The last couple of months at Codethink have been an exploration into cross compiling, or rather, cross compiling without the hassle of cross compiling.
In brief, this post is about an experimental technique for cross building operating systems we’ve come up with, in which we use a virtual machine to run the builds, a cross compiler over distccd to do the heavy lifting and a virtfs 9p mount to share the build directory with the guest build slave.
Lets start at the beginning
In a recent post, I showcased a build of GNOME from scratch. This was created using the ybd build tool to build GNOME from Baserock YAML definitions.
Once we had a working system, I was asked if I could repeat that for arm. There was already a build story for building arm with Baserock definitions, but getting off the ground to bootstrap it was difficult, and the whole system needs to be built inside an arm emulator or on arm hardware. We started looking at improving the build story for cross compilation.
We examined a few approaches…
Full traditional cross compile
Some projects, such as yocto or buildroot, provide techniques for cross compiling an entire OS from scratch.
I did a writeup on the complications involved in cross building systems
in this email, but in summary:
- The build process is complex, packages need to be compiled for both the $host and $target all the way up the stack, since modules tend to provide tooling which needs to run on the build host, usually by other modules which depend on it (i.e. icu-config or pkg-config).
- Building involves trickery, one needs to setup the build environment very specifically so that host tools are run in the build scripts of a given module, this setup varies from module to module depending on the kind of build scripts they use.
- The further up the stack you get, the more modules tend to expect a self hosting (or native) build environment. This means there is a lot of friction in maintaining something like buildroot, it can involve in some cases very strange autogen/configure incantations and in worse cases, downstream patches need to be maintained just to get it to work.
- Sometimes you even encounter projects which compile C programs that are not distributed, but only used to generating header files and the like during the build, and often these programs are not compiled specifically with $HOST_CC but directly with $CC.
In any case, this was obviously not a viable option. If one wants to be able to build the bleeding edge on a regular basis, cross compiling all the way up the stack involves too much friction.
The scratchbox2 project
This was an avenue which shows promise indeed. The scratchbox project allows one to setup a build environment that is completely tweaked for optimal build performance, using qemu user mode emulation, and much, much more.
I took a look at the internals PDF document and, while I remain impressed, I just don’t think this is the right fit.
The opening statement of the referred pdf says:
Documenting a system as complex as Scratchbox 2 is not an easy task.
And this is no understatement by any means. Scratchbox’s internal design is extremely difficult to grasp, there are many moving parts and details to this build environment; all of which, at least at face value, I perceive to be potential points of failure.
Scratchbox 2 inserts itself in between the qemu user mode emulator and the host operating system and makes decisions, based on configuration data the user needs to provide, about what tooling can be used during a build, and what paths are really going to be accessed.
In short, scratchbox 2 will sometimes call host tools and run them directly without emulation, and sometimes it will use target tools in user mode emulation, these are managed by a virtual filesystem “view” and both execution modes will see the underlying filesystem in different ways. This way you basically get the fastest solution possible: you run a host cross compiler to build binaries for the target at build time, you run host built coreutils and shells and perl and such at configure time, and if you are well configured, you presumably only ever run target binaries in user emulation when those are tools which were built in your build and need to run during the build.
Scratchbox is what you get when you try to get the maximum performance out of a virtualized native build environment. And it is a remarkable feat, but I have reservations about depending on something as complex as this:
- Will be able to easily repeat the same build I did today in 10 years from now and easily obtain the same result ?
- If something ever goes wrong, will it always be possible to find an engineer who is easily capable of fixing it ?
- When creating entirely new builds, how much effort is going to go into setting up and configuring the scratchbox environment ?
But we’re getting closer, scratchbox2 provides a virtualized environment so that when compiling, your upstream packages believe that they are in a native environment, removing that friction with upstreams and allowing one to upgrade modules without maintaining obscure build instructions and downstream patches.
The Aboriginal Linux project
This is the approach we took as a starting point, it’s not the fastest as a build environment but has some values which align quite nicely with our goals.
