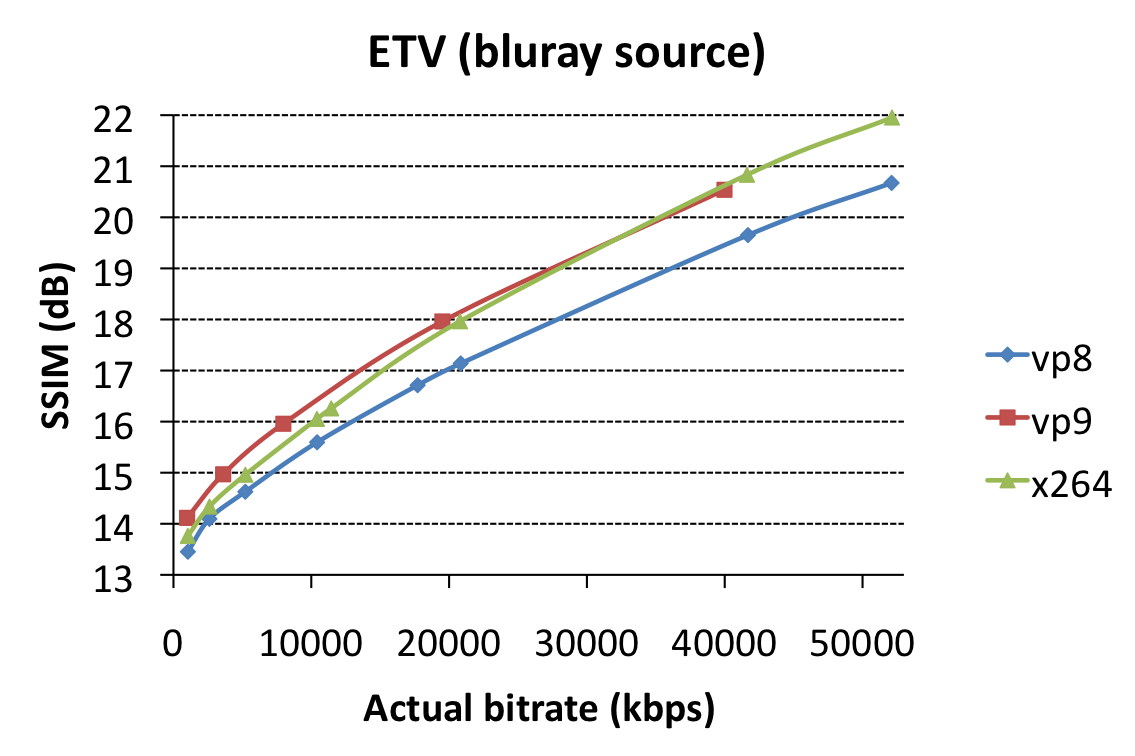
You’ll notice that in most cases, VP9 can indeed beat x264, but, there’s some big caveats:
- VP9 encoding (using libvpx) is horrendously slow – like, 50x slower than VP8/x264 encoding. This means that encoding a 3-minute 1080p clip takes several days on a high-end machine. Higher –cpu-used=X parameters make the quality gains melt away.
- libvpx’ VP9 encodes miss the target bitrates by a long shot (100% off) for the ETV clip, possibly because of our use of –aq-mode=1.
- libvpx tends to slowly decay towards normal at higher bitrates for hard content – again, look at the ETV clip, where x264 shows some serious mature killer instinct at the high bitrate end of things. [edit 6/3/’14: original results showed x264 beating libvpx by a lot at high bitrates, but the source had undergone double compression itself so we decided to re-do these experiments – thanks to Clement for picking up on this.]
{kind=link}
Overall, these results are promising, although the lack-of-speed is a serious issue.
