So now that you are all aware that I’ve been working to modernize Sysprof, you might not be surprised to read that I decided to push things in a bit more interesting of a direction.
I have a very opinionated stance on languages. Which is, in general, they’re all terrible. Only to be made more terrible by their implementations. Which is to say, we’re all screwed and how do these computers work anyway?
But alas, succumbing to the numbness of existence is not how I want to spend my life, so time to pull up my figurative bootstraps and improve what we’ve got.
So what’s in my cross-hairs this week? Well, quite frankly, those JavaScripts. I’ve worked on a handful of language runtimes, but modern JavaScript engines really take the cake for turning a Von Neumann machine into something completely foreign and utterly non-debuggable, non-profile-able, generally unpleasant for anyone to come in and improve things other than the original author. (Same could be said about C. But wait, I said I *wasn’t* succumbing to the numbness).
Well, that isn’t completely true, given that you only write JavaScript within the context of a browser. The tooling in browsers these days is rapidly approaching something useful. Which is saying a lot when you have a language that is almost exclusively using nameless functions attached to prototype fields.
So here we go, off into the land of mystery. libmozjs24 is our path, with only headers and a few sources to guide us.
So how do profilers work anyway?
Lets simplify this to a static C-like language for the moment.
Say your program is happily running along, maybe processing things from a main loop. Along comes a signal from the kernel. The kernel decides it will deliver the signal to your main thread (see man pthread_sigmask for information on how signals are delivered and how to block them). What happens next is that on top of your current executing stack, your registered signal handler (see man sigaction) is executed.
At this point, you can do a couple of things. Generally, you might use something like libunwind to unwind the stack (past your signal handler) and record each of the instruction pointers for each frame. Using that, you can later look at what library was mapped into the region containing the instruction pointer, and resolve the function name by reading the library ELF (and possibly demangling if it is a C++ function).
If you remember your UNIX handbook, the way to spawn a process (simplified) is to fork(), followed by an exec() of the new process. So how do we get our signal handler into that process?
POSIX timers
In the 2008 version of POSIX, timers were introduced (See man timer_create for more information). They allow you to deliver a signal on an registered interval. Even better, POSIX timers follow through exec but not fork. Exactly what we want. We can fork(), setup the timer, and then exec() our target.
It looks something like this:
[code lang=”c”]
struct sigevent sev = { 0 };
sev.sigev_signo = SIGPROF; /* Send us SIGPROF */
sev.sigev_notify = SIGEV_THREAD_ID; /* Linux extension! */
sev._sigev_un._tid = syscall (__NR_gettid); /* See man gettid */
timer_create (CLOCK_MONOTONIC, &sev, &timer);
[/code]
The above code creates a timer that we can enable/disable to deliver SIGPROF on a given interval. Note that the above code uses a Linux extension that allows you to specify the thread to receive the signal. Without something like that, you would need to either create a thread to use pthread_kill() to send SIGPROF, or mask SIGPROF from all other threads, lest they receive the signal handler instead of your target thread.
So why is the thread that the profiler runs on important? We’ll get to that later when we start looking at JITd languages.
To activate the timer, we setup our interval (frequency) to sample.
[code lang=”c”]
struct itimerspec its = { 0 };
its.it_interval.tv_sec = 0;
its.it_interval.tv_nsec = NSEC_PER_SEC / SAMPLES_PER_SEC;
its.it_value.tv_sec = 0;
its.it_value.tv_nsec = NSEC_PER_SEC / SAMPLES_PER_SEC;
timer_settime (self->timer, 0, &its, &old_its);
[/code]
Extracting Samples
Now say we used sigaction(2) to setup a signal handler for SIGPROF. And now it is being called via signal delivery of SIGPROF. Our stack might look something like:
[code lang=”c”]
our_sigprof_handler()
< signal handler invoked >
some_worker()
main_loop_dispatch()
main_loop_iterate()
main()
[/code]
We can unwind to get to the root of the stack, stash each of those addresses somewhere, and then return from our signal handler (allowing the program to continue executing).
