
<tl;dr>: Wikimedia migrated its bug tracking from Bugzilla to Phabricator in late November 2014.
After ten years of using Bugzilla with 73681 tickets and ~20000 user accounts and after months of planning, writing migration code, testing, gathering feedback, discussing, writing more code, writing documentation, communicating, et cetera, Wikimedia switched from Bugzilla to Phabricator as its issue tracking tool.
Phabricator is a fun adventure game collaboration platform and a forge that consists of several well-integrated applications. Maniphest is the name of the application for handling bug reports and tasks.
My announcement from May 2014 explained the idea (better collaboration and having less tools) and the decision making process that led to choosing Phabricator and starting to work on making it happen.
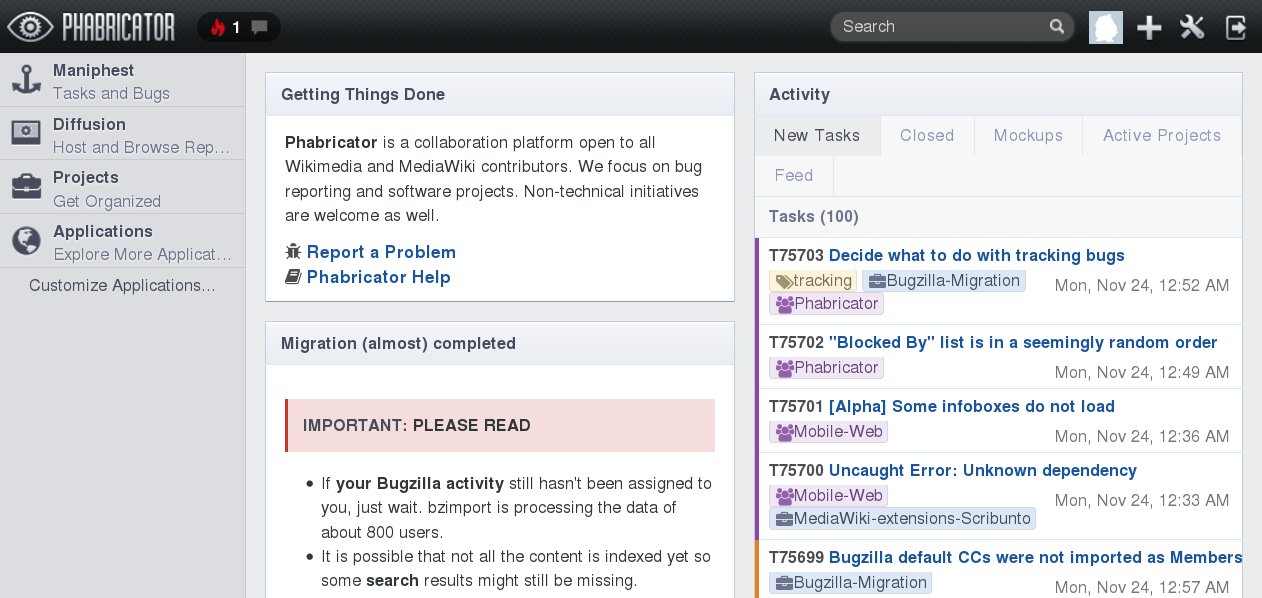
Wikimedia Phabricator frontpage an hour after opening it for the public again after the migration from Bugzilla.
Quim already published an excellent summary of Wikimedia Phabricator right after the migration from Bugzilla, covering its main features and custom functionality that we implemented for our needs. Read that if you want to get an overview of how Phabricator helps Wikimedia with collaborating and planning in software development.
This blog post instead covers more details of the actual steps taken in the last months and the migration from Bugzilla itself. If you want even more verbose steps and information on the progress, check the status updates that I published every other week with links to the specific tickets and/or commits.
