
Last week was this year’s GUADEC, the first ever in Italy! Here are a few impressions.
Local-First
One of my main focus areas this year was local-first, since that’s what we’re working on right now with the Reflection project (see the previous blog post). Together with Julian and Andreas we did two lightning talks (one on local-first generally, and one on Reflection in particular), and two BoF sessions.

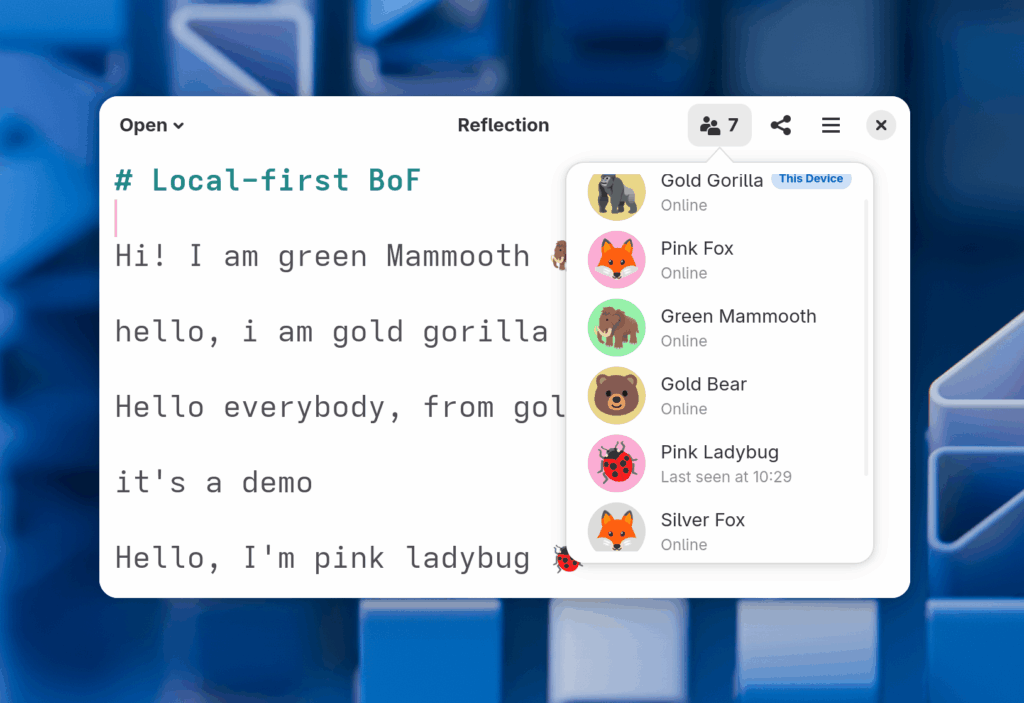
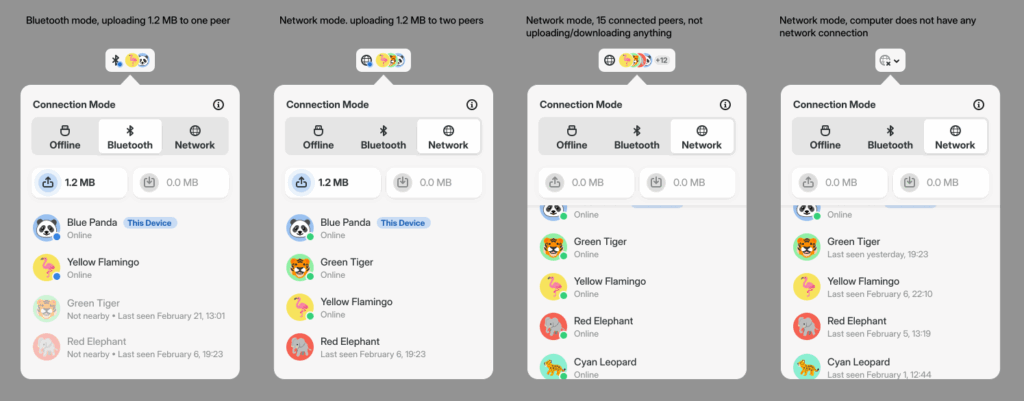
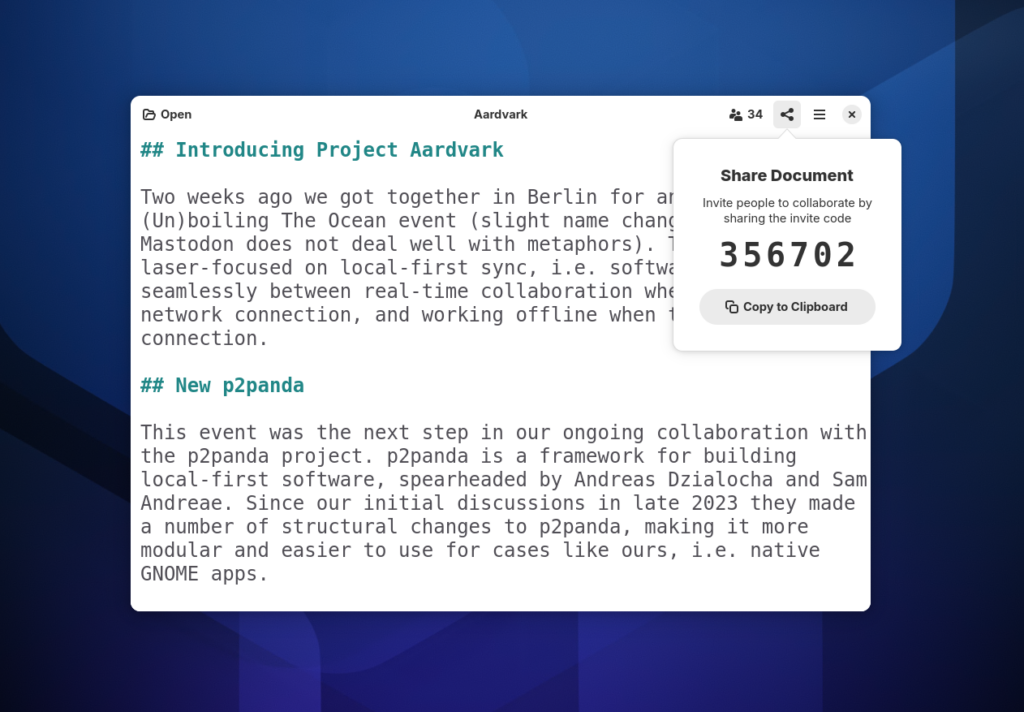
At the BoFs we did a bit of Reflection testing, and reached a new record of people simultaneously trying the app:
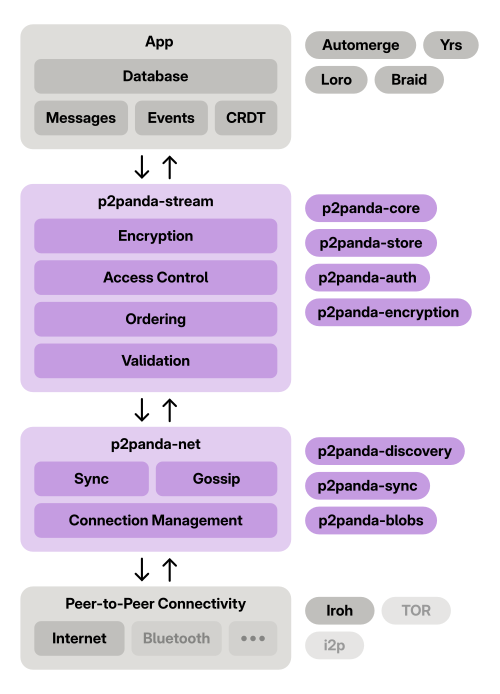
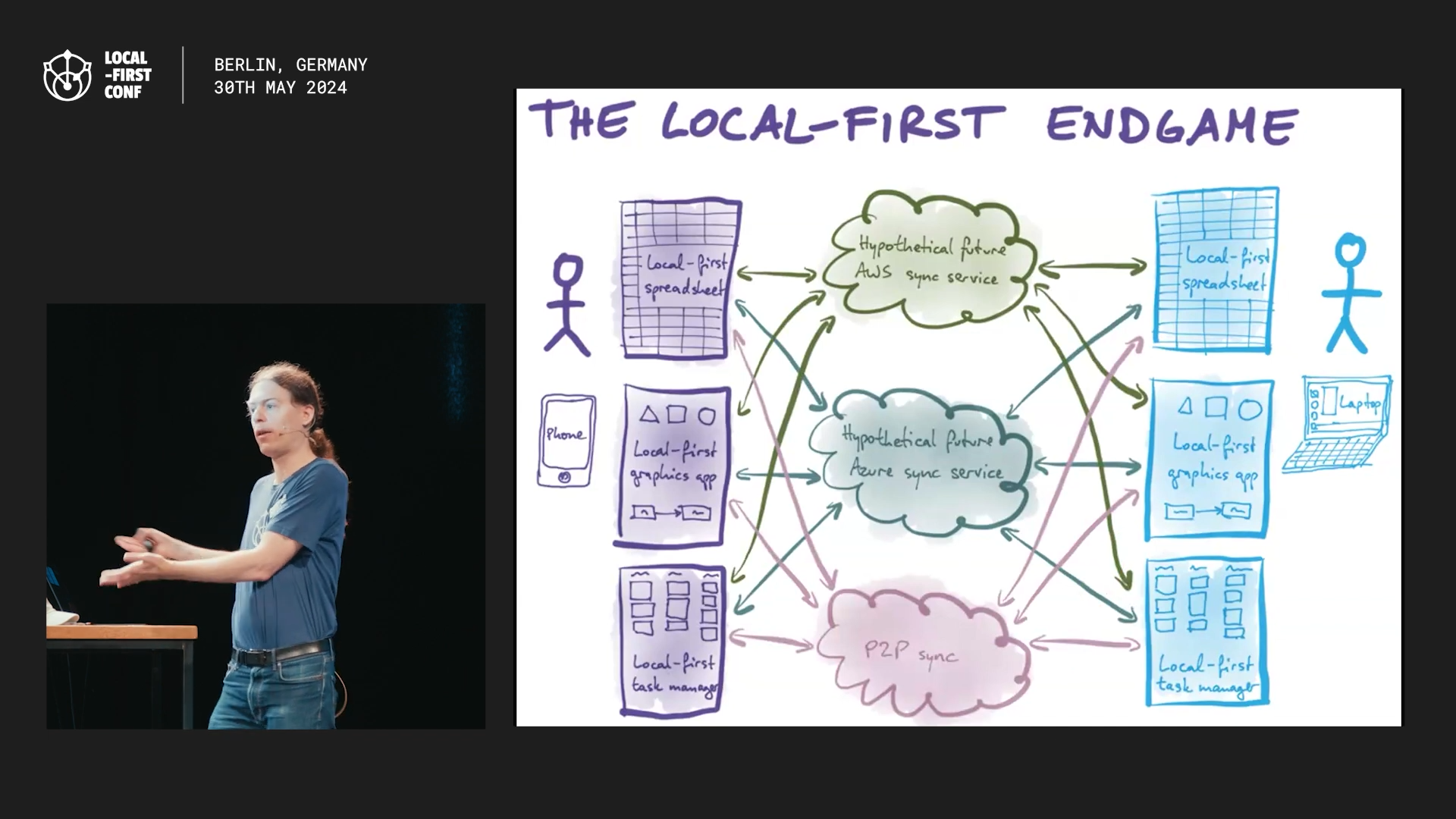
Andreas also explained the p2anda stack in detail using a new diagram we made a few weeks back, which visualizes how the various components fit together in a real app.
We also discussed some longer-term plans, particularly around having a system-level sync service. The motivation for this is twofold: We want to make it as easy as