Decoder performance
For decoding performance measurements, we chose (Sintel) 500 (VP9), 1200 (VP8) and 700 (x264) kbps (SSIM=19.8); Tears of Steel 4.0 (VP9), 7.9 (VP8) and 6.3 (x264) mbps (SSIM=19.2); and Enter the Void 9.7 (VP9), 16.6 (VP8) and 10.7 (x264) mbps (SSIM=16.2). We used FFmpeg to decode each of these files, either using the built-in decoder (to compare between codecs), or using libvpx-vp9 (to compare ffvp9 versus libvpx). Decoding time was measured in seconds using “time ffmpeg -threads 1 [-c:v libvpx-vp9] -i $file -f null -v 0 -nostats – 2>&1 | grep user”, with this FFmpeg and this libvpx revision (downloaded on Feb 20th, 2014).
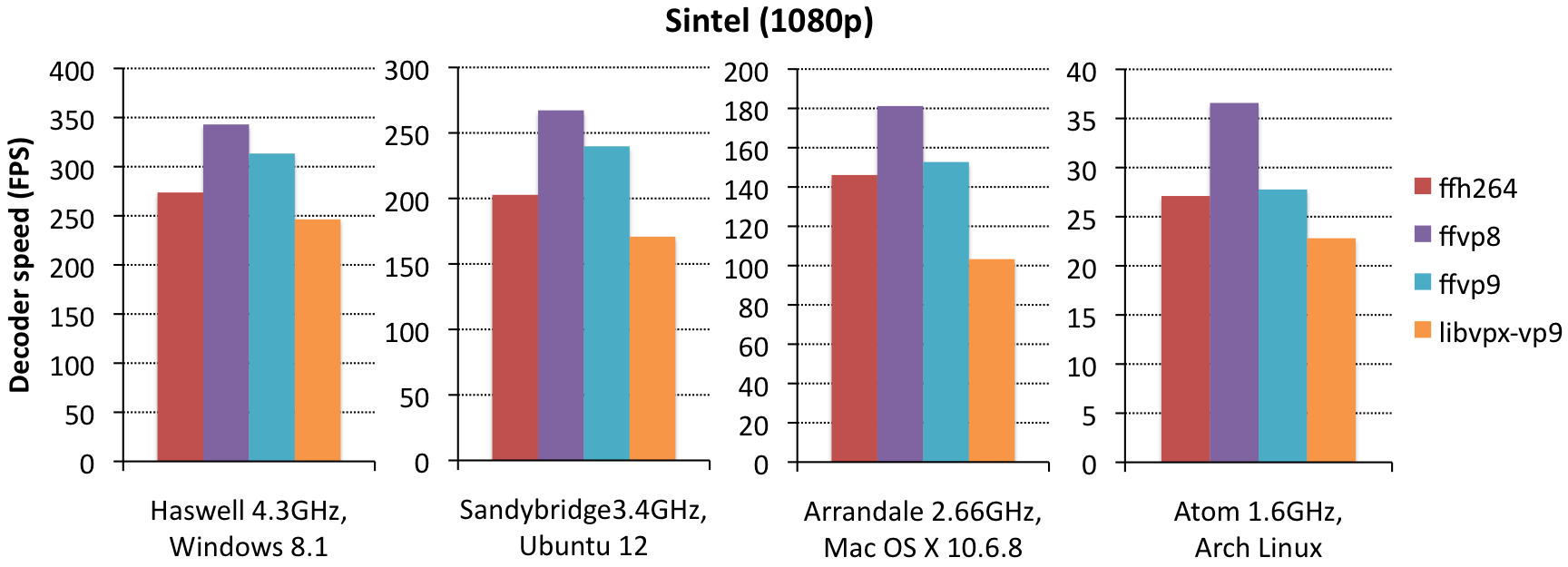
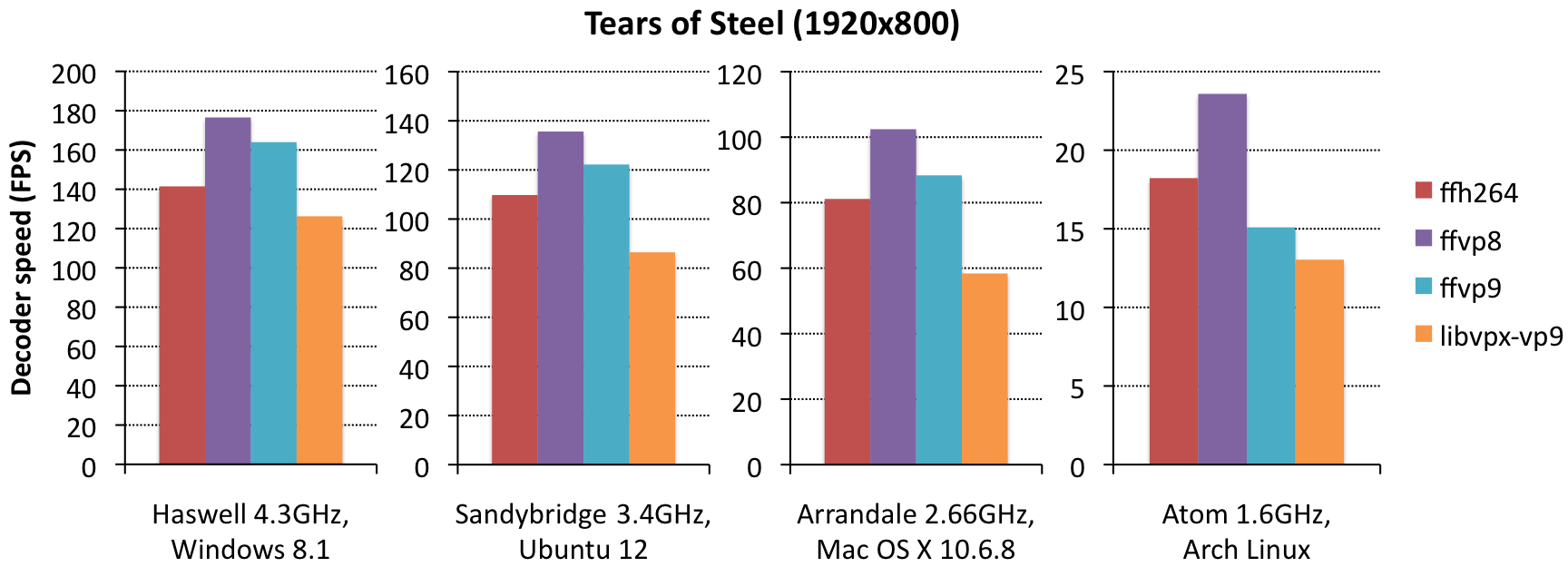
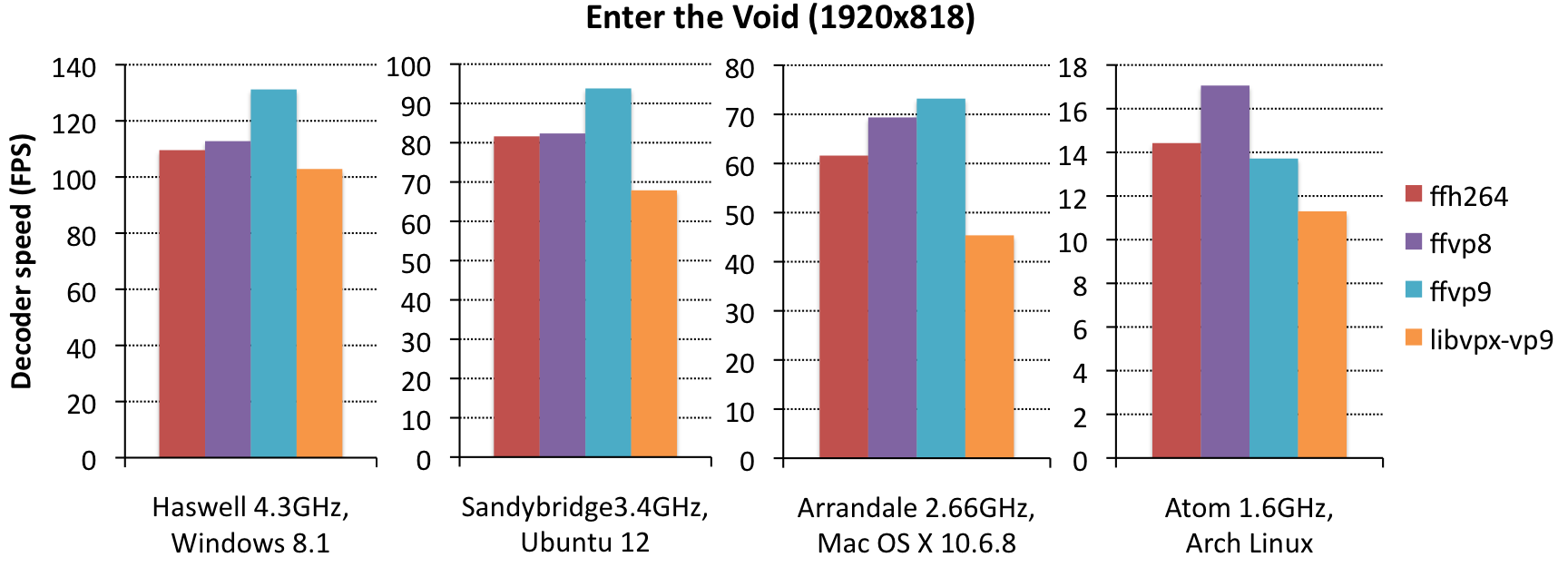
A few notes on ffvp9 vs. libvpx-vp9 performance:
- ffvp9 beats libvpx consistently by 25-50%. In practice, this means that typical middle- to high-end hardware will be able to playback 4K content using ffvp9, but not using libvpx. Low-end hardware will struggle to playback even 720p content using libvpx (but do so fine using ffvp9).
