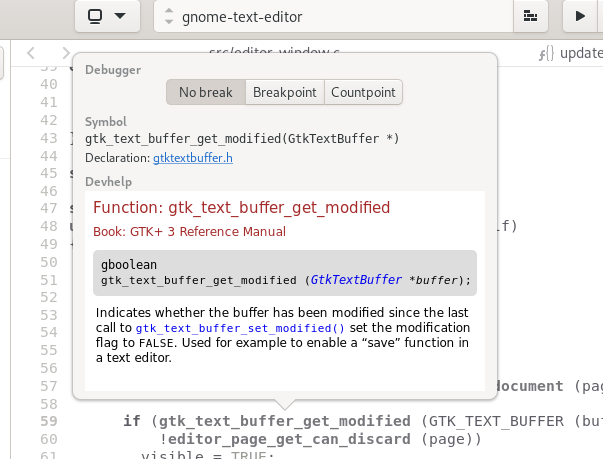
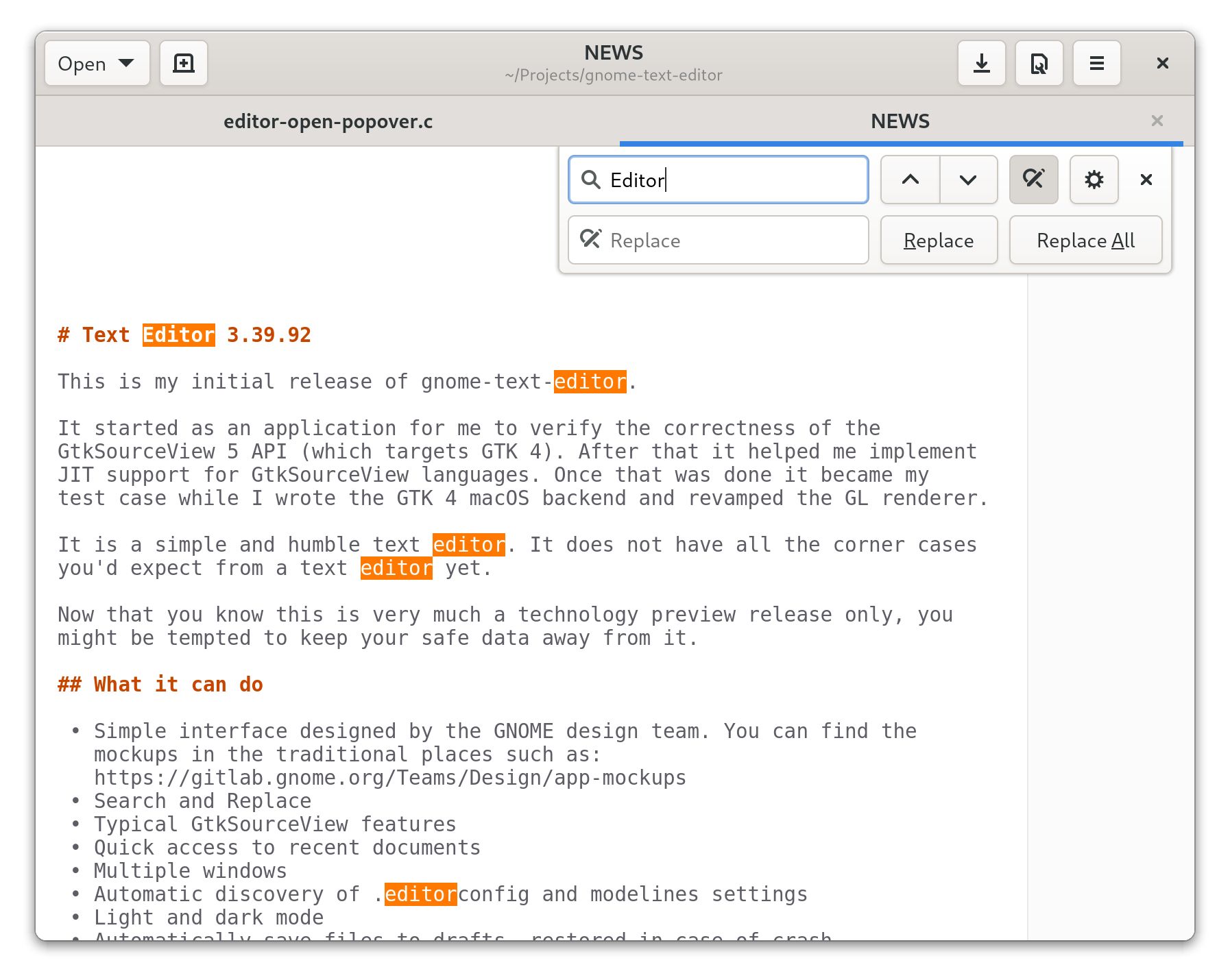
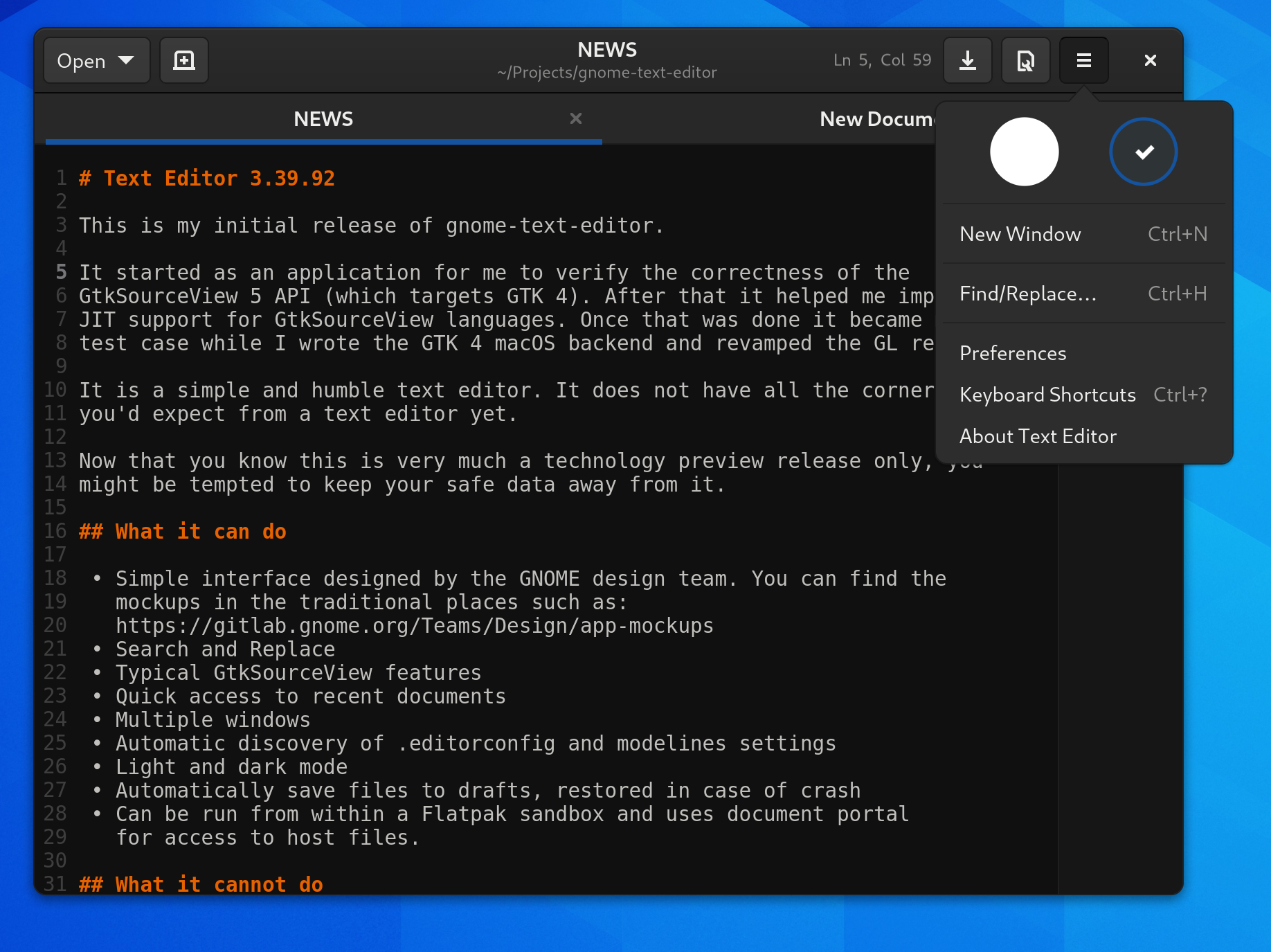
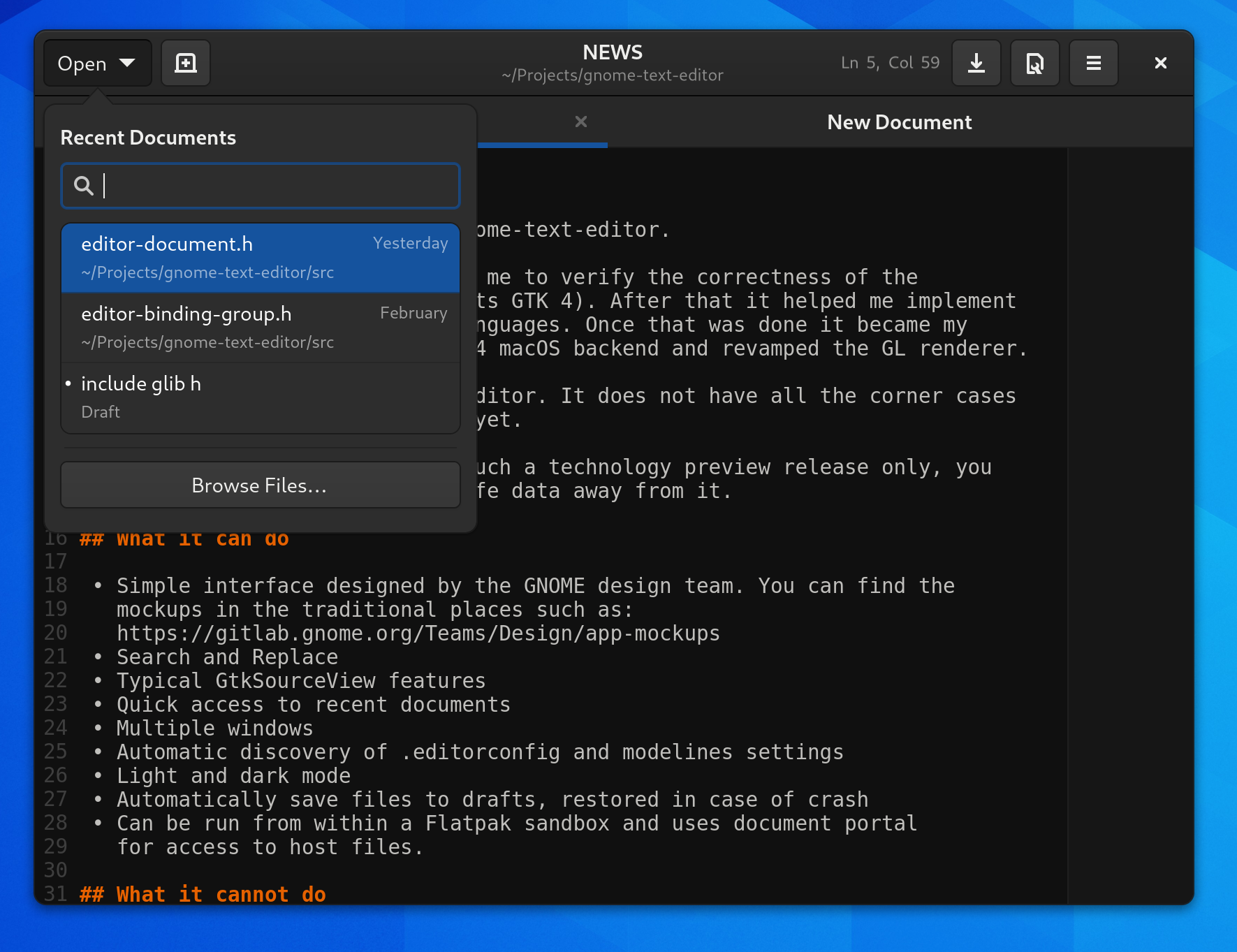
I realize I don’t blog much these days, but I do try to keep my Twitter filled with screenshots as I work on GNOME.
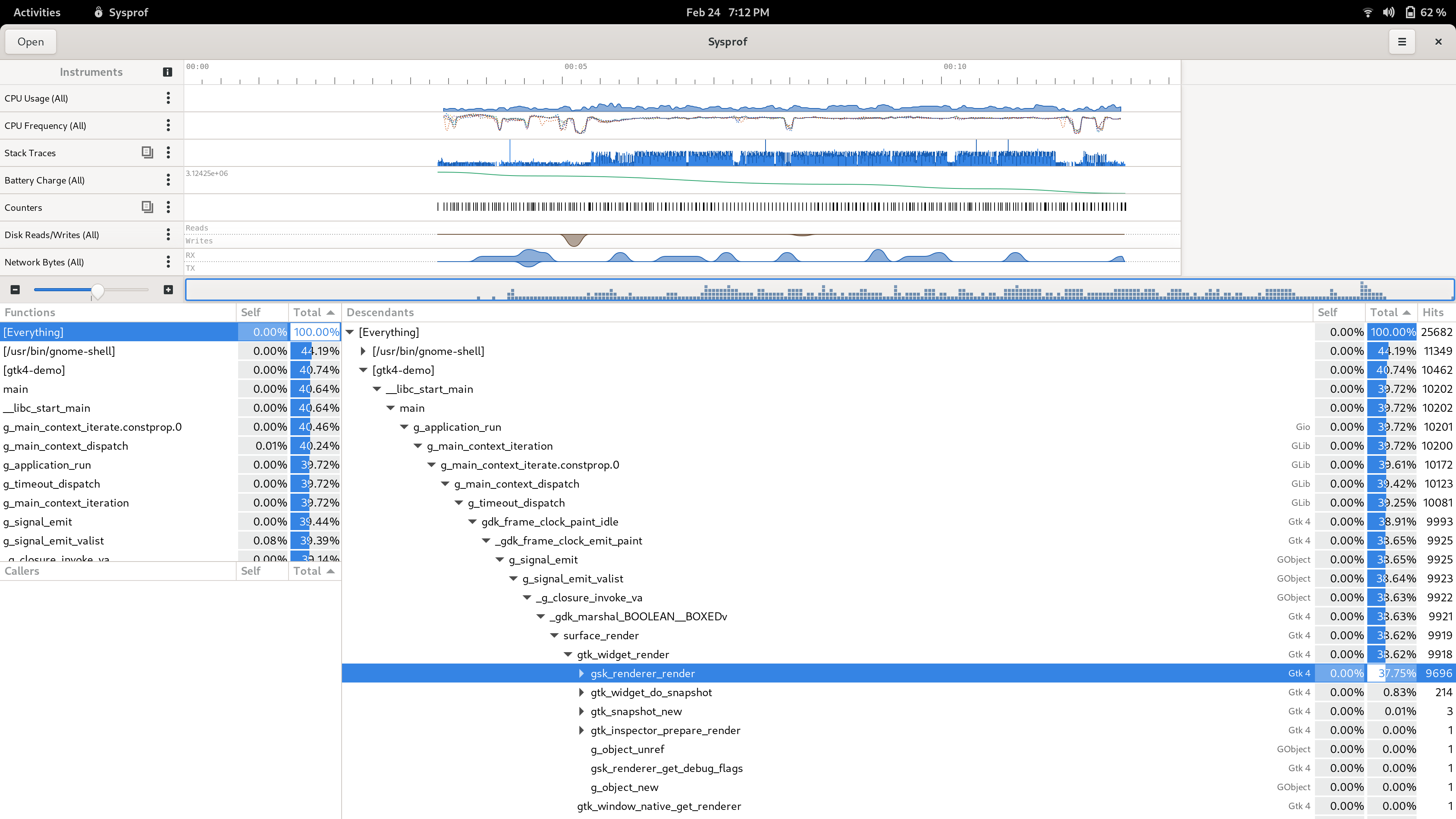
Recently I spent some time doing another round of performance improvements in GtkSourceView.
Much work this cycle has focused on submitting work to the GPU more efficiently. For example, Matthias Clasen taught the new OpenGL renderer to submit colors along with glyph vertices so that it could have fewer GL uniform updates along with fewer program switches. This has had the effect of letting us batch common GtkTextView usage into a single glDrawArrays() submission. Great stuff!
