
Part 1 of this series looks at the state of the climate emergency we’re in, and how we can still get our governments to do something about it. Part 2 looks at collapse scenarios we’re likely to face if we fail in those efforts, and part 3 is about concrete things we could work towards to make our software more resilient in those scenarios. In this final part we’re looking at obstacles and contradictions on the path to resilience.
Part 3 of this series was, in large parts, a pretty random list of ideas for how to make software resilient against various effects of collapse. Some of those ideas are potentially contradictory, so in this part I want to explore these contradictions, and hopefully start a discussion towards a realistic path forward in these areas.
Efficient vs. Repairable
The goals of wanting software to be frugal with resources but also easy to repair are often hard to square. Efficiency is generally achieved by using lower-level technology and having developers do more work to optimize resource use. However, for repairability you want something high-level with short feedback loops and introspection, i.e. the opposite.
An app written and distributed as a single Python file with no external dependencies is probably as good as it gets in terms of repairability, but there are serious limitations to what you can do with such an app and the stack is not known for being resource-efficient. The same applies to other types of accessible programming environments, such as scripts or spreadsheets. When it comes to data, plain text is very flexible and easy to work with (i.e. good for repairability), but it’s less efficient than binary data formats, can’t be queried as easily as a database, etc.
My feeling is that in many cases it’s a matter of choosing the right tradeoffs for a given situation, and knowing which side of the spectrum is more important. However, there are definitely examples where this is not a tradeoff: Electron is both inefficient and not very repairable due to its complexity.
What I’m more interested in is how we could bring both sides of the spectrum closer together: Can we make the repair experience for a Rust app feel more like a single-file Python script? Can we store data as plain text files, but still have the flexibility to arbitrarily query them like a database?
As with all degrowth discussions, there’s also the question whether reducing the scope of what we’re trying to achieve could make it much easier to square both goals. Similar to how we can’t keep using energy at the current rate and just swap fossil fuels out for renewables, we might have to cut some features in the interest of making things both performant and repairable. This is of course easier said than done, especially for well-established software where you can’t easily remove things, but I think it’s important to keep this perspective in mind.
File System vs. Collaboration
If you want to store data in files while also doing local-first sync and collaboration, you have a choice to make: You can either have a global sync system (per-app or system wide), or a per-file one.
Global sync: Files can use standard formats because history, permissions for collaboration, etc. are managed globally for all files. This has the advantage that files can be opened with any editor, but the downside is that copying them elsewhere means losing this metadata, so you can no longer collaborate on the file. This is basically what file sync services à la Nextcloud do (though I’m not sure to what degree these support real-time collaboration).
Per-file sync: The alternative is having a custom file format that includes all the metadata for history, sync, and collaboration in addition to the content of the file. The advantage of this model is that it’s more flexible for moving files around, backing them up, etc. because they are self-contained. The downside is that you lose access to the existing ecosystem of editors for the file type. In some cases that may be fine because it’s a novel type of content anyway, but it’s still not great because you want to ensure there are lots of apps that can read your content, across all platforms. The Fullscreen whiteboard app is an example of this model.
Of course ideally what you’d want is a combination of both: Metadata embedded in each file, but done in such a way that at least the latest version of the content can still be opened with any generic editor. No idea how feasible that’d be in general, but for text-based formats I could imagine this being a possibility, perhaps using some kind of front-matter with a bunch of binary data?
More generally, there’s a real question where this kind of real-time collaboration is needed in the first place. For which use cases is the the ability to collaborate in real time worth the added complexity (and hence reduced repairability)? Perhaps in many cases simple file sync is enough? Maybe the cases where collaboration is needed are rare enough that it doesn’t make sense to invest in the tech to begin with?
Bandwidth vs. Storage
In thinking about building software for a world with limited connectivity, it’s generally good to cache as much as possible on disk and hit the network as little as possible. But of course that also means using more disk space, which can itself become a resource problem, especially in the case of older computers or mobile devices. This would be accelerated if you had local-first versions of all kinds of data-heavy apps that currently only work with a network connection (e.g. having your entire photo and music libraries stored locally on disk).