Preparation
After reviewing our project management tools and closing the RfC the team started to implement a Wikimedia SUL authentication provider (via OAuth) so no separate account is needed, work on an implementation to restrict access to certain tasks (access restrictions are on a task level and not on a project level), and creating an initial Phabricator module in Puppet.
We started to discuss how to convert information in Bugzilla (keywords, products and components, target milestones, versions, custom fields, …), which information to entirely drop (e.g. the severity field, the history of field value changes, votes, …), and which information to only drop as text in the initial description instead of a dedicated field. More information about data migrated is available in a table. This constantly influenced the scope of the script for the actual data migration from Bugzilla (more information on code).
We already had a (now defunct) Phabricator test instance in Wikimedia Labs under fab.wmflabs.org which we now started to also use for planning the actual migration.
There’s a 7 minute video summary from June describing the general problem with our tools that we were trying to solve and the plan at that time. We also started to write help documentation.
As we got closer to launching the final production instance on phabricator.wikimedia.org, we decided to split our planning into three separate projects to have a better overview: Day 1 of a Phabricator Production instance in use, Bugzilla migration, and RT migration.
On September 15th, phabricator.wikimedia.org launched with relevant content imported from the fab.wmflabs.org test instance which we had used for dogfooding. In the case of Wikimedia, this required setting up SNI and making it work with nginx and the certificate to allow using SUL and LDAP for login. After the production instance had launched we also had another Hangout video session to teach the very basics of Phabricator.
To provide a short impression of further stuff happening in the background: Elasticsearch was set up as Phabricator’s search backend, some legal aspects (footer, determining the license of submitted content) were brought up, phab-01.wmflabs.org was set up as a new playground, and we made several further customizations when it comes to user-visible strings and information on user pages within Phabricator. In the larger environment of Wikimedia infrastructure interacting with the issue tracker, areas like IRC bots, interwiki links, on-wiki templates, and automatic notifications in tasks about related patches in the code review system were dealed with or being worked on.

Paying attention to details: The “tracked” template on Wikimedia sites supports linking to tasks in Phabricator, while still redirecting links to Bugzilla tickets via URL redirects (see below).
We also had a chicken and egg problem to solve: Accounts versus tickets. Accounts in Bugzilla are defined by email addresses while accounts in Phabricator are user names. For weeks we were asking Bugzilla users and community users to already create an account in Phabricator and “claim” their Bugzilla accounts by entering the email address that they used in Bugzilla in their Phabricator account settings. The plan was to import the tickets and account ‘placeholders’ and then use cron jobs to connect the placeholder accounts with the actual users and to ‘claim’/connect their past Bugzilla contributions and activity by updating the imported data in Phabricator.
On October 23th, we made a separate “bugzillapreview” test instance available on Wikimedia Labs with thousands of Bugzilla tickets imported. For two weeks, the community was invited to check how Bugzilla tickets are going to look in Phabricator after the migration and to identify more potential issues. The input was helpful and valuable: We received 45 reports and fixed 25 of them (9 were duplicates, 2 invalid, and 9 got declined).
