
This week we had a local-first workshop at offline in Berlin, co-organized with the p2panda project. As I’ve written about before, some of us have been exploring local-first approaches as a way to sync data between devices, while also working great offline.
We had a hackfest on the topic in September, where we mapped out the problem space and discussed different potential architectures and approaches. We also realized that while there are mature solutions for the actual data syncing part with CRDT libraries like Automerge, the network and discovery part is more difficult than we thought.
Network Woes
The issues we need to address at the network level are the classic problems any distributed system has, including:
- Discovering other peers
- Connecting to the other peers behind a NAT
- Encryption and authentication
- Replication (which clients need what data?)
We had sketched out a theoretical architecture for first experiments at the last hackfest, using WebRTC data channel to send data, and hardcoding a public STUN server for rendezvous.
A few weeks after that I met Andreas from p2panda at an event in Berlin. He mentioned that in p2panda they have robust networking already, including mDNS discovery on the local network, remote peer discovery using rendezvous servers, p2p connections via UDP holepunching or relays, data replication, etc. Since we’re very interested in getting a low-fi prototype working sooner rather than later it seemed like a promising direction to explore.
p2panda
The p2panda project aims to provide a batteries-included SDK for easy local-first app development, including all the hard networking stuff mentioned above. It’s been around since about 2020, and is currently primarily developed by Andreas Dzialocha and Sam Andreae.
The architecture consist of nodes and clients. Nodes include networking, materialization, and an SQL database. Clients sign and create data, and interact with the node using a GraphQL API.
As of the latest release there’s TLS transport encryption between nodes, but end-to-end data-encryption using MLS is still being worked on, as well as a capabilities system and privacy-respecting deletion. Currently there’s a single key/value CRDT being used for all data, with no high-level way for apps to customize this.
The Workshop
The idea for the workshop was to bring together people from the GNOME and local-first communities, discuss the problem space, and do some initial prototyping.
For the latter Andreas prepared a little bookmark manager demo project (git repository) that people can open in Workbench and hack on easily. This demo runs a node in the background and accesses the database via GraphQL from a simple GTK frontend, written in Rust. The demo app automatically finds other peers on the local network and syncs the data between them.
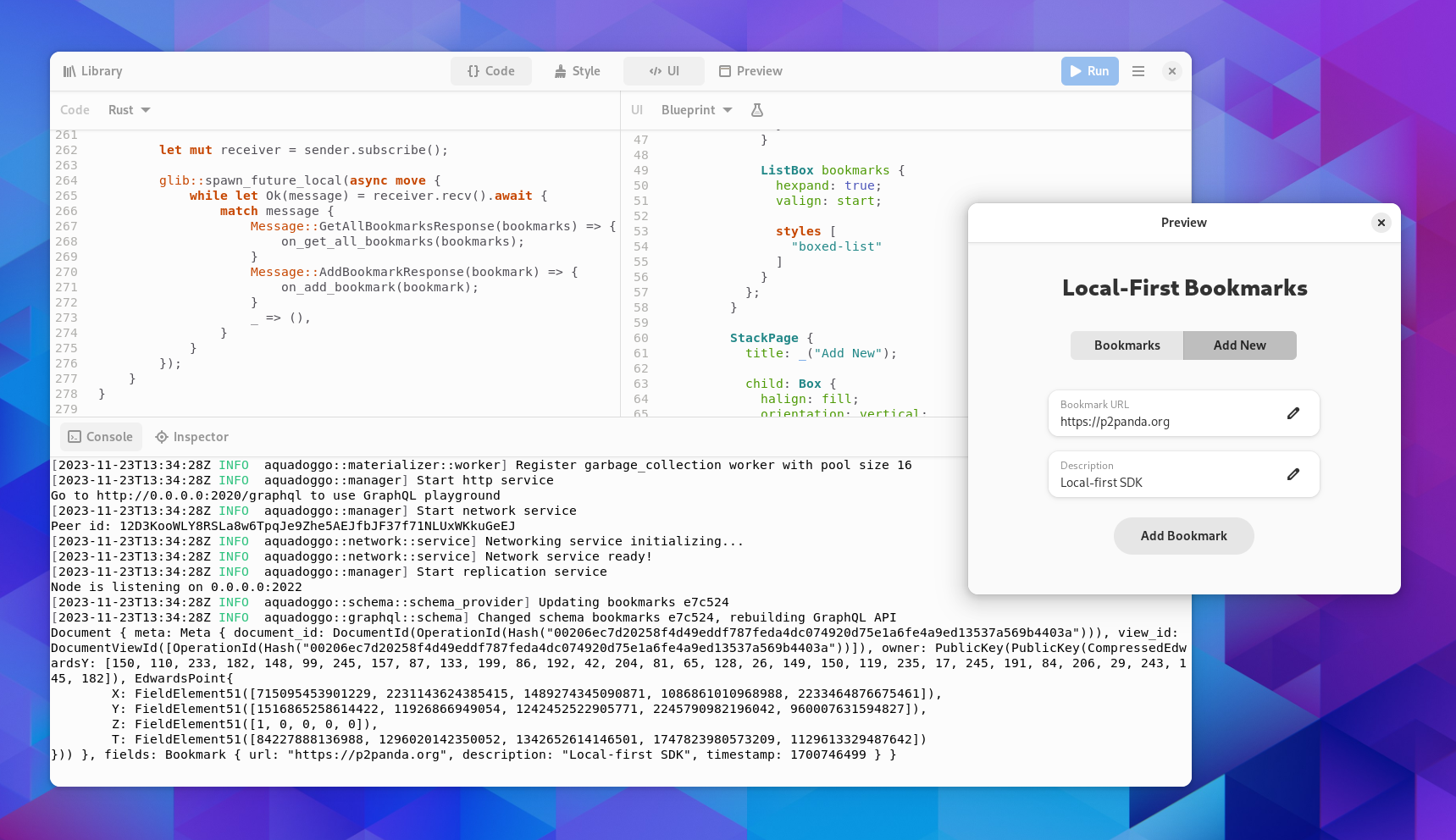