What Aboriginal Linux provides, is mostly just a hand full of shell scripts which allow one to bootstrap for a given architecture quite elegantly.
When running the Aboriginal build itself, you just have to tell it what the host and target architectures are, and after the build completes, you end up with the following ingredients:
A statically linked, relocatable $host -> $target cross compiler
This is interesting, you get a gcc which you can untar on any machine
of the given $host architecture and it will compile for $target
A minimal system image to run on the target
This includes:
- A minimal kernel configured for that arch
- Busybox / Toybox for your basic utilities
- Bash for your basic shell utilities
- A native compiler for the target arch
- distcc
- An init.sh to boot the system
A set of scripts to launch your kernel & rootfs under qemu
These scripts are generated for your specific target arch so they “just work”, and they setup the guest so that distcc is plugged into the cross compiler you just built.
A couple of nice things about Aboriginal
Minimal build requirements
Running the Aboriginal scripts and getting a build requires:
ar, as, nm, ranlib, ld, cc, gcc, g++, objdump, make and sh
The build starts out by setting up an environment which has access to these, and only these binaries.
This highly controlled early stage build environment is attractive to me because I think the chances are very high that in 10 years I can launch the same build script and get a working result, this is to be at the very base of our stack.
Elegant configuration for bootstrapping targets
Supporting a target architecture in Aboriginal Linux is a bit tricky but once it’s done it should remain reliable and repeatable.
Aboriginal keeps some target configuration files which are sourced at various stages of the build in order to determine:
- Extra compiler flags for building binutils & gcc and libc
- Extra configuration options for the kernel build
- Magical obscure qemu incantation for bringing up the OS in qemu
Getting a compiler, kernel and emulator tuple to work is a delicate dance of matching up these configurations exactly. Once that is done however, it should basically keep working forever.
The adventure begins
When I started testing things, I first just wanted a proof of concept, lets see if we can build our stack from within the Aboriginal Linux emulator.
In my first attempts, I built all the dependencies I needed to run python and git, which are basically the base requirements for running the ybd build tool. This was pretty smooth sailing except that I had to relocate everything I was building into a home directory (read-only root). By the time I started to build baserock’s definitions though I hit a wall. I, quite innocently, wanted to just go ahead and build glibc with Aboriginal’s compiler, thinking no big deal right ? Boy was I wrong.
First problem was that glibc, seems to care a great deal about what compiler is used to build it, and the last GPLv2 version of gcc was not going to cut it. Surprisingly, the errors I encountered were not about the compiler not supporting a recent C standard or such, it was explicitly about gcc – glibc has a deep longing desire to be compiled with gcc, and a moderately recent version of it at that.
Aboriginal Linux had frozen at the very latest releases (and even git commits) of packages which were still available under GPLv2. It took some convincing but since that toolchain is getting old, Rob Landley agreed that it would be desirable, in a transitional period until llvm is ready, to have an optional build mode allowing one to build Aboriginal Linux using the newer GPLv3 contaminated toolchain.
So, I set myself to work and, hoping that it would just cost me a weekend (wrong again), cooked up a branch which supports an option to compile Aboriginal with GCC 5.3 and binutils 2.25.1. A report of the changes this branch introduced can be found on the aboriginal mailing list.
In this time I became intimately acquainted with building compilers and cross compilers. As I mentioned, Aboriginal has a very neat build model which bootstraps everything, running build.sh basically runs like:
CROSS_COMPILER_HOST=i686 SYSIMAGE_TYPE=ext2 ./build.sh armv5l
So essentially you choose the host arch and target arch (both of which need to have support, i.e. a description file like this one in the aboriginal sources), and then the build runs in stages, sourcing the description files for the said architecture depending on what it’s building along the way.
Because I spent considerable time on this, and am still sufficiently fascinated, I’m going to give a break down of the process here.
1.) Build host tooling
First we create a host directory where we will install tools we want to use during the build, we intentionally symlink to only a few minimal host tools that we require be on your system, these are your host compilers, linkers, a functional shell and make implementation.