However, the devils in the details there. We are in a signal handler, which basically means, you can’t do much, safely. Why? Well avoiding deadlocks mostly.
Say that SIGPROF got delivered while you were in malloc()? It might look something like:
[code lang=”c”]
our_sigprof_handler()
< signal handler invoked >
do_alloc()
_int_lock()
malloc()
some_worker()
main_loop_dispatch()
main_loop_iterate()
main()
[/code]
Now, if you try to call malloc(), you’ll deadlock on _int_lock(). Basically, the only thing you can do is write to some memory you have pre-allocated. Buffer space, if you will.
Thankfully, you can do one more thing, which is write() to a file-descriptor. That is handy in case our buffer gets too full.
But you need to be very careful here. Even things like g_assert() could potentially cause a printf() or similar which might internally malloc. So you might need to -DG_DISABLE_ASSERT for production (which you should be doing anyway).
The complexities of a JIT
JITs truly are the magic of our times. They are the meta of the computer to improve itself faster than we can. That said, like your smart friends, they can be super annoying.
Discussing what a JIT is, the added complexity of tracing JITs, and their almost always pairing with garbage collection is out of scope for this. However, there are some excellent implementations you can go read (See mono as one such example of quality engineering).
In this case, the meaning of an address (the function in question, to say) could be the same between two samples, but be part of two completely different functions. Suppose that the JIT regenerated and reused the existing memory.
If you simply went by the address and did not account for the change, then you’d get wildly inaccurate results.
How SPSProfiler comes to the rescue
Thankfully, this work was building on top of SPSProfiler from libmozjs. While we have to provide our own sampler (which we’ve described the basics of above), it provides the necessary JIT integration in a moderately fast manner.
js::ProfileEntry
What mozjs gives us is a way to ask the runtime to deliver the current JS stack into a static buffer that we can read from. Each time JS dives into or out of a function, that “shadow stack” is updated.
However, since libmozjs has a garbage collector, if we were to access this stack information from any other thread, we’d be racing the GCing of strings pointed to by that shadow stack. So we need to ensure we interrupt the executing stack (hence SIGPROF, timers, etc).
Racing with a GC doesn’t matter in a C like language because, well there is no GC, and we can resolve symbol names after the fact because of ELF and DWARF debug information.
[code lang=”c”]
volatile uint32_t stack_depth = 0;
js::ProfileEntry stack[1024];
js::SetRuntimeProfilingStack (js_runtime,
stack,
&stack_depth,
G_N_ELEMENTS (stack));
js::EnableRuntimeProfilingStack (self->runtime, true);
[/code]
Deduplicating Functions
To get the function name for JavaScript functions, we can simply read the string pointed to by the js::ProfileEntry. Something like:
[code lang=”c”]
if (entry->js()) {
const gchar *name = entry->label() ?: "– javascript –"
}
[/code]
Now, if we had to copy that string for every instruction pointer in the stack, on every sample, we’d have pretty significant overhead in our profiler. So we do a bit of a deduplication hack. We have something that looks like a chunked allocator (GStringChunk) except it can’t be an allocator, because oh wait, in a signal handler.
So instead, we just have a fixed buffer size to store a single instance of the string, and a closed hashtable (no allocations required) to help with our deduplication.
While we fill the deduplicated function buffer, we hand out monotonic address identifiers for each new string. We steal some high bits in the address to indicate that this is a JITd function. (0xE << __wordsize-8). Normally this would colide with kernel addresses, but not in practice.
So now we can just replace our JITd addresses with these and store them like we would normally for C-like stacks.
What’s missing?
While SPSProfiler will put JS information (including native code) for functions before the current JavaScript frame, it doesn’t seem to give info after the current JS frame. So if your JS code calls into C code, which doesn’t result in a callback back into JavaScript code, getting reliable stack addresses is non-trivial. Maybe I’m missing something here though.