- on Haswell, the difference is significantly smaller than on sandybridge, likely because libvpx has some AVX2 optimizations (e.g. for MC and loop filtering), whereas ffvp9 doesn’t have that yet; this means this difference might grow over time as ffvp9 gets AVX2 optimizations also.
- on the Atom, the differences are significantly smaller than on other systems; the reason for this is likely that we haven’t done any significant work on Atom-performance yet. Atom has unusually large latencies between GPRs and XMM registers, which means you need to take special care in ordering your instructions to prevent unnecessary halts – we haven’t done anything in that area yet (for ffvp9).
Some users may find that ffvp9 is a lot slower than advertised on 32bit; this is correct, most of our SIMD only works on 64bit machines. If you have 32bit software, port it to 64bit. Can’t port it? Ditch it. Nobody owns 32bit x86 hardware anymore these days.[Edit: as of 12/27/2014, all ffvp9 optimizations work on 32-bit, and baseline has moved from SSSE3 to SSE2.]
So how does VP9 decoding performance compare to that of other codecs? There’s basically two ways to measure this: same-bitrate (e.g. a 500kbps VP8 file vs. a 500kbps VP9 file, where the VP9 file likely looks much better), or same-quality (e.g. a VP8 file with SSIM=19.2 vs. a VP9 file with SSIM=19.2, where the VP9 file likely has a much lower bitrate). We did same-quality measurements, and found:
- ffvp9 tends to beat ffh264 by a tiny bit (10%), except on Atom (which is likely because ffh264 has received more Atom-specific attention than ffvp9).
- ffvp9 tends to be quite a bit slower than ffvp8 (15%), although the massive bitrate differences in Enter the Void actually makes it win for that clip (by about 15%, except on Atom). Given that Google promised VP9 would be no more than 40% more complex than VP8, it seems they kept that promise.
- we did some same-bitrate comparisons, and found that x264 and ffvp9 are essentially identical in that scenario (with x264 having slightly lower SSIM scores); vp8 tends to be about 50% faster, but looks significantly worse.
Multithreading
One of the killer-features in FFmpeg is frame-level multithreading, which allows multiple cores to decode different video frames in parallel. Libvpx also supports multithreading. So which is better?