Then, we build toybox, busybox, e2fsprogs and distcc, basically any tools which we actually have a chance of running on your host.
2.) Build a stage 1 cross compiler for ${target}
This is the compiler we’re going to use to build everything that is going to run on your target qemu guest image, including of course the native compiler.
In this step we build gcc, musl libc and then gcc again, we build gcc again in order to complete the runtime and get libstdc++.
Previous versions of Aboriginal did not require this second build of gcc, but since GCC folks decided to start using C++, we need a C++ capable cross compiler to build the native compiler.
3.) Build a stage 1 cross compiler for ${host}
This is the first step towards building your statically linked and relocatable cross compiler, which you’ll want to be plugging into distcc and using on any machine of the given ${host} arch.
This step is run in exactly the same way as the previous step, except that we are building a cross compiler from your real host -> ${host}
4.) Build the full ${host} -> ${TARGET} cross compiler
In this stage we will use the cross compiler we built in the previous step, in order to build a cross compiler which runs on ${host} and produces code for ${target}. Neither of these have to be the host arch you are actually running on, you could be building a cross compiler for arm machines to build x86 code on a mips, if you were that sadistic.
In this second stage compiler the setup is a bit different, we start out by compiling musl libc right away and just build gcc once, since we already have a full compiler and we already have musl libc compiled for the target ${host}.
Note: This is actually called a “Canadian Cross”, and no, I was also surprised to find out that it is not named after a tattoo one gets when joining a fringe religious group in Canada.
5.) Build the native compiler
Now, in exactly the same way we build the Canadian Cross, we’re going to build a native compiler using the stage 1 cross compiler for ${target}.
This compiler is cross compiled to run on target, and configured to produce code for the same target, so it is a cross compiled native compiler.
6.) Build the kernel and system image
Finally, we use our stage 1 cross compiler again to compile the kernel which will run in qemu, and the root filesystem which has a few things in it. The root filesystem includes toybox, busybox, make, bash and distcc.
We wrap this up with a few scripts, an init.sh to run on the resulting guest image and a run-emulator.sh script which is generated to just “know” how to properly bring up this guest.
A word on the ccwrap compiler frontend
Before moving on, I should say a word or two about the compiler frontend ccwrap.c.
I mentioned before that the cross compiler Aboriginal creates is statically linked and relocatable. This is achieved with the said frontend to the compiler tooling, who’s purpose in life is to fight GCC’s desire to hard code itself into the location you’ve compiled it to, tooth and nail.
ccwrap counters gcc’s tactics by sitting in place of gcc, cc, g++, c++ and cpp, and figuring out the real location of standard includes and linking stubs, and then calling into the original gcc binaries using a modified set of command line arguments; adding -nostdinc and -nostdlib where necessary, and providing the include paths and stubs to the command line.
This is a violent process, and gcc puts up a good fight, but the result is that the cross compiler you generate can be untarred anywhere on any host of the correct ${host} architecture, and it will just run and create binaries for ${target}, building and linking against musl libc by default (more on libc further down).
To port this all to work with new GCC and binutils versions, I needed to find the right patches for gcc and binutils, these are all mostly upstream already in unreleased versions of gcc and binutils. Then I had to reconstruct the building of the stage 1 compilers so that it builds with C++ support, and finally iron out remaining kinks.
This part was all pretty fun to wrap my head around, hope it was also enjoyable to read about 🙂
The travel from musl libc to glibc
So after all that, we have an Aboriginal Linux setup which is capable of building glibc, but the ride is not over ! When building a whole operating system, there is a small chance that someone out there used C++, if we’re going to distribute a glibc based system, we’re probably also going to want to have a libstdc++ that is actually linked against that glibc.
Well, that was what I was thinking, in fact; it runs deeper than this, gcc itself provides libgcc.a and it’s start/end stubs which compliment the host libc’s start/end stubs, but also provides a shared library and a libgcc_eh.so which need to be linked against the host libc.