possible for app developers to add sync to their app. It’s never going to be “free”, but if we can at least abstract some of this in a useful way that’s a big win for developer experience. More importantly though, from a security/privacy point of view we really don’t want every app to have unrestricted access to network, Bluetooth, etc. which would be required if every app does its own p2p sync.
One option being discussed is taking the networking part of p2panda (including iroh for p2p networking) and making it a portal API which apps can use to talk to other instances of themselves on other devices.
Another idea was a more high-level portal that works more like a file “share” system that can sync arbitary files by just attaching the sync context to files as xattrs and having a centralized service handle all the syncing. This would have the advantage of not requiring special UI in apps, just a portal and some integration in Files. Real-time collaboration would of course not be possible without actual app integration, but for many use cases that’s not needed anyway, so perhaps we could have both a high- and low-level API to cover different scenarios?
There are still a lot of open questions here, but it’s cool to see how things get a little bit more concrete every time :)
If you’re interested in the details, check out the full notes from both BoF sessions.
Design
Jakub and I gave the traditional design team talk – a bit underprepared and last-minute (thanks Jakub for doing most of the heavy lifting), but it was cool to see in retrospect how much we got done in the past year despite how much energy unfortunately went into unrelated things. The all-new slate of websites is especially cool after so many years of gnome.org et al looking very stale. You can find the slides here.

Inspired by the Summer of GNOME OS challenge many of us are doing, we worked on concepts for a new app to make testing sysexts of merge requests (and nightly Flatpaks) easier. The working title is “Test Ride” (a more sustainable version of Apple’s “Test Flight” :P) and we had fun drawing bicycles for the icon.