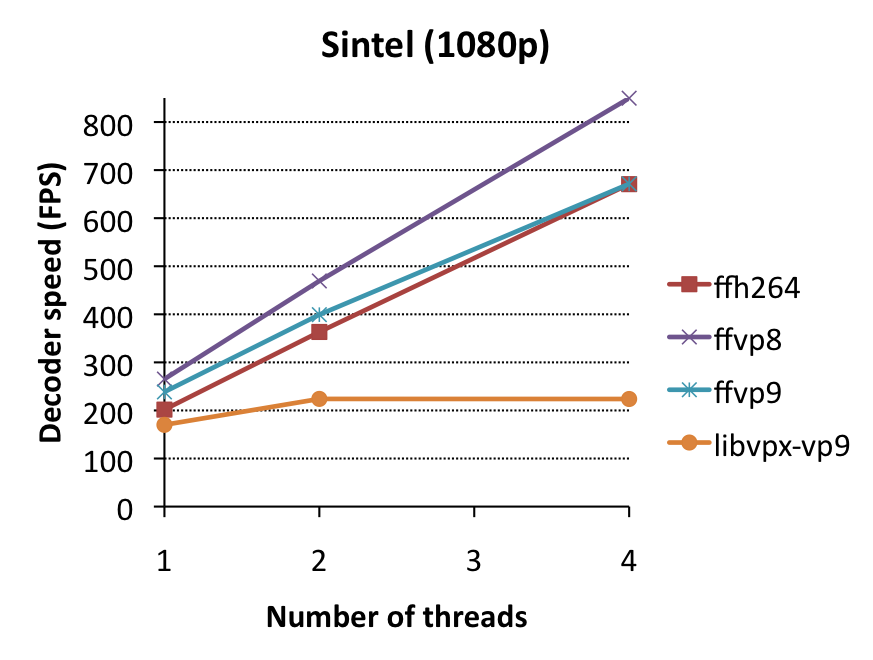
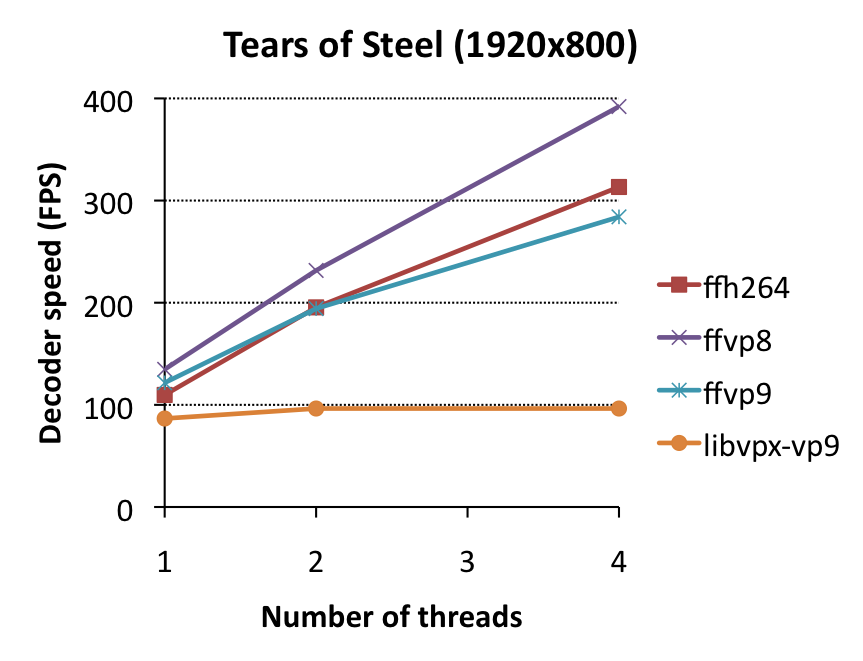
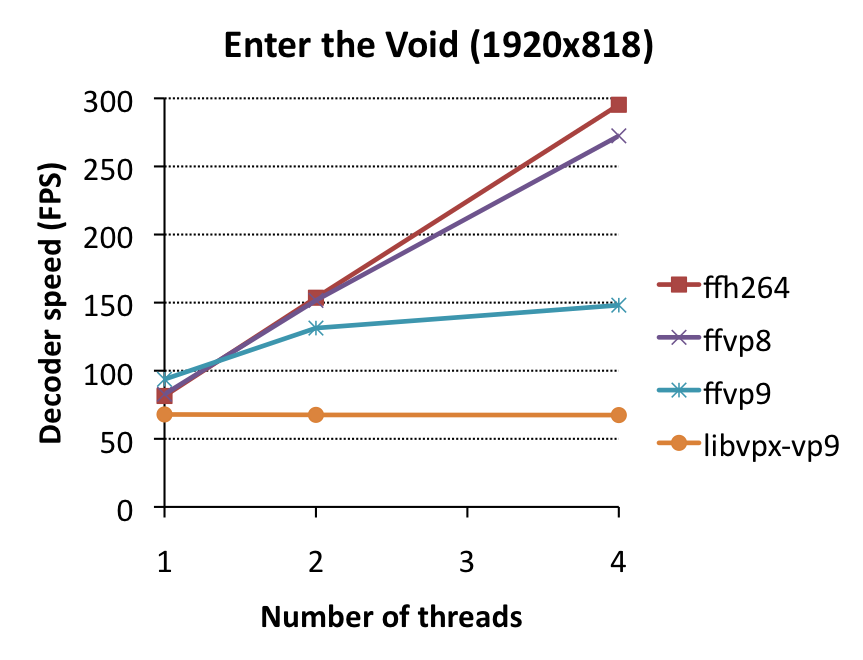
Some things to notice:
- libvpx multithreading performance is deplorable. It gains virtually nothing. This is likely because libvpx’ VP9 decoder supports only loopfilter-multithreading (which is enabled here), or tile multithreading, which is only enabled if files are encoded with –frame-parallel (which disables backwards adaptivity, a major source of quality improvement in VP9 over VP8) and –tile-rows=0 –tile-cols=N for N>0 (i.e. only tile columns, but specifically no tile rows). It’s confusing why this combination of restriction exists before tile-multithreading is enabled (in theory, it could be enabled whenever –tile-cols=N for N>0, but for now it looks like libvpx’ decoding performance won’t gain anything from multithreading in most practical settings.
- ffvp9 multithreading performance is mostly on-par with that of ffvp8/ffh264, although it scales slightly less well (i.e. the performance improvement is marginally worse for ffvp9 than for ffvp8/ffh264)…
- … but you’ll notice a serious issue at 4 threads in Enter the Void – suddenly it stops improving. Why? Well, this clip is very noisy and encoded at a high bitrate, which effectively means that there will be many non-zero coefficients, and thus a dispropotionally high percentage of decoding time (as much as 30%) will be spent in coefficient decoding. Remember when I mentioned backwards adaptivity? A practical side-effect of this feature is that the next frame can only start