I’ve been striving to reach 144hz text scrolling ever since a kind GNOME contributor sent me a 144hz monitor to test with. So with the new bits in place, I took another look at what was slowing us down.
Line Number Drawing
Line number drawing was still pretty high on the list. We already did some performance work there to avoid generating line number strings using a technique that caches a bit of information to tweak a single character in a static buffer. This time, however, the slowdown is in measuring text in Pango.
A quick dive into the code reveals that we have to measure the text to right-align line numbers. Since this is expected to be monospace we can cache common text widths and only measure once in a while. Simple and done.
Right Margin Drawing
Next up was a bit more trickier, in that it involved a lucky guess on my part. Taking a quick look at GtkSourceView’s snapshot_layer() implementation I noticed that the right margin is drawn above the text layer. That ultimately means that we must be doing an alpha composite when drawing. That both perturbs the quality of text beneath it and is more complex to draw.
When possible, the new code pre-calculates the blend between the background and the right-margin color to get the would-be composited color. That allows us to draw it beneath the text without an alpha channel and avoid the fairly large alpha composite altogether.
Other Changes
- I also spent some time cleaning up how event handling works with GtkSourceMap (our minimap). It should feel quite a bit smoother and natural now. Thankfully this is a lot easier in GTK 4 than it was previously.
- In GTK 4, I added new API to get access to the
PangoContextso that we could control glyph alignment in GtksourceView. This makes our “Block” font in the GtkSourceMap look a bit better now. - To keep the GtkourceMap from being too distracting, we also tweak the default foreground color a bit so that it has less oomph than your actual GtkSourceView.
- If you set a
left-marginon a GtkSourceMap it will also now try to center your map which makes it easier for applications to provide some padding for improved aesthetics. - Now that Adwaita uses transparency for selections, the Adwaita style scheme needed to copy that.
Test It Out!
You can test it out with Flatpak using Nightly builds of Text Editor with org.gnome.TextEditor.Devel.flatpakref.