
Part 1 of this series looks at the state of the climate crisis, and how we can still get our governments to do something about it. Part 2 considers the collapse scenarios we’re likely to face if we fail in those efforts. In this part we’re looking at concrete things we could work towards to make our software more resilient in those scenarios.
The takeaway from part 2 was that if we fail to mitigate the climate crisis, we’re headed for a world where it’s expensive or impossible to get new hardware, where electrical power is scarce, internet access is not the norm, and cloud services don’t exist anymore or are largely inaccessible due to lack of internet.
What could we do to prepare our software for these risks? In this part of the series I’ll look at some ideas and relevant art for resilient technlogy, and how we could apply this to GNOME.
Local-First
Producing power locally is comparatively doable given the right equipment, but internet access is contingent on lots of infrastructure both locally and across the globe. This is why reducing dependence on connectivity is probably the most important challenge for resilience.
Unfortunately we’ve spent the past few decades making software ever more reliant on having fast internet access, all the time. Many of the apps people spend all day in are unusable without an internet connection. So what would be the opposite of that? Is anyone working in the direction of minimizing reliance on the network?
As it turns out, yes! It’s called “local-first”. The idea is that instead of the primary copy of your data being on a server and local apps acting as clients to it, the client is the primary source of truth. The network is only used optionally for syncing and collaboration, with potential conflicts automatically resolved using CRDTs. This allows for superior UX because you’re not waiting on the network, better privacy because you can end-to-end encrypt everything, and better handling of low-connectivity cases. All of this is of course technically very challenging, and there aren’t many implementations of it in production today, but the field is growing and maturing quickly.
Among the most prominent proponents of the local-first idea are the community around the Ink & Switch research lab and Muse, a sketching/knowledge work app for Apple platforms. However, there’s also prior work in this direction from the GNOME community: There’s Christian Hergert’s Bonsai, the Endless content apps, and it’s actually one of the GNOME Foundation’s newly announced goals to enable more people to build local-first apps.
For more on local-first software, I recommend watching Rob’s GUADEC talk (Recording on Youtube), reading the original paper on local-first software (2019), or listening to this episode of the Metamuse podcast (2021) on the subject.
Other relevant art for local-first technology:
- automerge, a library for building local-first software
- Fullscreen, a web-based whiteboard app which allows saving to a custom file format that includes history and editing permissions
- Magic Wormhole, a system to send files directly between computers without any servers
- Earthstar, a local-first sync system with USB support
USB Fallback
Local-first often assumes it’s possible to sometimes use the network for syncing or transferring data between devices, but what if you never have an internet connection?
It’s possible to use the local network in some instances, but they’re not very reliable in practice. Local networks are often weirdly configured, and things can fail in many ways that are hard to debug (Source: Endless tried it and decided it was not worth the hassle). In contrast USB storage is reliable, flexible, and well-understood by most people, making it a much better fallback.
As a practical example, a photo management app built in this paradigm would
- Store all photos locally so there’s never any spinners after first setup
- Allow optionally syncing with other devices and collaborative album management with other people via local network or the internet
- Automatically reconcile conflicts if something changed on other devices while they were disconnected
- Allow falling back to USB, i.e. copying some of the albums to a USB drive and then importing them on another device (including all metadata, collaboration permissons, etc.)
{kind=link}
Some concrete things we could work on in the local-first area:
- Investigate existing local-first libraries, if/how they could be integrated into our stack, or if we’d need to roll our own
- Prototype local-first sync in some real-world apps
- Implement USB app installation and updates in GNOME Software (mockups)
Resource Efficiency
While power can be produced locally, it’s likely that in the future it will be far less abundant than today. For example, you may only have power a few hours a day (already a reality in parts of the global south), or only when there’s enough sun or wind at the moment. This makes power efficiency in software incredibly important.
Power Measurement is Hard
Improving power efficiency is not straightforward, since it’s not possible to measure it directly. Measuring the computer’s power consumption as a whole is trivial, but knowing which program caused how much of it is very difficult to pin down (for more on this check out Aditya Manglik’s GUADEC talk (Recording on Youtube) about power profiling tooling). Making progress in this area is important to allow developers to make their software more power-efficient.