decoding when the previous frame has finished decoding all coefficients (and modes), so that adaptivity updates can actually take place before the next thread starts decoding the next frame. If coefficient decoding takes 30% plus another 5-10% for mode decoding and other overhead, it means 35-40% of processing time is non-reconstruction-related and can’t be parallelized in VP9 – thus performance reaches a ceiling at 2.5-3 threads. The solution? –frame-parallel=1 in the encoder, but then quality will drop.
Next steps
So is ffvp9 “done” now? Well, it’s certainly usable, and has been fuzzed extensively, thus it should be relatively secure (so not to repeat this), but it’s nowhere near done:
- many functions (idct16/32, iadst16, motion compensation, loopfilter) could benefit from AVX2 implementations.
- there’s no SIMD optimizations for non-x86 platforms yet (e.g. arm-neon).
- more special-use-cases like Atom have not been explored yet.
ffvp9 does not yet support SVC or 444. [Edit: as of 05/06/2015, SVC, profile 1 (4:2:2, 4:4:0 ad 4:4:4) and profile 2-3 (10-12 bpp support) are supported.]
But all of this is decoder-only, and the 800-pound gorilla issue for VP9 adoption – at this point – is encoder performance (i.e. speed).
What about HEVC?
Well, HEVC has no optimized, opensource decoder yet, so there’s nothing to measure. It’s coming, but not yet finished. We did briefly look into x265, one of the more popular HEVC encoders. Unfortunately, it suffers from the same basic issue as libvpx: it can be fast, and it can beat x264, but it can’t do both at the same time.