I need to go read some more code, because I’m likely to believe there is a way to deal with this, but might require newer libmozjs. Anyway, future blog post and all.
Capture formats
My new sysprof implementation uses a new binary capture format I’ve put together. Basically something really simple that lets me get data into the buffer quickly without too much fuss, alignment safe (allowing dereference of integers from the buffer with out use of memcpy()) and without the super annoying reality of Linux’s perf event stream which has dynamic trailing data based on what options were enabled when sampling. Seriously, don’t do that.
I still have some things to add, but this is the first step towards making more interesting captures (like in-app performance counters, VBlank information, compositor FPS, GTK+ frame timings, etc).
So what does that even mean?
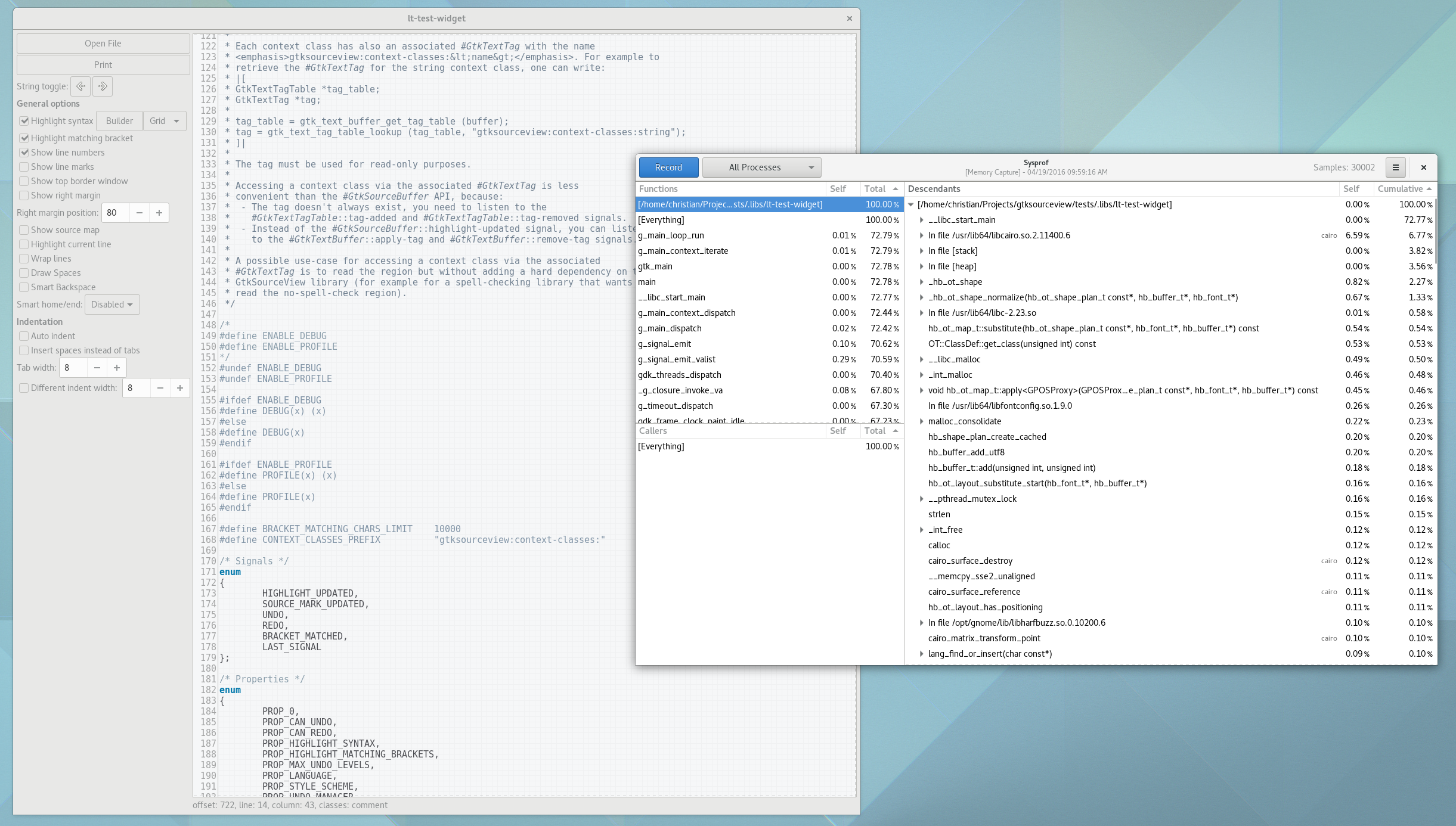
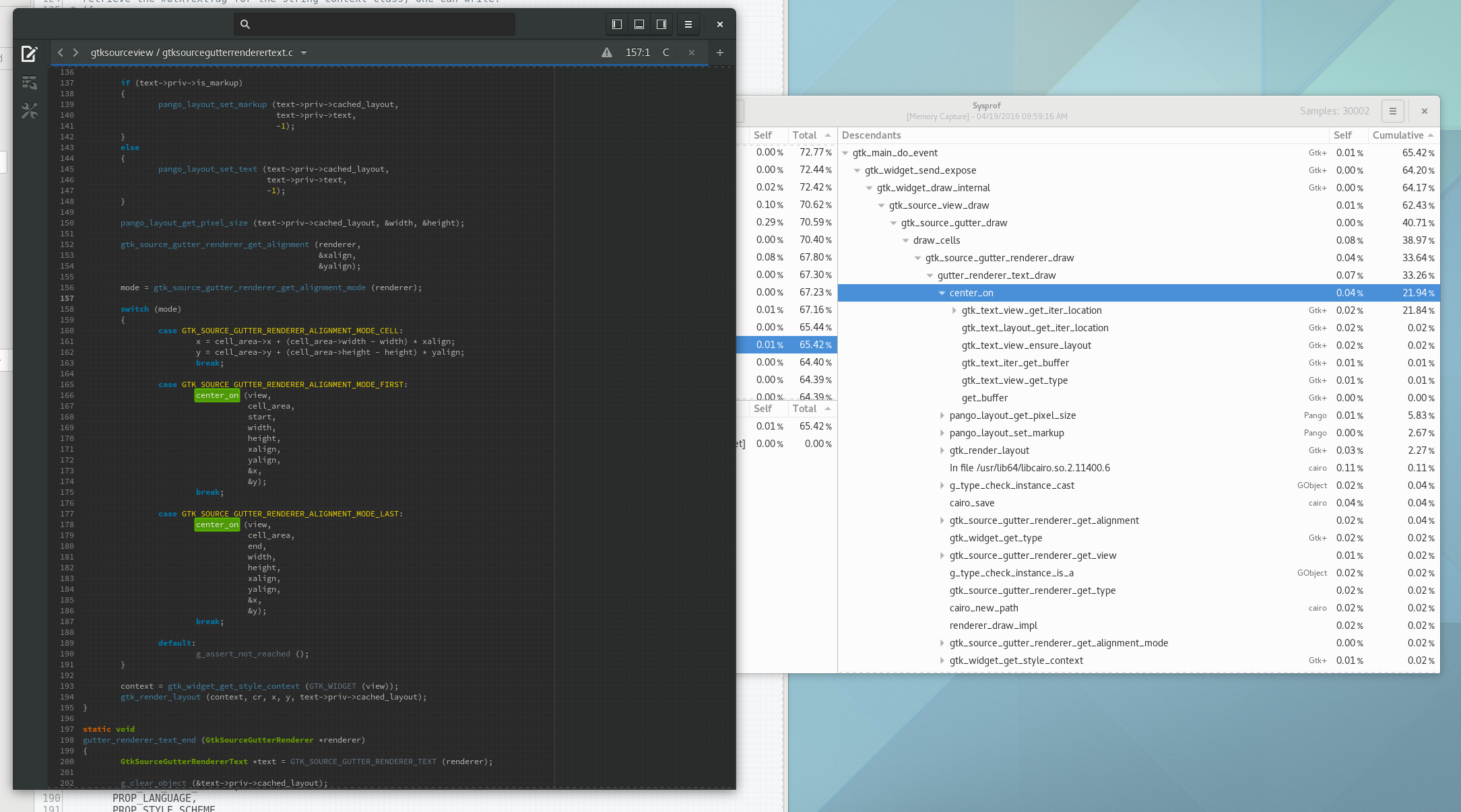
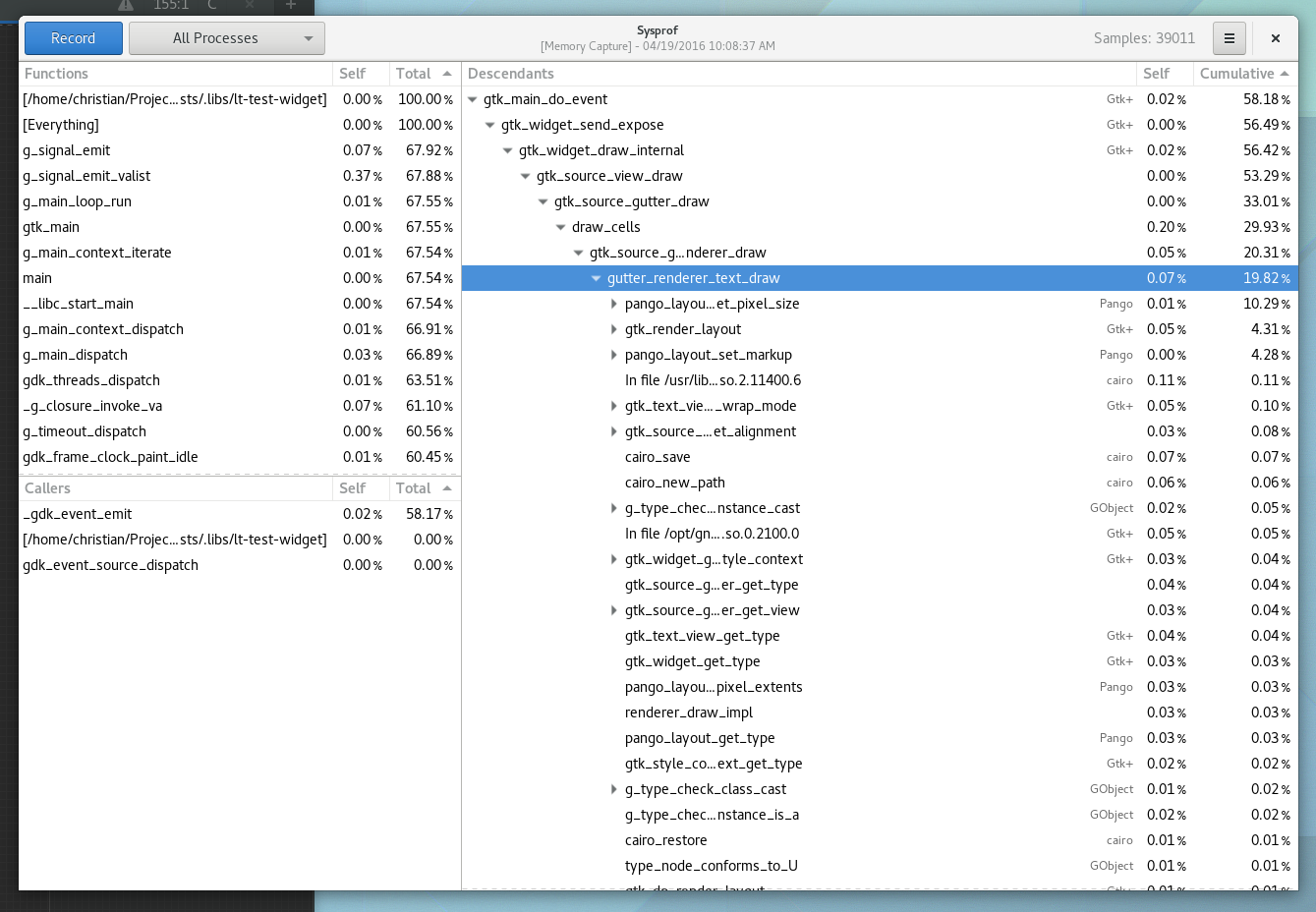
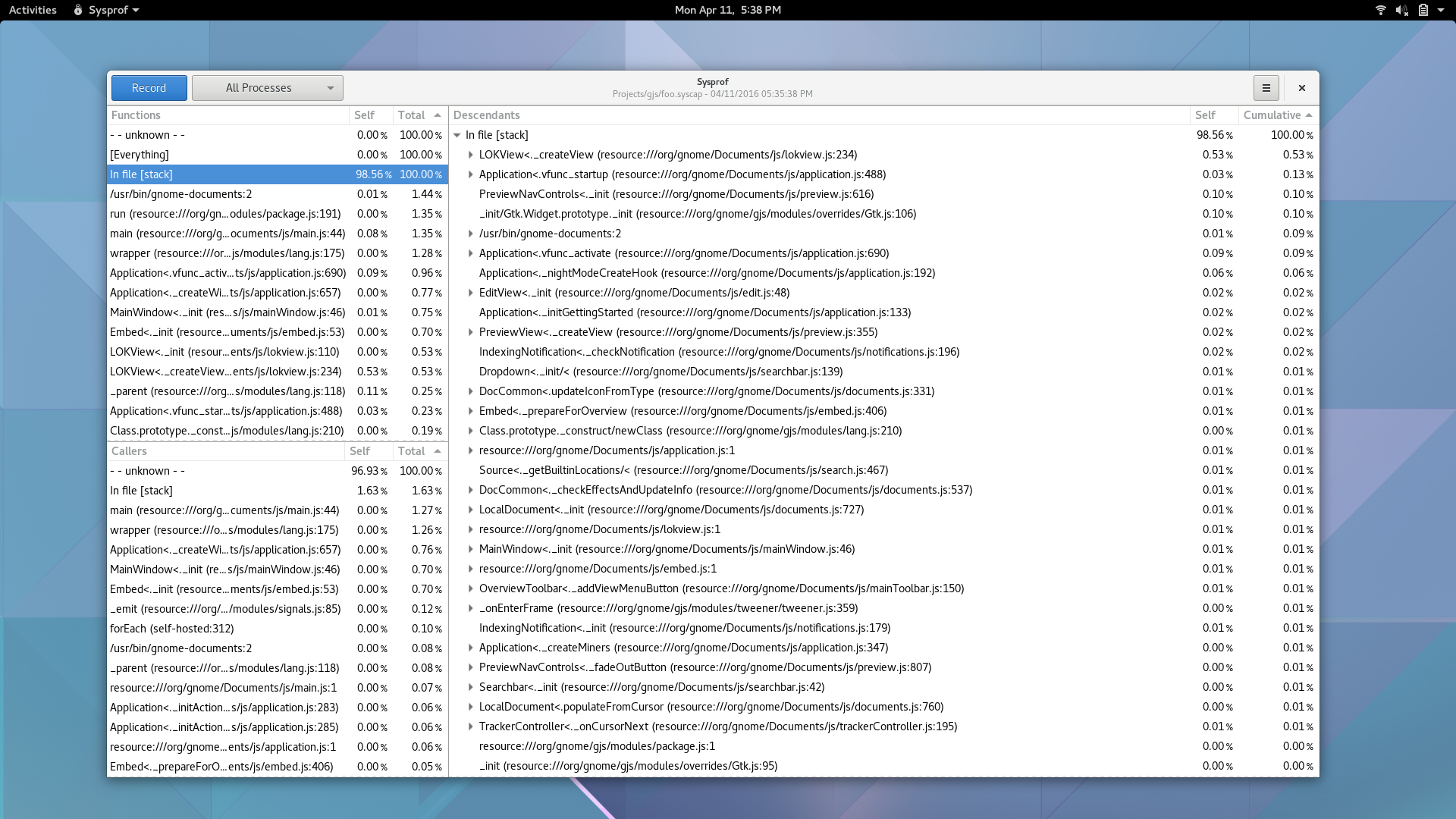