One potential approach could be to also design for situations with limited storage. For example, could we prioritize different kinds of offline content in case something has to be deleted/offloaded? Could we offload large, but rarely used content or apps to external drives?
For example, I could imagine moving extra Flatpak SDKs you only need for development to a separate drive, which you only plug in when coding. Gaming could be another example: Your games would be grayed-out in the app grid unless you plug in the hard drive they’re on.
Having properly designed and supported workflows and failure states for low-storage cases like these could go a long way here.
Why GNOME?
Perhaps you’re wondering why I’m writing about this topic in the context of free software, and GNOME in particular. Beyond the personal need to contextualize my own work in the reality of the climate crisis, I think there are two important reasons: First, free software may have an important role to play in keeping computers useful in coming crisis scenarios, so we should make sure it’s good at filling that role. GNOME’s position in the GNU/Linux space and our close relationships and personnel overlap with projects up and down the stack make it a good forum to discuss these questions and experiment with solutions.
But secondly, and perhaps more importantly, I think this community has the right kinds of people for the problems at hand. There aren’t very many places where low-level engineering and principled UX design are done together at this scale, in the commons.
Some resilience-focused projects are built on the very un-resilient web stack because that’s what the authors know. Others have a tiny community of volunteer developers, making it difficult to build something that has impact beyond isolated experiments. Conversely, GNOME has a large community of people with expertise all across the stack, making it an interesting place to potentially put some of these ideas into practice.
People to Learn From?
While it’s still quite rare in tech circles overall, there are some other people thinking about computing from a climate collapse point of view, and/or working on adjacent problems. While most of this work is not directly relevant to GNOME in terms of technology, I find some of the ideas and perspectives very valuable, and maybe you do as well. I definitely recommend following some of these people and projects on Mastodon :)
Permacomputing is a philosophy trying to apply permaculture-like principles to computing. The term was coined by Ville-Matias “Viznut” Heikkilä in a 2020 essay. Permaculture aims to establish natural systems that can work sustainably in the long term, and the goal with permacomputing is to do something similar for computing, by rethinking its relationship to resource and energy use, and the kinds of things we use it for. As further reading, I recommend this interview with Heikkilä and Marloes de Valk.
100 Rabbits is a two-person art collective living on a sailboat and experimenting with ideas around resilience, wherein their boat studio setup is a kind of test case for the kinds of resource constraints collapse might bring. One of their projects is uxn, a tiny, portable emulator, which serves as a super-constrained platform to build apps and games for in a custom Assembly language. I think their projects are especially interesting because they show that you don’t need fancy hardware to build fun, attractive things – what’s far more important is the creativity of the people doing it.

Collapse OS is an operating system written in Forth by Virgil Dupras for a further-away future, where industrial society has not only collapsed, but when people stop having access to any working modern computers. For that kind of scenario it aims to provide a simple OS that can run on micro-controllers that are easy to find in all kinds of electronics, in order to build or repair custom electronics and simple computers.
Low Tech is an approach to technology that tries to keep things simple and resilient, often by re-discovering older technologies and recombining them in new ways. An interesting example of this philosophy in both form and content is Low Tech Magazine (founded in 2007 by Kris De Decker). Their website uses a dithered aesthetic for images that allows them to be just a few Kilobytes each, and their server is solar-powered, so it can go down when there’s not enough sunlight.

Ink & Switch is a research lab exploring ambitious high-level ideas in computing, some of which are very relevant to resilience and autonomy, such as local-first software, p2p collaboration, and new approaches to digital identity.
p2panda is a protocol for building local-first apps. It aims to make it easy enough to build p2p applications that developers can spend their time thinking about interesting user experiences rather than focus on the basics of making p2p work. It comes with reference implementations in Rust and Typescript.