In any case, at this stage I was a bit worried that the musl-linked gcc compiler I had might not be capable of building and linking programs against the new glibc. Of course it should work, this is just a standards compliant compiler on one hand and a standard C library on the other, but seeing that gcc / glibc entanglement runs so deeply, we had to be sure.
After some time building and rebuilding glibc and gcc on a puny armv5l qemu emulator I found the magic concoction which makes the build pass. For glibc the build pretty much runs smoothly, you first have to install the appropriate linux kernel includes and tell glibc that –with-headers=/usr/include, lest it tread off the beaten path, and go searching obscure host-triple prefixed paths all on it’s own.
To build the gcc runtimes (so that you get the desired libstdc++), you actually have to build gcc as if you were building a cross compiler.
In the armv5l transition from musl libc to GNU libc, you would tell it that:
--build=armv5l-thingamajiggie-musleabi --host=armv5l-thingamajiggie-musleabi --target=armv5l-thingamajiggie-gnueabi
With this setup, it will build all the host tooling using the existing musl libc which our existing compiler is hardwired to use, but when building the runtimes, it will look into ${prefix} and find the glibc we previously compiled, linking the gcc runtimes against the fresh glibc.
And yeah, it’s actually important to specify ‘-musleabi’ and ‘-gnueabi’ in the host triples specifically, gcc’s build scripts will parse the triples and behave differently depending on what suffix you give it.
In my setup, I did not want to use the new compiler, just the runtimes. So I did a custom install of the gcc runtimes in precisely the way that the aboriginal frontend expects to find them.
At this stage, we can now use environment variables to tell the Aboriginal compiler frontend how to behave, telling it the runtime linker we want to use and where it should look for it’s start stubs and end stubs and such.
Once we have installed glibc and new gcc runtimes into a chroot staging area on the target emulator, we can now set the following env vars:
CCWRAP_DYNAMIC_LINKER=/lib/ld.so CCWRAP_TOPDIR=/usr
And gcc will look for standard headers and library paths in /usr and use the dynamic linker installed by glibc.
Now we can compile C and C++ programs, against glibc and glibc based libstdc++, using our nifty compiler which was built against, and statically linked, to musl libc.