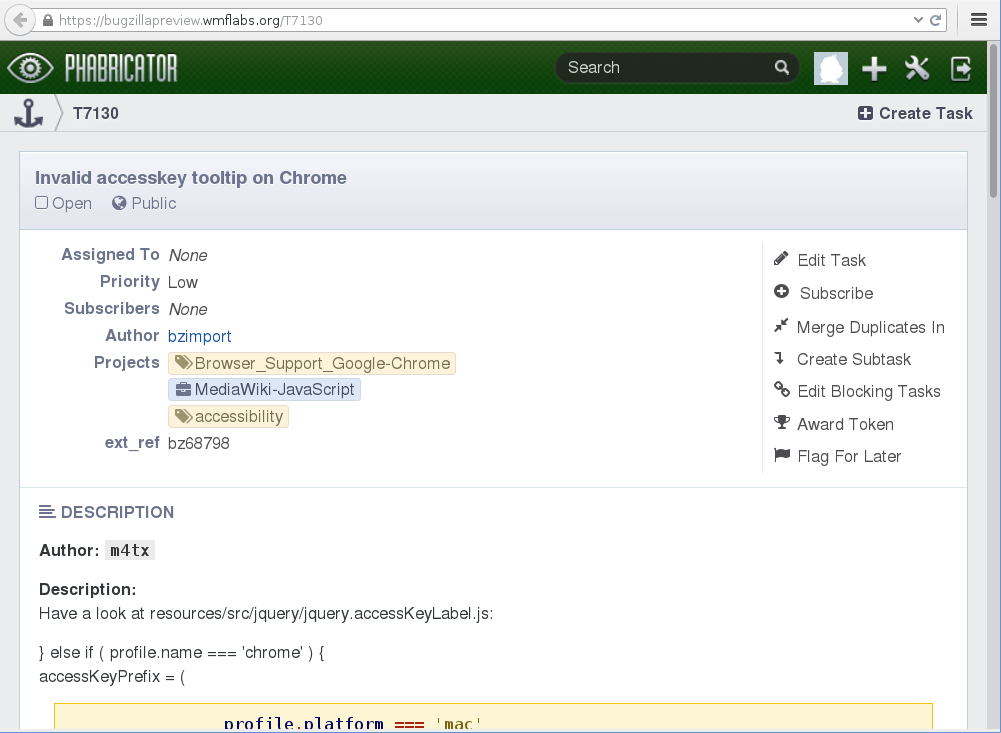
A task imported from Bugzilla in the Phabricator preview instance.
Having had reached a good overview, we created a consolidated list of known issues and potential regressions created by the migration from Bugzilla to Phabricator and defined a final date for the migration: November 21-23.
Keeping timestamps of comments intact (such as the original creation date of a ticket in Bugzilla or when a certain comment was made) was still something to sort out at this point (and got tackled). It would have been confusing and would have broken searches that triagers need when trying to clean up (e.g. tickets which have not seen updates for two years).
It was also tricky performance-wise to keep the linear numbering order of reports which was requested by many people to not solely depend on URL redirects from bugzilla.wikimedia.org to phabricator.wikimedia.org which we planned to set up (more information on the redirect setup). As we already had ~1400 tickets in Phabricator we went for the simple rule “report ID in Bugzilla + 2000 = task ID in Phabricator”.
Regarding documentation and communication, we created initial project creation guidelines, sent one email to those 66 users of personal tags in Bugzilla warning that tags will not be migrated, sent two emails to the 850 most recently active Bugzilla users asking them to log into Phabricator and provide their email address used in Bugzilla to claim their imported contributions as part of the migration already (for comparison, the average number of active users per month in Bugzilla was around 500+ for the last months), put migration announcement banners on mediawiki.org and every page on our Bugzilla, sent reminders to the wikitech-l, mediawiki-l, wikitech-ambassadors, and wmfall mailing lists.
After a last ‘Go versus No-Go’ meeting on November 12th, we set up the timeline with the list of steps to perform for the migration, ordered, with assignees defined for each task. This was mostly based on the remaining open dependencies of our planning task. We had two more IRC office hours on November 18 and 19 to answer questions regarding the migration and Phabricator itself.
While migrating, the team used a special X-Forwarded-For header to still be able to access Bugzilla and Phabricator via their browsers while normal users trying to access Phabricator or Bugzilla were redirected to a wikipage telling them what’s going on and where to escalate urgent issues (MediaWiki support desk or IRC) while no issue tracker is available. With aforementioned URL redirects in place we intended to move and keep Bugzilla available for a while under the new address old-bugzilla.wikimedia.org.