Earthstar is a local-first sync system developed by Sam Gwilym with the specific goal to be “like a bicycle“, i.e. simple, reliable, and easy enough to understand top-to-bottom to be repairable.
Funding Sources
Unfortunately, as with all the most important work, it’s hard to get funding for projects in this area. It’ll take tons of work by very skilled people to make serious progress on things like power profiling, local-first sync, or mainlining Android phones. And of course, the direction is one where we’re not only not enabling new opportunities for commerce, but rather eliminating them. The goal is to replace subscription cloud services with (free) local-first ones, and make software so efficient that there’s no need to buy new hardware. Not an easy sell to investors :)
However, while it’s difficult to find funding for this work it’s not impossible either. There are a number of public grant programs that fund projects like these regularly, and where resilience projects around GNOME would fit in well.
If you’re based in the the European Union, there are a number of EU funds under the umbrella of the Next Generation Internet initiative. Many of them are managed by dutch nonprofit NLNet, and have funded a number of different projects with a focus on peer-to-peer technology, and other relevant topics. NLNet has also funded other GNOME-adjacent projects in the past, most recently Julian’s work on the Fractal Matrix client.
If you’re based in Germany, the German Ministry of Education’s Prototype Fund is another great option. They provide 6 month grants to individuals or small teams working on free software in a variety of areas including privacy, social impact, peer-to-peer, and others. They’ve also funded GNOME projects before, most recently the GNOME Shell mobile port.
The Sovereign Tech Fund is a new grant program by the German Ministry of Economic Affairs, which will fund work on software infrasctucture starting in 2023. The focus on lower-level infrastructure means that user-facing projects would probably not be a good fit, but I could imagine, for example, low-level work for local-first technology being relevant.
These are some grant programs I’m personally familiar with, but there are definitely others (don’t hesitate to reach out if you know some, I’d be happy to add them here). If you need help with grant applications for projects making GNOME more resilient don’t hesitate to reach out, I’d be happy to help :)
What’s Next?
One of my hopes with this series was to open a space for a community-wide discussion on topics like degrowth and resilience, as applied to our development practice. While this has happened to some degree, especially at in-person gatherings, it hasn’t been reflected in our online discourse and actual day-to-day work as much as I’d hoped. Finding better ways to do that is definitely something I want to explore in 2023.
On the more practical side, we’ve had sporadic discussions about various resilience-related initiatives, but nothing too concrete yet. As a next step I’ve opened a Gitlab issue for discussion around practical ideas and initiatives. To accelerate and focus this work I’d like to do a hackfest with this specific focus sometime soon, so stay tuned! If you’d be interested in attending, let me know :)
Closing Thoughts
It feels surreal to be writing this. There’s something profoundly weird about discussing climate collapse… on my GNOME development blog. Believe me, I’d much rather be writing about fancy animations and porting apps to phones. But such are the times. The climate crisis affects, or will affect, every aspect of our lives. It’d be more surreal not to think about how it will affect my work, to ignore or compartmentalize it as a separate thing.