What we have done with this ?
The next step was integrating all of this into the YBD build tool and use the Aboriginal compilers and emulator image to virtually cross-compile baserock definitions from whatever host you are running.
What we have now is a build model that looks something like this:
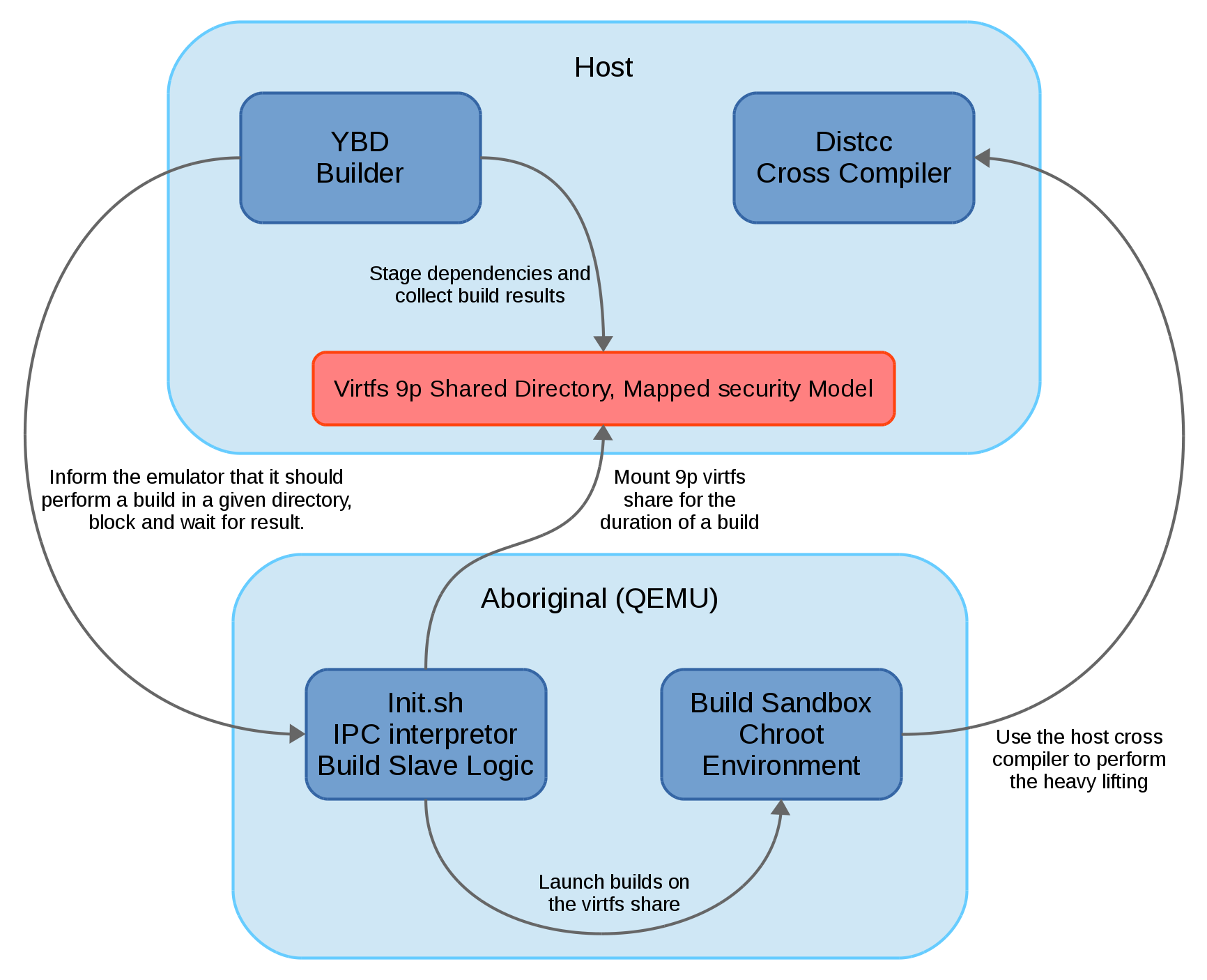
I’ll just take a bit more space here to give a run down of what each component is doing.
YBD Builder
The YBD builder tool remains mostly unchanged in my downstream branch.
Mostly it differs inasmuch as it no longer performs the builds in a chroot sandbox, but instead marshals those builds to slaved Aboriginal guests running in qemu emulators (plural of course, because we want to parallelize the builds as much as dependencies and host resources allow).
What YBD does is basically:
- Clones the sources to be built from git, all sources are normalized into git repositories hosted on the trove.
- Stages dependencies, i.e. results of previous builds into a sysroot in a temporary directory for a build, this is done in the virtfs staging grounds.
- Stages the git repository into the build directory
- Tells a running emulator that it’s time to build
- Waits for the result
- If successful, collects the build results and creates an “artifact” (tarball).
Also, of course YBD parses the YAML definitions format and constructs and navigates a dependency graph.
IPC Interpretor / Modified Init.sh
This component currently lives in the aboriginal controller repository, but should eventually be migrated into the YBD build tool itself as it makes little sense to have this many moving parts.
This is essentially some host side shell scripts, and some guest side shell scripts. The guest is launched in a specific way so as to run in the background and listen to commands over the virtio serial port (this IPC needs to be fixed, it’s a shaky thing and should probably be done over the actual network instead of the serial ports).
Build Sandbox
The build sandbox is just your basic chroot calling shell script, except that it is a bit peculiar in the way it does things.
- It conditionally stages toybox/busybox if and only if tools are not already found in the staging area
- It stages statically linked binaries only and is perfectly operational in the absence of any libc
Well, not all that peculiar I guess.