Migration
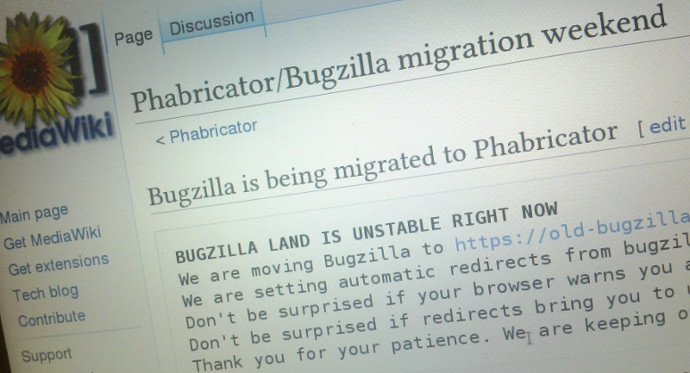
The page on mediawiki.org that users were redirected to while the migration was taking place.
The migration started by switching Bugzilla to read-only for good. Users can still log into Bugzilla (now available at old-bugzilla.wikimedia.org) and e.g. run their searched queries or access their list of votes on the outdated data but they cannot create or change any existing tickets.
We pulled phabricator.wikimedia.org and disabled its email interface, switched off the code review notification bot for Bugzilla, and switched off the scripts to sync Bugzilla tickets with Mingle and Trello.
The data migration started by applying a hack to workaround a Bugzilla XML-RPC API issue (see below), running the migration fetch script (tasks and comments), reverting the hack, running the migration create script (attachments), moving Bugzilla to old-bugzilla.wikimedia.org, starting the cron jobs to start assigning Bugzilla activity to Phabricator users by replacing the generic “bzimport” user by the actual corresponding users, and setting up redirects from bugzilla.wikimedia.org URLs.
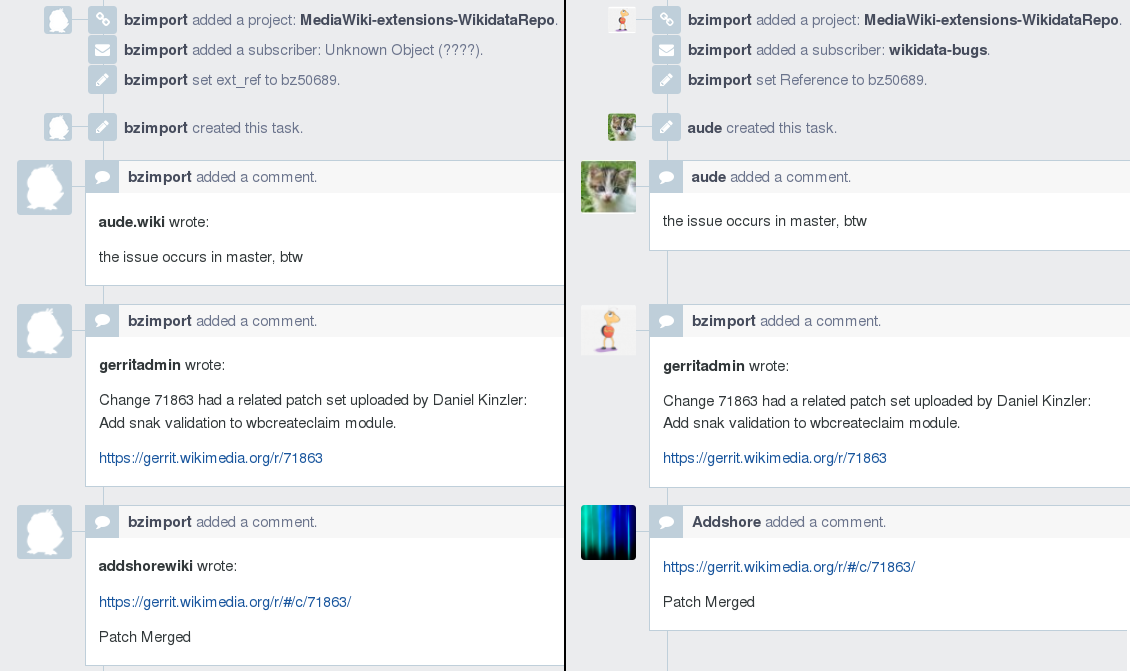
A task before and after users have claimed their previous Bugzilla accounts (positions of comments in the right image manually altered for better comparison).