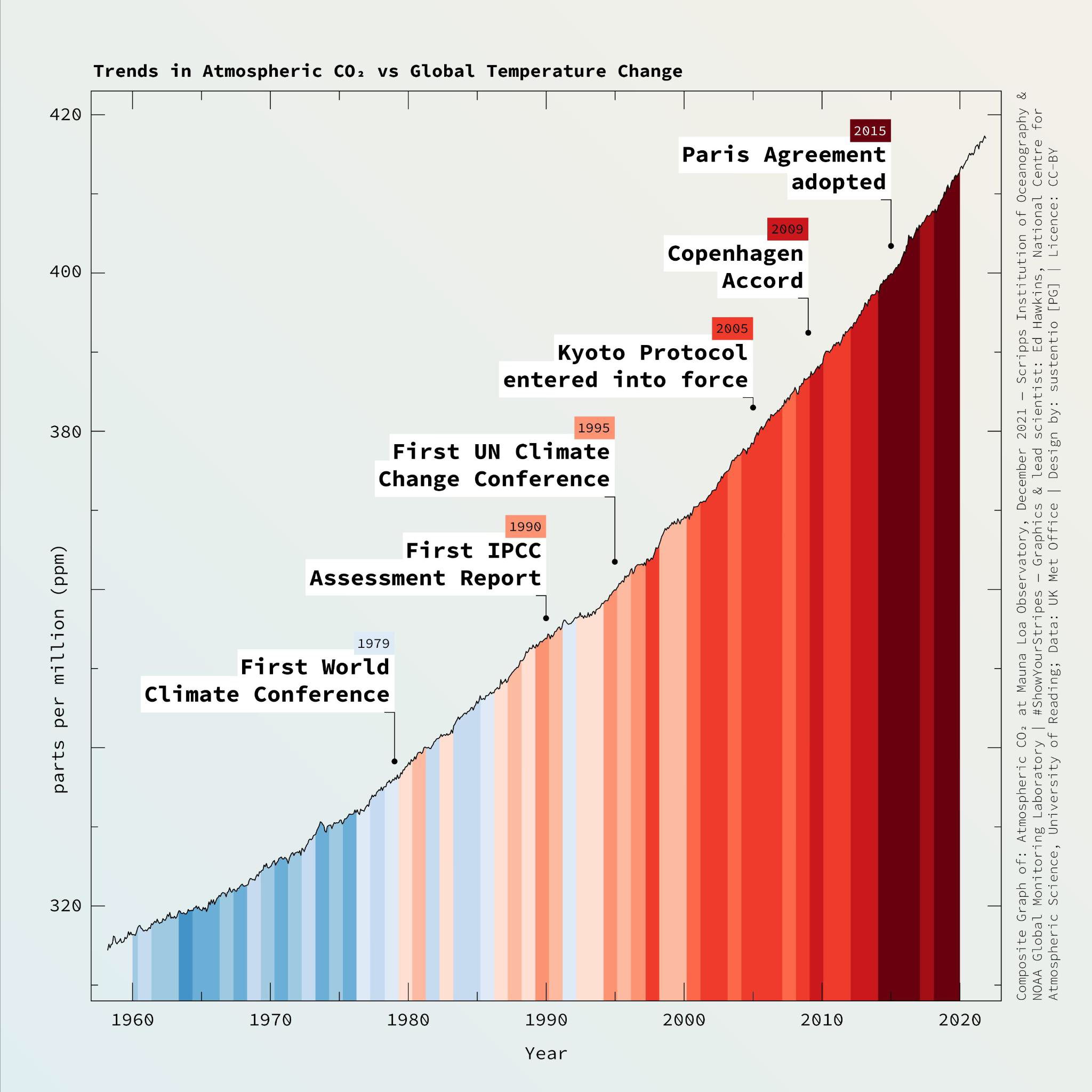
As I write this in late 2022, we’ve just had one of the the hottest years on record, with an unprecedented number of catastrophes across the globe. At the same time, we’ve also seen the complete inability of the current political and economic system to enact meaningful policies to actually reduce emissions. This is especially dire in the context of the new IPCC report released earlier in the year, which says that global emissions need to peak before 2025 at the latest. But instead of getting starting on the massive transition this will require, governments are building new fossil infrastructure with public money, further fueling the crisis.

But no matter how bad things get, there’s always hope in action. Whether you glue yourself to the road to force the government to enact emergency measures, directly stop emissions by blocking the expansion of coal mines, seize the discourse with symbolic actions in public places, or disincentivize luxury emissions by deflating SUV tires, there’s a wing of this movement for everyone. It’s not too late to avoid the worst outcomes – If you, too, come and join the fight.
See you in action o/






{kind=link}