Virtfs 9p shared directory
Here is another, really fun part of this experimental build process.
Qemu has support for exporting a shared directory which can be accessed by the guest kernel if it is compiled with:
CONFIG_VIRTIO=y CONFIG_VIRTIO_PCI=y CONFIG_VIRTIO_PCI_LEGACY=y CONFIG_NET_9P=y CONFIG_NET_9P_VIRTIO=y
When a guest mounts -t 9p the exported directory, qemu will basically just perform the reads and writes on the guests behalf.
More interestingly, qemu provides a few security models, the basic being passthrough, which just reads and writes using the qemu launching user’s credentials. In any case, qemu can only access the underlying filesystem using the credentials it has. However qemu does provide a security model called “mapped” (or “mapped-file” which we ended up using).
Firstly, of course the shared directory is practical because it allows the host running YBD tool to stage things in the same directory where they will be built by the emulator, but things become interesting when the emulator is installing files under specific uids/gids, or creating device files which should be shipped in the resulting OS – basically anything that normally requires root.
Using the “mapped-file” security model allows the guest emulator to believe that it, as root, can manipulate the 9p mounted filesystem as root for all intents and purposes. On the actual underlying filesystem that qemu is writing to, everything will be created in mode 0600 and belong to the user running qemu, but extra metadata about the files qemu creates are going to go into corresponding files in a .virtfs_metadata directory.
The solution we came up with (I had much help in this area from Rob Taylor), was to write a small translation layer which allows us to also interact with the virtfs staging directory on the host side. What this translation layer does is basically:
- Collect build results and create “real” tarballs from these results. The regular user is not allowed to create device files or files which belong to root, but it is at least allowed to own a tarball containing such files
- The reverse of the previous; stage the content of a real tarball into a virtfs staging ground, so that files are extracted under the users credentials but the correct virtfs metadata is created so that the guest (build slave) will see the right thing
- Stage files and directories into the virtfs staging grounds. This part is required for extracted git repositories which we intend to build.
This way, the whole operating system image can potentially be built from scratch by a regular user on the host.
Summary
At this, unfinished stage, I have built over 300 of the ~420 components which go into the basic GNOME system using this method of compilation to build for armv5l on my x86_64 laptop. The only build instructions which needed to be changed in order to build these were the base compiler and glibc builds, and a couple of minor changes to get some packages to build on armv5l.
Most of the kinks have been ironed out, I still have to build over 100 high level components and deploy and test the resulting image, but the higher up the stack you get the less problems you tend to encounter, I presume we’re through the worst of it.
Performance wise, this will never be as fast as scratchbox, however it’s possible that we explore qemu’s user mode emulation at some point. The problem with performance is the more you optimize here, the more nasty hacks you introduce (if say, you want to run host perl while building in the emulator), and the less comprehensive build system you end up with. We will try to keep a nice balance here and prioritize on repeatability and the convenience this can offer in terms of bootstrapping an OS with baserock build instructions on new architectures.
I can say however that regarding performance, libtool is probably next on the chopping block. It serves basically no purpose when building on linux, and building libtool objects costs about 8 to 10 times the time as simply compiling a regular object over distcc.
I will have to put this work down for a while as I have other work landing on my plate which requires attention, so I hope there will be an army of developers to continue this work in my absence 🙂
If you would like to try and repeat this work, a HOWTO can be found at the bottom of this email. Note that in that email, we had not yet tried the virtfs mapped security model which solves the problem of building as a regular user, however the instructions to get a build off the ground are still valid.
For now I see this as an interesting research project, we have tried some pretty new and interesting things, I am curious to see where this will lead us.
And, special thanks are owed to Rob Landley for giving me pointers along the way while navigating the Aboriginal build system, and for being generally entertaining in #toybox in freenode. Also thanks to Rob Taylor for digging into the qemu sources and coming up with the wild idea of man handling the virtfs mapped metadata.