After several of those data migration steps we performed numerous tests. In parallel we prepared emails and announcements to send out and publish once we’re finished, updated links to Bugzilla by Phabricator on dozens of wikipages, updating MediaWiki templates on the Wikimedia, and further small tasks.
Paying attention to details: The infobox template on MediaWiki extension homepages linking to the extension’s bug reports at the bottom, now handled in Phabricator instead of Bugzilla.
For those being curious about time spans: Fetching the 73681 Bugzilla tickets took ~5 hours, importing them ~25 hours, and claiming the imported user contributions of the single most active Bugzilla user took ~15 minutes.
But obviously we were pioneers that could not rely on Stackoverflow.
Even if you try to test everything, unexpected things happen while you are running the migration. I’m proud to say that we (well, rather Chase, Daniel, Mukunda and Sean when it came to dealing with code) managed to fix all of them. And while you try to plan everything, for such a complex move that nobody has tried before, there are things that you simply forget or have not thought about:
- We had to work around an unresolved upstream XML-RPC API bug in Bugzilla by applying a custom hack when exporting comments in a first step and removing the hack when exporting attachments (with binary data) in a second step. Though we did, it took us a while to realize that Bugzilla attachments imported into Phabricator were scrambled as the hack got still applied for unknown reasons (some caching?). Rebooting the Bugzilla server fixed the problem but we had to start from scratch with importing attachments.
- Though we had planned to move Bugzilla from bugzilla.wikimedia.org to old-bugzilla.wikimedia.org after exporting all data, we hadn’t realized that we would need a certificate for that new subdomain. For a short time we had an ugly “This website might be insecure” browser warning when users tried to access the old Bugzilla until old Bugzilla was moved behind the Varnish/nginx layer with its wildcard *.wikimedia.org certificate.
- Two Bugzilla statuses did not get converted into Phabricator tags. The code once worked when testing but broke again later at some point without anybody realizing but this was noticed and fixed.
- Bugzilla comments marked as private got public again once the cron jobs claiming contributions of that commenter were run. Again this was noticed and fixed.
- We ended up with a huge feed queue and search indexing queue. We killed the feed daemon at some point. Realizing that it would have taken Phabricator’s daemons ~10 days to handle the queue, Chase and Mukunda debugged the problem together with upstream’s Evan and found a way to improve the SQL performance drastically.
- We hadn’t thought about switching off some Bugzilla related cronjobs (minor) and I hadn’t switched off mail notifications from Bugzilla so some users still received "whining" emails until we stopped that.
- We had a race condition in the migration code which did not always set the assignee of a Bugzilla ticket also as the assignee of the corresponding task in Phabricator. We realized early enough by comparing the numbers of assigned tickets for specific users and fixed the problem.
- I hadn’t tested that aliases of Bugzilla reports actually get migrated. As this only affected ~120 tickets we decided to not try to fix this retroactively.
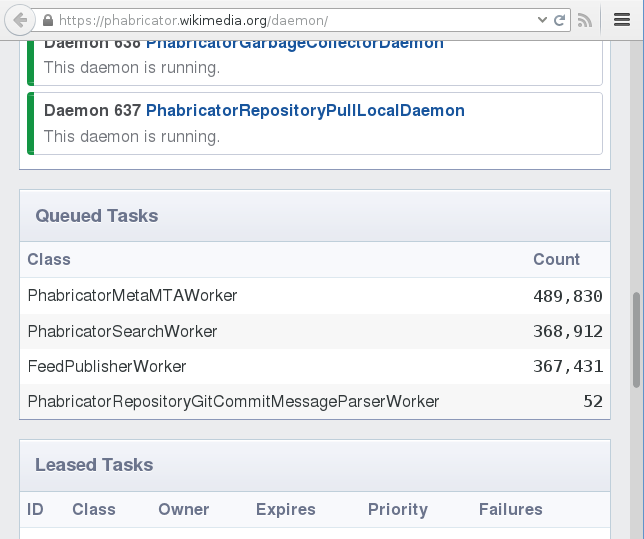
Phabricator daemons being (too) busy handling the tasks mass-imported from Bugzilla.