However, while better measurements would be great to have, in practice there’s a lot developers can do even without it. Power is in large part a function of CPU, GPU, and memory use, so reducing each of these definitely helps, and we do have mature profiling tools for these.
Choose a Low-Power Stack
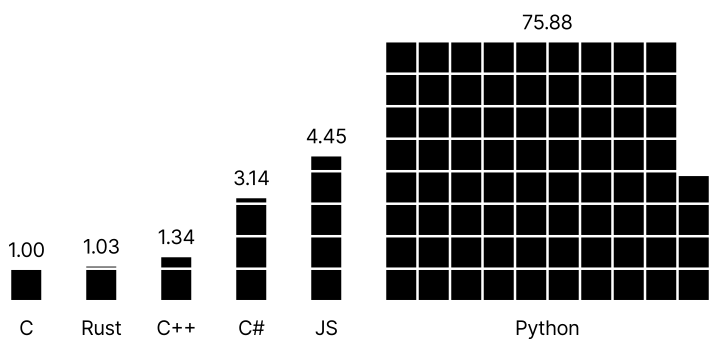
Different tech stacks and dependencies are not created equal when it comes to power consumption, so this is a factor to take into account when starting new projects. One area where there are actual comparative studies on this is programming languages: For example, according to this paper Python uses way more power than other languages commonly used for GNOME app development.
Another important choice is user interface toolkit. Nowadays many applications just ship their own copy of Chrome (in the form of Electron) to render a web app, resulting in huge downloads, slow startup times, large CPU and memory footprints, and laggy interfaces. Using native toolkits instead of web technologies is a key aspect of making resilient software, and GTK4/Adwaita is actually in a really good position here given its performance, wide language support, modern feature set and widgets, and community-driven development model.
Schedule Power Use
It’s also important to actively consider the temporal aspect of power use. For example, if your power supply is a solar panel, the best time to charge batteries or do computing-intensive tasks is during the day, when there’s the most sunlight.
If we had a way for the system to tell apps that right now is a good/bad time to use a lot of power, they could adjust their behavior accordingly. We already do something similar for metered connections, e.g. Software doesn’t auto-download updates if your connection is metered. I could also imagine new user-facing features in this direction, e.g. a way to manually schedule certain tasks for when there will be more power so you can tell Builder to start compiling the long list of dependencies for a newly cloned Rust project tomorrow morning when the sun is back out.
Some concrete things we could work on in the area of resource efficiency:
- Improve power efficiency across the stack
- Explore a system API to tell apps whether now is a good time to use lots of power or not
- Improve the developer story for GTK on Windows and macOS, to allow more people to choose it over Electron
Data Resilience
In hedging against loss of connectivity, it’s not enough to have software that works offline. In many cases what’s more important is the data we read/write using that software, and what we can do with it in resource-constrained scenarios.
The File System is Good, Actually
The 2010s saw lots of experimentation with moving away from the file system as the primary way to think about data storage, both within GNOME and across the wider industry. It makes a lot of sense in theory: Organizing everything manually in folders is shit work people don’t want to do, so they end up with messy folder hierarchies and it’s hard to find things. Bespoke content apps for specific kinds of data, with rich search and layouts custom-tailored to the data are definitely a nicer, more human-friendly way to deal with content–in theory.
In practice we’ve seen a number of problems with the content app approach though, including
- Flexibility: Files can be copied/pasted/deleted, stored on a secondary internal drive, sent as email attachments, shared via a USB key, opened/changed using other apps, and more. With content apps you usually don’t have all of these options.
- Interoperability: The file system is a lowest common denominator across all OSes and apps.
- Development Effort: Building custom viewers/editors for every type of content is a ton of work, in part because you have to reimplement all the common operations you get for free in a file manager.
- Familiarity: While it’s messy and not that easy to learn, most people have a vague understanding of the file system by now, and the universality of this paradigm means it only has to be learned once.
- Unmaintained Apps: Data living in a specific app’s database is useless if the app goes unmaintained. This is especially problematic in free software, where volunteer maintainers abandoning projects is not uncommon.