We had about 10 workshop participants with diverse backgrounds, including an SSB developer, a Mutter developer, and some people completely new to both local-first and GTK development. We didn’t get a ton of hacking done due to time constraints (we had enough program for an all-day workshop realistcally :D), but a few people did start projects they plan to pursue after the workshop, including C/GObject bindings for p2panda-rs and an app/demo to sync a list of map locations. We also had some really good discussions on local-first architecture, and the GNOME perspective on this.
Thoughts on Local-First Architectures
The way p2panda splits responsibilities between components is optimized for simple client development, and being able to use it in the browser using the GraphQL API. All of the heavy lifting is done in the node, including networking, data storage, and CRDTs. It currently only supports one CRDT, which is optimized for database-style apps with lots of discrete fields.
One of the main takeaways from our previous hackfest was that data storage and CRDTs should ideally be in the client. Different apps need different CRDTs, because these encode the semantics of the data. For example, a text editor would need a custom text CRDT rather than the current p2panda one.
Longer-term we’ll probably want an architecture where clients have more control over their data to allow for more complex apps and diverse use cases. p2panda can provide these building blocks (generic reducer logic, storage providers, networking stack, etc.) but these APIs still need to be exposed for more flexibility. How exactly this could be done and if/how parts of the stack could be shared needs more exploration :)
Theoretical future architectures aside, p2panda is a great option for local-first prototypes that work today. We’re very excited to start playing with some real apps using it, and actually shipping them in a way that people can try.
What’s Next?
There’s a clear path towards first prototype GNOME apps using p2panda for sync. However, there are two constraints to keep in mind when considering ideas for this:
- Data is not encrypted end-to-end for now (so personal data is tricky)
- The default p2panda CRDT is optimized for key / value maps (more complex ones would need to be added manually)
This means that unfortunately you can’t just plug this into a GtkSourceView and have a Hedgedoc replacement. That said, there’s still lots of cool stuff you can do within these constraints, especially if you get creative in the client around how you use/access data. If you’re familiar with Rust, the Workbench demo Andreas made is a great starting point for app experiments.
Some examples of use cases that could be well-suited, because the data is structured, but not very sensitive:
- Expense splitting (e.g. Splittypie)
- Meeting scheduling (e.g. Doodle)
- Shopping list
- Apartment cleaning schedule
Thanks to Andreas Dzialocha for co-organizing the event and providing the venue, Sebastian Wick for co-writing this blog post, Sonny Piers for his help with Workbench, and everyone who joined the event. See you next time!