We silently reopened Phabricator on late Sunday evening (UTC) and announced its availability on Monday morning (UTC) to the wikitech-l community and via the aforementioned blogpost.
Advantages
Phabricator has many advantages compared to Bugzilla: Wikimedia users do not reveal their email addresses and users do not have another separate login and password. (These were the most popular complaints about Bugzilla.)
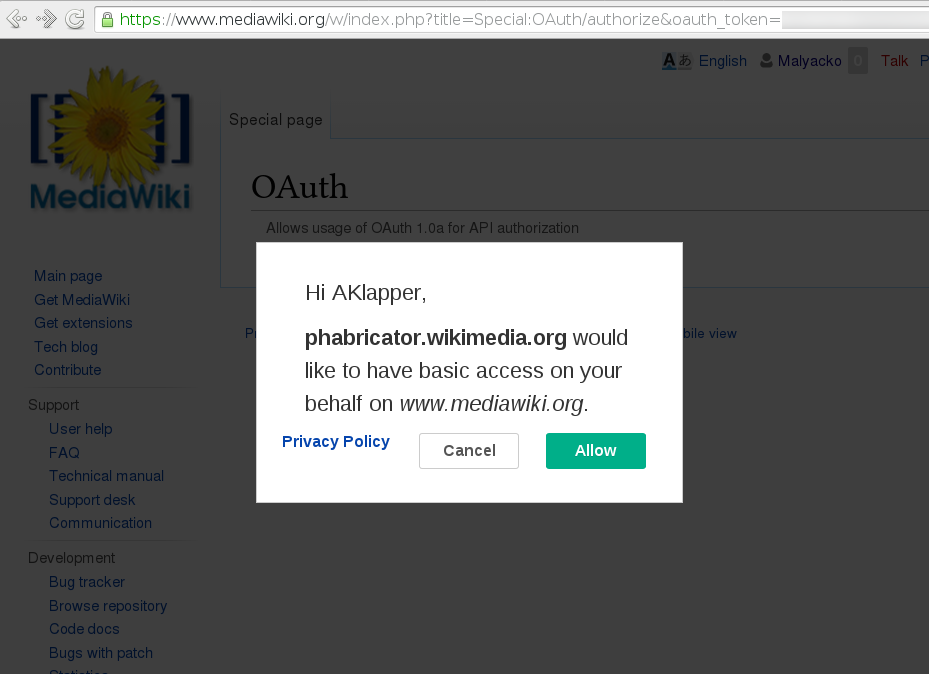
Integration with MediaWiki’s Single User Login via OAuth – no separate login.
There is a preview when writing comments.
The initial description can be edited and updated like a summary while the discussion on a task evolves.
Users have a profile showing their latest activity.
There’s a global activity feed.
There is a notification panel on top.
The UI looks modern and works pretty well on devices with small screens.
Tasks can have either zero or one assignee. In Bugzilla an assignee must be set even if nobody plans to work on a ticket.
Tasks can have between zero and unlimited projects (such as code bases, sprints, releases, cross-project tags) associated. In Bugzilla, tickets must have exactly one product, exactly one component, exactly one target milestone, and between zero and unlimited cross-project keywords. That also solves Bugzilla’s problem of dealing with branches, e.g. setting several target milestones.
Projects have workboards (a card wall) with columns for planning sprints (Bugzilla only allowed getting lists of items which you cannot directly interact with from the list view.). Thanks to Wikimedia Deutschland we now also have burndown charts for sprint projects.