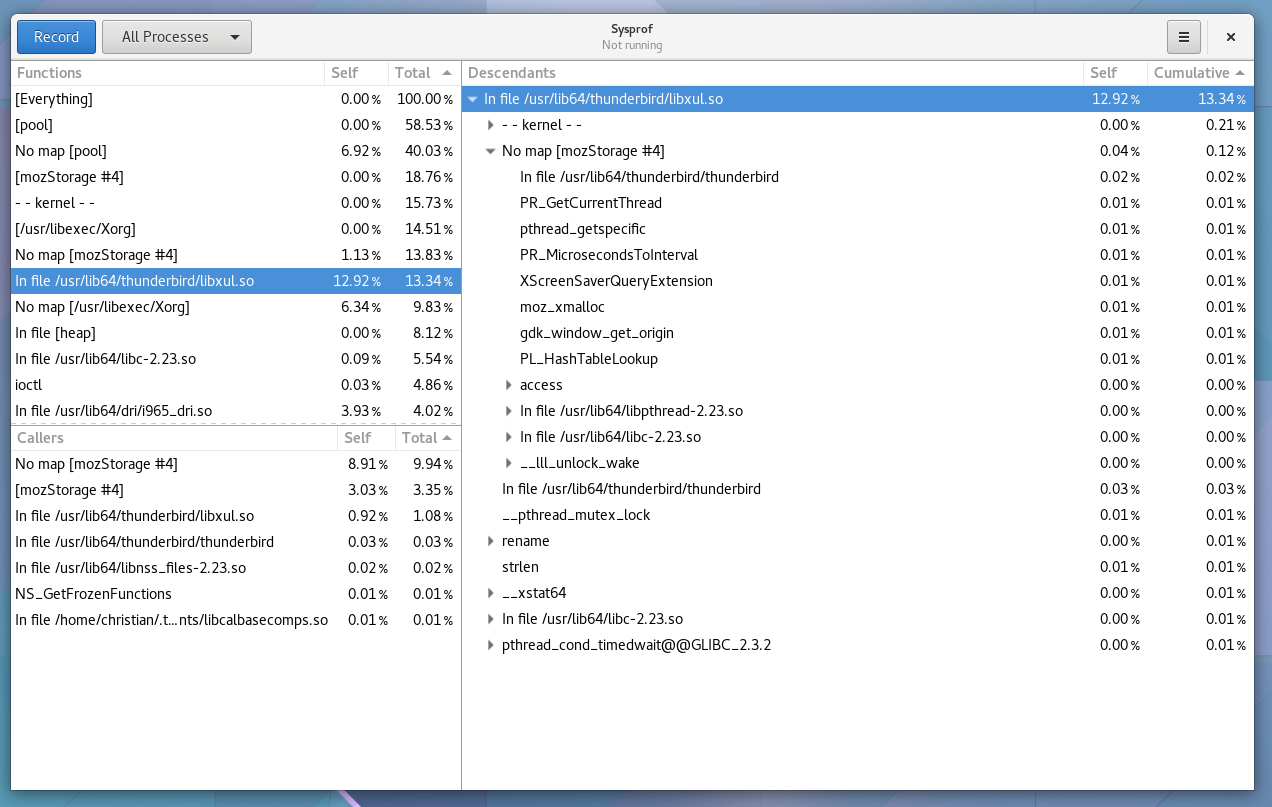
Well, I guess you can see for yourself. Here is a simple capture I did to pick on GNOME documents (no reason really, just the first JavaScript/C hybrid app that came to mind) showing Sysprof reading our JavaScript profiler output.