Due to the above reasons, we’ve seen in practice that the file system is not in fact dying. It’s actually making its way into places where it previously wasn’t present, including iPhones (which now come with a Files app) and the web (via Nextcloud, Google Drive, and company).
From a resilience point of view some of the shortcomings of content apps listed above are particularly important, such as the flexibility to be moved via USB when there’s no internet, and cross-platform interoperability. This is why I think user-accessible files should be the primary source of truth for user data in apps going forward.
Simple, Standardized Formats
With limited connectivity, a potential risk is that you don’t have the ability to download new software to open a file you’re encountering. This is why sticking to well-known standard formats that any computer is likely to have a viewer/editor for is generally preferable (plain text, standard image formats, PDF, and so on).
When starting a new app, ask yourself, is a whole new format needed or could it use/extend something pre-existing? Perhaps there’s a format you could use that already has an ecosystem of apps that support it, especially on other platforms?
For example, if you were to start a new notes app that can do inline media you could go with a custom binary format and a database, but you could also go with Markdown files in a user-accessible folder. In order to get inline media you could use Textbundle, an extension to Markdown implemented by a number of other Markdown apps on other platforms, which basically packs the contained media into an archive together with the Markdown file.
Side note: I really want a nice GTK app that supports Textbundle (more specifically, its compressed variant Textpack), if you want to make one I’d be deligthed to help on the design side :)
Export as Fallback
Ideally data should be stored in standardized formats with wide support, and human-readable in a text editor as a fallback (if applicable). However, this isn’t possible in every case, for example if an app produces a novel kind of content there are no standardized formats for yet (e.g. a collaborative whiteboard app). In these cases it’s important to make sure the non-standard format is well-documented for people implementing alternative clients, and has support for exporting to more common formats, e.g. exporting the current state of a collaborative whiteboard as PDF or SVG.
Some concrete things we could work on towards better data resilience:
- Explore new ways to do content apps with the file system as a backend
- Look at where we’re using custom formats in our apps, and consider switching to standard ones
- Consider how this fits in with local-first syncing
Keep Old Hardware Running
There are many reasons why old hardware stops being usable, including software built for newer, faster devices becoming too slow on older ones, vendors no longer providing updates for a device, some components (especially batteries) degrading with use over time, and of course planned obsolescence. Some of these factors are purely hardware-related, but some also only depend on software, so we can influence them.
Use old Hardware for Development
I already touched on this in the dedicated section above, but obviously using less CPU, RAM, etc. helps not only with power use, but also allows the software to run on older hardware for longer. Unfortunately most developers use top of the line hardware, so they are least impacted by inefficiencies in their personal use.
One simple way to ensure you keep an eye on performance and resource use: Don’t use the latest, most powerful hardware. Maybe keep your old laptop for a few years longer, and get it repaired instead of buying a new one when something breaks. Or if you’re really hardcore, buy an older device on purpose to use as your main machine. As we all know, the best way to get developers to care about something is to actually dogfood it :)
Hardware Enablement for Common Devices
In a world where it’s difficult to get new hardware, it’ll become increasingly important to reuse existing devices we have lying around. Unfortunately, a lot of this hardware is stuck on very old versions of proprietary software that are both slow and insecure.
With Windows devices there’s an easy solution: Just install an up-to-date free software OS. But while desktop hardware is fairly well-supported by mainline Linux, mobile is a huge mess in this regard. The Android world almost exclusively uses old kernels with lots of non-upstreamable custom patches. It takes years to mainline a device, and it has to be done for every device.
Projects like PostmarketOS are working towards making more Android devices usable, but as you can see from their device support Wiki, success is limited so far. One especially problematic aspect from a resilience point of view is that the devices that tend to be worked on are the ones that developers happen to have, which are generally not the models that sell the most units. Ideally we’d work strategically to mainline some of the most common devices, and make sure they actually fully work. Most likely that’d be mid-range Samsung phones and iPhones. For the latter there’s curiously little work in this direction, despite being a gigantic, relatively homogeneous pool of devices (for example, there are 224 million iPhone 6 out there which don’t get updates anymore).