The workboard of the Wikimedia Phabricator project, right after the Bugzilla migration.
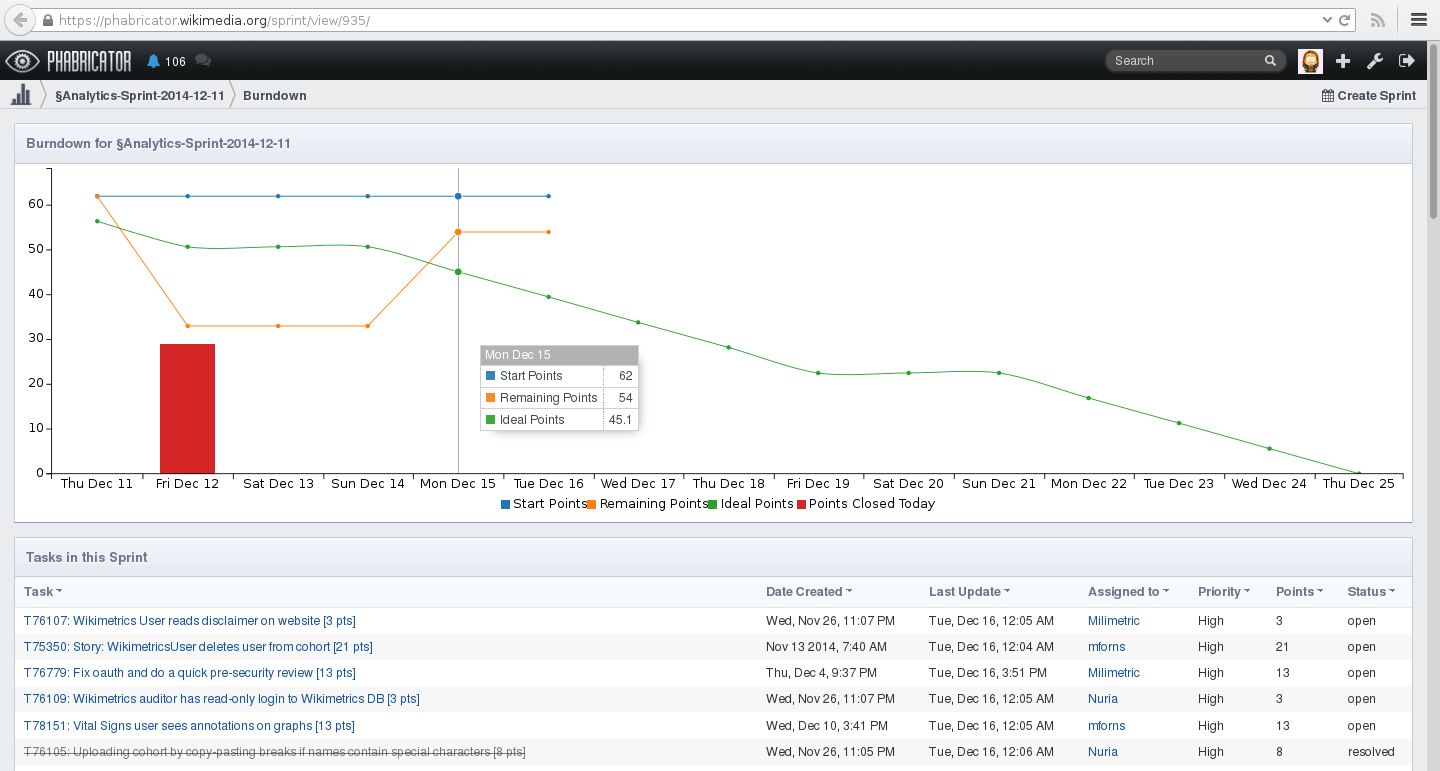
Burndown chart for a two week sprint of the Wikimedia Analytics team.