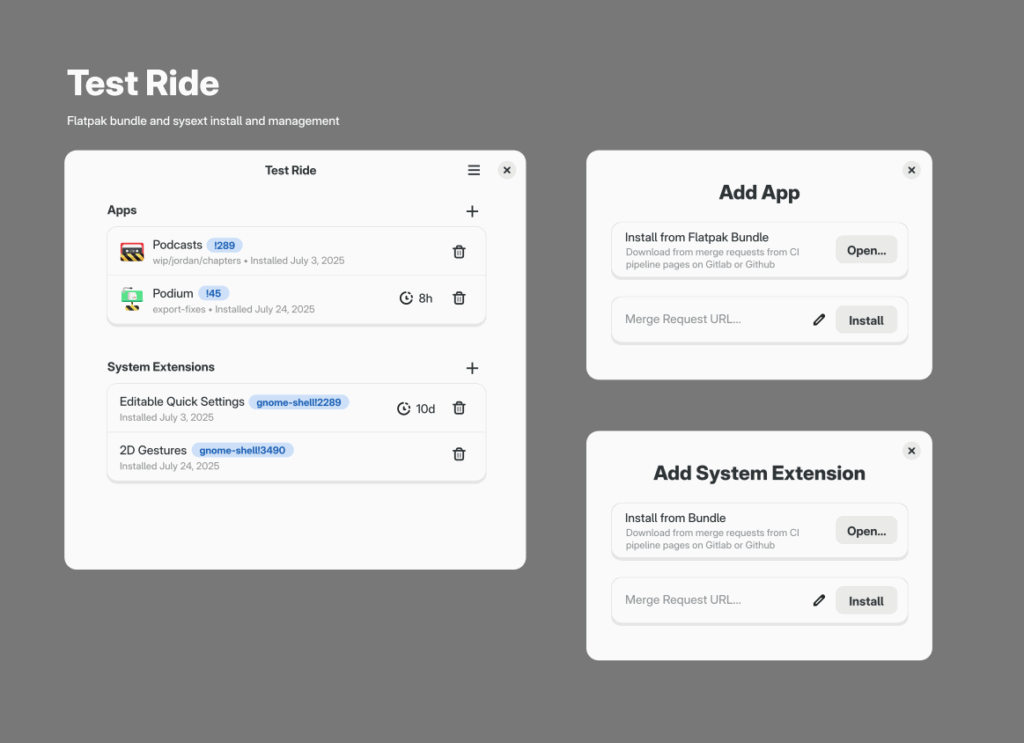
Jakub and I also worked on new designs for Georges’ presentation app Spiel (which is being rebranded to “Podium” to avoid the name clash with the a11y project). The idea is to make the app more resilient and data more future-proof, by going with a file-based approach and simple syntax on top of Markdown for (limited) layout customization.

Miscellaneous
- There was a lot of energy and excitement around GNOME OS. It feels like we’ve turned a corner, finally leaving the “science experiment” stage and moving towards “daily-drivable beta”.
- I was very happy that the community appreciation award went to Alice Mikhaylenko this year. The impact her libadwaita work has had on the growth of the app ecosystem over the past 5 years can not be overstated. Not only did she build dozens of useful and beautiful new adaptive widgets, she also has a great sense for designing APIs in a way that will get people to adopt them, which is no small thing. Kudos, very well deserved!
- While some of the Foundation conflicts of the past year remain unresolved, I was happy to see that Steven’s and the board’s plans are going in the right direction.
Brescia
The conference was really well-organized (thanks to Pietro and the local team!), and the venue and city of Brescia had a number of advantages that were not always present at previous GUADECs:
- The city center is small and walkable, and everyone was staying relatively close by
- The university is 20 min by metro from the city center, so it didn’t feel like a huge ordeal to go back and forth
- Multiple vegan lunch options within a few minutes walk from the university
- Lots of tables (with electrical outlets!) for hacking at the venue
- Lots of nice places for dinner/drinks outdoors in the city center
- Many dope ice cream places

A few (minor) points that could be improved next time:
- The timetable started veeery early every day, which contributed to a general lack of sleep. Realistically people are not going to sleep before 02:00, so starting the program at 09:00 is just too early. My experience from multi-day events in Berlin is that 12:00 is a good time to start if you want everyone to be awake :)
- The BoFs could have been spread out a bit more over the two days, there were slots with three parallel ones and times with nothing on the program.
- The venue closing at 19:00 is not ideal when people are in the zone hacking. Doesn’t have to be all night, but the option to hack until after dinner (e.g. 22:00) would be nice.
- Since that the conference is a week long accommodation can get a bit expensive, which is not ideal since most people are paying for their own travel and accommodation nowadays. It’d have been great if there was a more affordable option for accommodation, e.g. at student dorms, like at previous GUADECs.
- A frequent topic was how it’s not ideal to have everyone be traveling and mostly unavailable for reviews a week before feature freeze. It’s also not ideal because any plans you make at GUADEC are not going to make it into the September release, but will have to wait for March. What if the conference was closer to the beginning of the cycle, e.g. in May or June?
A few more random photos:

























{kind=link}
{kind=link}
{kind=link}
{kind=link}