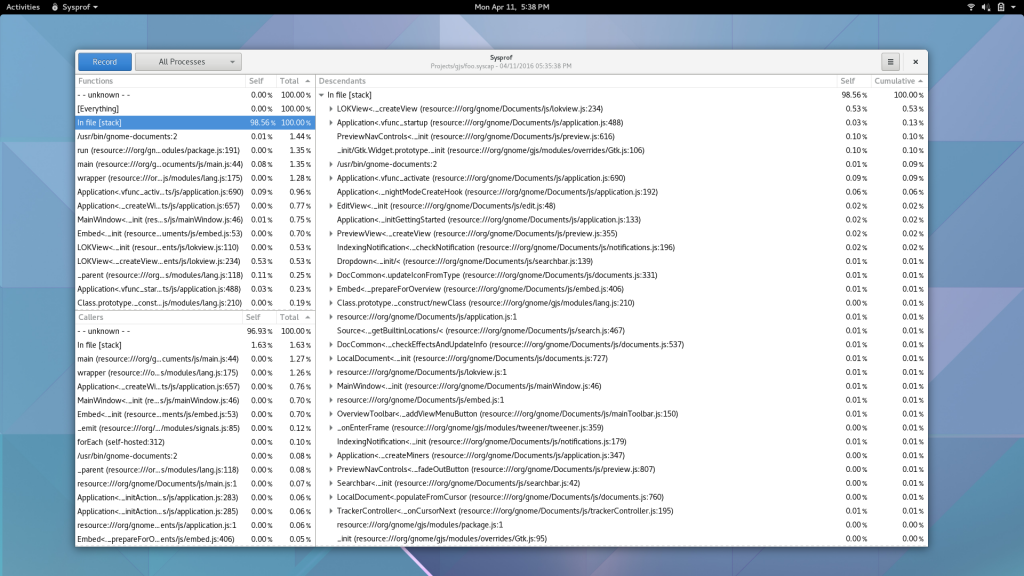
There is still some work to be done. I need to get the Gjs patches in a format suitable for inclusion. That means fixing up some boring signal handler code to be more safe. Ray Strode has already provided some good feedback here.
Additionally, I need to get my sysprof2 repository grafted into upstream Sysprof. This week I swear. We also need to get patches into some programs that use libgjs directly without the use of gjs-console so that they too can be profiled. gnome-shell is the obvious culprit here.
Come hack on Sysprof with me? Please?
If any of this interests you, I’d love to have some people come help work on modernizing Sysprof into something we all love. It’s still missing one thing I loved while working on PerfKit years ago. Pretty graphs and charts of runtime information. We can start sampling cpu, memory, network, kms/drm information, and more. With that data available, we can build some pretty compelling tooling for GNOME and GNU/Linux in general. (BSDs obviously too, but today Sysprof is Linux only due to the Linux kernel integration).
No doubt, there are gaps and missing information in this blog post. It’s hard to capture all the details after you do the work. For the nitty-gritty details, best to go look at the code.
- https://github.com/chergert/sysprof2
- https://github.com/chergert/gjs
- Build/install the code above.
- gjs-console --profile-output=foo.syscap /usr/bin/gnome-documents
- You might need to let it exit gracefully, I don’t have periodic sample flushes implemented yet.
- sysprof foo.capture
- Explore!
Thanks to Red Hat for letting me dive head first into this. They really are the best employer I’ve ever had.