Disadvantages
From a bugmaster point of view there are also small disadvantages:
Some searches are not possible anymore via the web interface, e.g. searching for open tasks which have the same assignee set for more than 12 months ("cookie-licking") or tasks that have been closed within the last month.
Phabricator is more atomic when it comes to actions: I receive more mail notifications and it also takes me slightly longer to perform several steps in a single ticket (though my local Greasemonkey script saves me a little bit of time).
Furthermore, admins don’t have the same powers as in Bugzilla. The UI feels very clean though (breadcrumbs!):
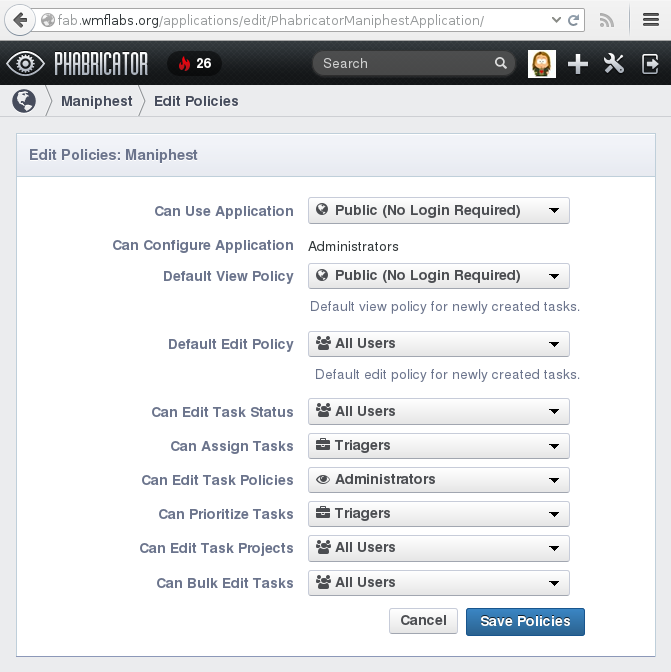
Administrator view for settings policies in Phabricator.
New territories
Apart from the previous list of unexpected situations while migrating, there were also further issues we experienced before or after the migration.
Mass-importing huge amounts of data from an external system into Phabricator was new territory. For example, Phabricator initially had no API to create new projects or to import tickets from other systems. No Phabricator instance with >70000 tasks had existed before – before the migration we had a crash affecting anonymous users and after the migration the reports/statistics functionality became inaccessible (timing out). Those Phabricator issues were quickly fixed by upstream.
And of course in hindsight, there are always a few more things that you would have approached differently.
Next steps
All in all and so far, things work surprisingly well.
We are still consolidating good practices and guidelines for project management (we had a Hangout video session on December 11th about that), I’ve shared some queries helpful for triagers, and we keep improving our Phabricator and bug management related help and documentation. The workflow offered by Phabricator also creates interesting new questions to discuss. Just one example: When a task has several code related projects assigned that belong to different teams, who decides on the priority level of the task?
Next on the list is to replace RT (mostly used by the Operations team) and helping teams to migrate from Trello and Mingle (Language Engineering, Multimedia and parts of Analytics have already succeeded). In 2015 we plan to migrate code repository browsing from gitblit and code review from Gerrit.
OMG we made it
A huge huge thanks to my team: Chase (Operations), Mukunda (Platform), Quim (Engineering Community Team), the many people who contributed code or helped out (Christopher, Daniel, Sean, Valhallasw, Yuvi, and more that I’ve likely forgotten), and the even more people who provided input and opinions (developers, product managers, release management, triagers, bug reporters, …) leading to decisions.
I can only repeat that the upstream Phabricator team (especially Evan) have been extremely responsive and helpful by providing feedback incredibly fast, fixing many of our requests and being available when we ran into problems we could not easily solve ourselves.
Cheers!

Congratulations!
Pingback: 2014 that was. « andré klapper's blog.