With the advent of immutable/re-provisional/read-only operating systems like Fedora’s Silverblue, people will be doing a lot more computing inside of containers on their desktops (as if they’re not already).
When you want to profile an entire system with tools like perf this can be problematic because the files that are mapped into memory could be coming from strange places like FUSE. In particular, fuse-overlayfs.
There doesn’t seem to be a good way to decode all this indirection which means in Sysprof, we’ve had broken ELF symbol decoding for your things running inside of podman containers (such as Fedora’s toolbox). For those of us who have to develop inside those containers, that can really be a drag.
The problem at the core is that Sysprof (and presumably other perf-based tooling) would think a file was mapped from somewhere like /usr/lib64/libglib-2.0.so according to the /proc/$pid/maps. Usually we translate that using /proc/$pid/mountinfo to the real mount or subvolume. But if fuse-overlayfs is in the picture, you don’t get any insight into that. When symbols are decoded, it looks at the host’s /usr/lib/libglib-2.0.so and finds an inode mismatch at which point it will stop trying to decode the instruction address.
But since we still have a limited number of container technologies to deal with today, we can just cheat. If we look at /proc/$pid/cgroup we can extract the libpod container identifier and use that to peek at ~/.local/share/containers/storage/overlay-containers/containers.json to get the overlayfs layer. With that, we can find the actual root for the container which might be something like ~/.local/share/containers/storage/overlay/$layer/diff.
It’s a nasty amount of indirection, and it’s brittle because it only works for the current user, but at least it means we can keep improving GNOME even if we have to do development in containers.
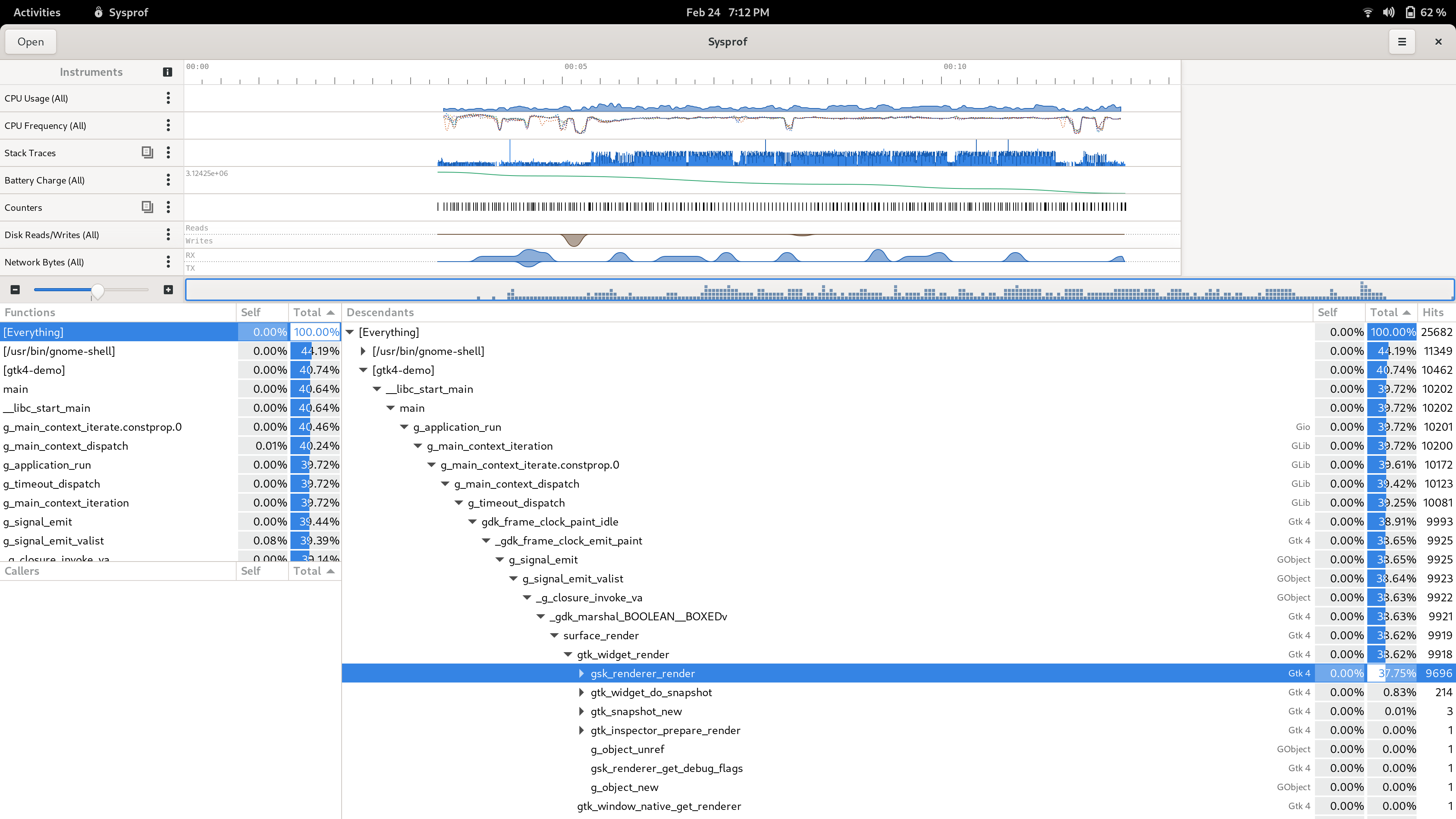
Obligatory screenshot of turtles. gtk4-demo running in jhbuild running in Fedora toolbox (podman) with a Fedora 34 image which uses fuse-overlayfs for file access within the container. Sysprof now can discover this and decode symbols appropriately alongside the rest of the system. Now if only we could get distributions to give up on omitting frame pointers everywhere just so their unjustifiable database benchmarks go up and to the right a pixel.