Hack Bootloaders
Unfortunately, hardware enablement alone is not enough to make old mobile devices more long-lived by installing more up-to date free software. Most mobile devices come with locked bootloaders, which require contacting the manufacturer to get an unlock code to install alternative software – if they allow it at all. This means if the vendor company’s server goes away or you don’t have internet access there’s no way to repurpose a device.
What we’d probably need is a collection of exploits that allow unlocking bootloaders on common devices in a fully offline way, and a user-friendly automated unlocking tool using these exploits. I could imagine this being part of the system’s disk utility app or a separate third-party app, which allows unlocking the bootloader and installing a new OS onto a mobile device you plug in via USB.
Some concrete things we could work on to keep old hardware running:
- Actively try to ensure older hardware keeps working with new versions of our software (and ideally getting faster with time rather than slower thanks to ongoing performance work)
- Explore initiatives to do strategic hardware eneblament for some of the most common mobile devices (including iPhones, potentially?)
- Forge alliances with the infosec/Android modding community and build convenient offline bootloader unlocking tools
Build for Repair
In a less connected future it’s possible that substantial development of complex systems software will stop being a thing, because the necessary expertise will not be available in any single place. In such a scenario being able to locally repair and repurpose hardware and software for new uses and local needs is likely to become important.
Repair is a relatively clearly defined problem space for hardware, but for software it’s kind of a foreign concept. The idea of a centralized development team “releasing” software out into the world at scale is built into our tools, technologies, and culture at every level. You generally don’t repair software, because in most cases you don’t even have the source code, and even if you do (and the software doesn’t depend on some server component) there’s always going to be a steep learning curve to being able to make meaningful changes to an unfamiliar code base, even for seasoned programmers.
In a connected world it will therefore always be most efficient to have a centralized development team that maintains a project and makes releases for the general public to use. But with that possibly no longer an option in the future, someone else will end up having to make sure things work as best they can at the local level. I don’t think this will mean most people will start making changes to their own software, but I could see software repair becoming a role for specialized technicians, similar to electricians or car mechanics.
How could we build our software in a way that makes it most useful to people in such a future?
Use Well-Understood, Accessible Tech
One of the most important things we can do today to make life easier for potential future software repair technicians is using well-established technology, which they’re likely to already have experience with. Writing apps in Haskell may be a fun exercise, but if you want other people to be able to repair/repurpose them in the future, GJS is probably a better option, simply because so many more people are familiar with the language.
Another important factor determining a technology stack’s repairability is how accessible it is to get started with. How easy is it for someone to get a development environment up and running from scratch? Is there good (offline) documentation? Do you need to understand complex math or memory management concepts?
Local-First Development
Most modern development workflows assume a fast internet connection on a number of levels, including downloading and updating dependencies (e.g. npm modules or flatpak SDKs), documentation, tutorials, Stackoverflow, and so on.
In order to allow repair at the local level, we also need to rethink development workflows in a local-first fashion, meaning things like:
- Ship all the source code and development tools needed to rebuild/modify the OS and apps with the system
- Have a first-class flow for replacing parts of the system or apps with locally modified/repaired versions, allowing easy management of different versions, rollbacks, etc.
- Have great offline documentation and tutorials, and maybe even something like a locally cached subset of Stackoverflow for a few technologies (e.g. the 1000 most popular questions with the “gtk” tag)
Getting the tooling and UX right for a fully integrated local-first software repair flow will be a lot of work, but there’s some interesting relevant art from Endless OS from a few years back. The basic idea was that you transform any app you’re running into an IDE editing the app’s source code (thanks to Will Thompson for the screencast below). The devil is of course in the details for making this a viable solution to local software repair, but I think this would be a very interesting direction to explore further.
Some concrete things we could work on to make our software more repairable:
- Avoid using obscure languages and technologies for new projects
- Avoid overly complex and brittle dependency trees
- Investigate UX for a local-first software repair flow
- Revive or replace the Devhelp offline documentation app
- Look into ways to make useful online resources (tutorials, technical blog posts, Stackoverflow threads, etc.) usable offline
This was part three of a four-part series. In the fourth and final installment we’ll wrap up the series by looking at some of the hurdles in moving towards resilience and how we could overcome them.