Raw data
See here. Also want to high-five Clément Bœsch for writing the decoder with me, and thank Clément Bœsch (again) and Hendrik Leppkes for helping out with the performance measurements.
Pingback: GNOME presenta el codec ffvp9 para el decodificador de vídeo VP9 el cuál es considerado como "el más rápido del mundo" | Libuntu
Imagine how well that will scale if it could be ported to a gpu where you will be capable to reach at least 200 cores at lower rates. Is it possible ?
There isource optimized open source HEVC Decoder. Its called libde265. See http://www.libde265.org.
Pingback: Cristian Moldovan | FFmpeg VP9 se vrea a fi cel mai rapid codec
How to implement this new codec in browsers to see videos?
@Morris: I think you map kCodecVp9 to AV_CODEC_ID_VP9 in ffmpeg_glue.h in Chrome. For other browsers, I have no idea, I suppose you somehow have to get them to link to ffmpeg but I haven’t tried.
Pingback: FFmpeg的VP9解码器比Google的更快
I would like to point out, that I do own and use an x86 32-bit only laptop and it works fine. I am currently writing from it and I have no plans on ditching it just because it is 5-years old. I do not have problems doing development work such as programming, or even non-professional image editing on it. I had problems playing videos before the decoders got optimized, but these days I can play h264 720p videos on it without frame drops or stalls. Most videos play at a nice sub-90% average CPU usage.
I don’t expect you to optimize decoders for 32bit x86 hardware, but I would like to point out that many of these machines still exist and work. I believe they do serve their purpose well enough and there is no reason to replace them, if you mostly use the computer for web access, some document writing, emailing and such. Many people do not have money to spend on thins they do not need and I think these machines will be used for years to come, before they malfunction, perhaps by different owners.
It would be help me if I had a faster computer, if I used it for professional work, but currently I don’t need it that much and I like my laptop. I can’t compile android on it, because as far as I remember a 64bit x86 computer (with 4GB RAM) is a necessary requirement for building software destined to a 32 ARM system with cca 0.3 – 2 GB RAM, but such is life.
Congrats and nice job! You guys have done a fantastic job with this code, and should be proud!
Pingback: FFmpeg’s VP9 Decoder Faster Than Google’s
Pingback: The world’s fastest VP9 decoder: ffvp9 | ...
Pingback: FFmpeg 的 VP9 解码器比 Google 的更快 | 我爱互联网
Is there any specific reason why you prefered to upstream this to Ffmpeg instead of Libav?
[Speaking for myself here]
> Some users may find that ffvp9 is a lot slower than advertised on 32bit; this is correct, most of our SIMD only works on 64bit machines. If you have 32bit software, port it to 64bit. Can’t port it? Ditch it. Nobody owns 32bit x86 hardware anymore these days.
No mainstream browser on Windows has a 64-bit version, except IE, which doesn’t support VP9 and is probably also LGPL-phobic.
I’d also say in an ABR world that CPU performance at the same visual quality might not be enough, as the adaptive algorithm is going to keep asking for more bits and more pixels until it saturates the available bandwidth unless it’s smart enough to talk to the decoder and renderer to see if it’s falling behind (which I don’t think the mainstream ones do).
@Fabian: Libav is free to take the code and do whatever they want with it, it is LGPL after all. I don’t want to deal with their cosmetics insanity (one ends up spending more time re-indenting the code than it took to originally write the code).
@Alex: maybe Chrome devs should switch to 64bit. If they think 32bit is the future, they whoa to them. They could also assist in porting the relevant 64bit-only x86 assembly to 32bit, or stick with libvpx.
Is it possible to implement these codecs on linux using them by chromium?
Very interesting results you have here, Sir. I’m working on a similar experiment.
Can you please shed some more light on how you got the SSIM values? FFMPEG with the -ssim flag doesn’t seem to be working for me, for vp9.
How may I prove by myself encoding a video with this vp9?
I search internet and not found an usable codec.
Is it possible to work with vp9 in virtualdub?